400+ Câu hỏi luyện thi chứng chỉ AWS Certified Solutions Architect Associate (SAA-C03) - Phần 7
aws
aws certification
cloud computing
solutions architect
saa c03
aws exam
practice test
Question 1
You work as an architect for a consulting company. The consulting company normally creates the same
set of resources for their clients. They want some way of building templates, which can then be used
to deploy the resources to the AWS accounts for the various clients. Also, your team needs to be
ensured that they have control over the infrastructure. Which of the following service can help
fulfill this requirement?
A.
AWS Elastic Beanstalk
B.
Custom AMI
C.
AWS Cloudformation
D.
EBS Snapshots
Answer – C
The AWS Documentation mentions the following.
AWS CloudFormation is a service that helps you model and set up your Amazon Web Services resources
so that you can spend less time managing those resources and more time focusing on your applications
that run in AWS. You create a template that describes all the AWS resources you want (like Amazon
EC2 instances or Amazon RDS DB instances). AWS CloudFormation takes care of provisioning and
configuring those resources for you.
Elastic Beanstalk is intended to make developers' lives easier. CloudFormation is intended to make
systems engineers' lives easier.
Elastic Beanstalk is a PaaS layer on top of AWS's IaaS services which abstracts away the underlying
EC2 instances, Elastic Load Balancers, Auto Scaling groups, etc. This makes it a lot easier for
developers, who don't want to deal with all the systems stuff, to get their application quickly
deployed on AWS. With Elastic Beanstalk, you don't need to understand how any of the underlying
magic works.
CloudFormation, on the other hand, doesn't automatically do anything. It's simply a way to define
all the resources needed for deployment in a huge JSON file.
- Option A could be a valid choice. But it has been clearly asked in question that the team needs to
have control over the infrastructure.
- Option B is invalid because Custom AMI will help create an Image for EC2 Instances, not for all
the resources.
- Option D is invalid because EBS Snapshot is a copy of your Volume used for EC2 Instance.
Question 2
Your company runs an automobile reselling company that has a popular online store on AWS. The
application sits behind an Auto Scaling group and requires new instances of the Auto Scaling group
to identify their public and private IP addresses. Which of the following is the correct AWS option
to identify the IP addresses?
A.
By using Ipconfig for windows or Ifconfig for Linux.
B.
By using a CloudTrail.
C.
Using a Curl or Get Command to get the latest meta-data
from http://169.254.169.254/latest/meta-data/
D.
Using a Curl or Get Command to get the latest user-data
from http://169.254.169.254/latest/user-data/
Correct Answer – C
To get the private and public IP addresses, you can run the following commands on the running
instance.
http://169.254.169.254/latest/meta-data/local-ipv4
http://169.254.169.254/latest/meta-data/public-ipv4
- Option A is incorrect because the public IPv4 address is not displayed using ifconfig
(Linux) or ipconfig
(Windows).
- Option B is incorrect because CloudTrail is used for tracking the API activities of a
resource.
- Option D is incorrect because user data cannot get the IP addresses.
Question 3
You have been designing a CloudFormation template that creates one elastic load balancer fronting
two EC2 instances. Which section of the template should you edit so that the load balancer’s DNS is
returned upon creating the stack?
A.
Resources
B.
Parameters
C.
Outputs
D.
Mappings
Answer – C
The below example shows a simple CloudFormation template. It creates an EC2 instance based on the
AMI - ami-d6f32ab5. When the instance is created, it will output the AZ in which it is
created.
- Option A is incorrect because this is used to define the main resources in the template.
- Option B is incorrect because this is used to define parameters that can be taken during template deployment.
- Option D is incorrect because this is used to map key-value pairs in a template.
Question 4
Your company has a set of resources defined in AWS. These resources consist of applications hosted
on EC2 Instances. Data is stored on EBS volumes and S3. The company mandates that all data should be
encrypted at rest. How can you achieve this? Choose 2 answers from the options below.
A.
Enable SSL with the underlying EBS volumes.
B.
Enable EBS Encryption.
C.
Make sure that data is transmitted from S3 via HTTPS.
D.
Enable S3 server-side Encryption.
Answer - B and D
The AWS Documentation mentions the following.
Amazon EBS encryption offers a simple encryption solution for your EBS volumes without the need to
build, maintain, and secure your own key management infrastructure.
Server-side encryption protects data at rest. Server-side encryption with Amazon S3-managed
encryption key (SSE-S3) uses strong multi-factor encryption.
Options A and C are incorrect since they have to do with encryption of data in transit, but not at
rest.
Question 5
You have been instructed to establish a successful site-to-site VPN connection from your on-premises
network to the VPC (Virtual Private Cloud). As an architect, which of the following pre-requisites
should you ensure to establish the site-to-site VPN connection? Choose 2 answers from the options
given below.
A.
The main route table to route traffic through a NAT instance
B.
A public IP address on the customer gateway for the on-premises network
C.
A virtual private gateway attached to the VPC
D.
An Elastic IP address to the Virtual Private Gateway
Answers - B and C
Option B: This is necessary for the VPN connection to be established, as the customer gateway needs
a public IP address to communicate with the virtual private gateway on the AWS side.
Option C: A virtual private gateway attached to the VPC: This acts as the VPN concentrator on the
AWS side of the VPN connection, allowing the VPC to connect to the on-premises network.
- Option A is incorrect: This is not required for establishing a site-to-site VPN connection. NAT
instances are used for allowing instances in a private subnet to access the internet, not for VPN
connections.
- Option D is incorrect: Virtual private gateways do not require Elastic IP addresses. They use the
public IP address of the customer gateway for the VPN connection.
Question 6
You are using a c5.large EC2 Instance with one 300GB EBS General purpose SSD volume to host a
relational database. You noticed that the read/write capacity of the database needs to be increased.
Which of the following approaches can help achieve this? Choose 2 answers from the options given
below.
A.
Use a larger EC2 Instance Type.
B.
Enable Multi-AZ feature for the database.
C.
Consider using Provisioned IOPS Volumes.
D.
Put the database behind an Elastic Load Balancer.
Answer - A and C
The below snapshot from the AWS Documentation shows the different volume types and why Provisioned
IOPS is the most ideal for this requirement.
Also, consider using a larger instance size for better processing capabilities based on EBS
Bandwidth.
- Option B is incorrect since the Multi-AZ feature is only for high availability.
- Option D is incorrect since this would not alleviate the high number of read/write of the
database.
Question 7
Your company has a set of AWS RDS Instances. Your management has asked you to disable Automated
backups to save on cost. When you disable automated backups for AWS RDS, what are you compromising
on?
A.
Nothing,you are actually saving resources on aws
B.
You are disabling the point-in-time recovery.
C.
Nothing really, you can still take manual backups.
D.
You cannot disable automated backups in RDS.
Answer – B
Amazon RDS creates a storage volume snapshot of your DB instance, backing up the entire DB instance,
not just individual databases. You can set the backup retention period when you create a DB
instance. If you don't set the backup retention period, Amazon RDS uses a default period retention
period of one day. You can modify the backup retention period; valid values are 0 (for no backup
retention) to a maximum of 35 days.
Automatic Backups are taken daily when we specify the point in time recovery feature that enables
the recovery of the database at any point in time. AWS applies the transaction logs to the most
appropriate DB backup. At the same time, DB snapshots are a manual thing where we user manually
triggers the backup and then restores it from the desired time period.
You will also specifically see AWS mentioning the risk of not allowing automated backups.
Disabling Automated Backups
Important
We highly discourage disabling automated backups because it disables point-in-time recovery. If you
disable and then re-enable automated backups, you can only restore starting from the time you
re-enabled automated backups.
Manual snapshots are user-initiated backups of your instance stored in Amazon S3 that are kept until
you explicitly delete them. You can create a new instance from a database snapshot whenever you
desire. Although database snapshots serve operationally as full backups, you are billed only for
incremental storage use.
Because of the risk which is clearly mentioned in the AWS Documentation, all other options are
incorrect.
Question 8
A company has an AWS account that contains three VPCs (Dev, Test, and Prod) in the same region.
There is a requirement to ensure that instances in the Development and Test VPC’s can access
resources in the Production VPC. There should be minimal efforts with minimal administrative
overhead. Which of the following would be the ideal way to get this in place?
A.
Create an AWS Direct Connect connection between the Development, Test VPC to the Production VPC.
B.
Create a separate VPC peering connection from Development to Production and from Test to the
Production VPC.
C.
Create a VPN connection between the Development, Test VPC to the Production VPC.
D.
Create a VPC peering connection between the Development to the Production VPC and from Development
to the Test VPC.
Answer – B
Options A and C are incorrect since these options will NOT involve minimal efforts or minimal
overhead. Hence you need to choose VPC peering.
Options D is incorrect since the VPC Peering configuration mentioned would be invalid. We need
access from Production to Test and NOT from "Development to Test" as given in the option
You need VPC Peering Configuration between Dev to Prod and Test to Prod.
"A VPC peering connection is a networking connection between two VPCs that enable you to route
traffic between them using private IPv4 addresses or IPv6 addresses. Instances in either VPC can
communicate with each other as if they are within the same network. You can create a VPC peering
connection between your own VPCs, or with a VPC in another AWS account. The VPCs can be in different
regions (also known as an inter-region VPC peering connection)."
Question 9
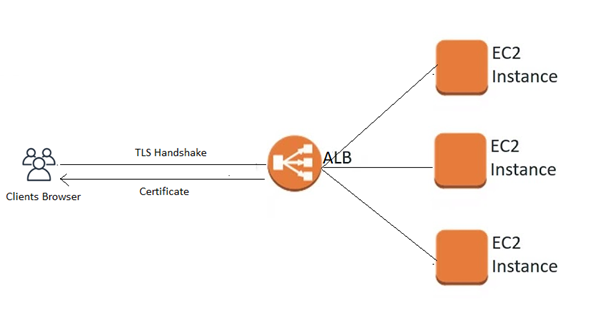
You are working as an AWS consultant for an online grocery store. They are using a two-tier web
application with web-servers hosted in VPC’s at us-east-1 region & on-premise data-center. Network
Load balancer is configured in the front end to distribute traffic between these servers. All
traffic between clients & servers is encrypted. They are looking for an alternate solution to
terminate the TLS connection on this Network Load balancer to reduce load on back-end servers.
This store’s management team has engaged you to suggest a solution for certificate management used
in case of TLS termination. Which of the following is a preferred secure option to provision & store
certificates to be used along with Network Load Balancer for terminating TLS?
A.
Use multiple certificates per TLS listener & If a hostname provided by a client matches multiple
certificates in the certificate list. The load balancer selects all of the certificates.
B.
Use TLS tools to generate a new certificate & upload in AWS Certificate Manager.
C.
Use a single certificate per TLS listener provided by AWS Certificate Manager.
D.
Use a single certificate with 4096 bits RSA keys for higher security.
Correct Answer – C
Network Load Balancer requires one certificate per TLS connection to encrypt traffic between
client & NLB and forward decrypted traffic to target servers. Using AWS Certificate Manager is a
preferred option, as these certificates are automatically renewed on expiry.
- Option A is incorrect as Network Load Balancer uses a smart certificate selection algorithm to
support Server Name Indication (SNI). If the hostname provided by a client matches a single
certificate in the certificate list, the load balancer selects this certificate. If a hostname
provided by a client matches multiple certificates in the certificate list, the load balancer
selects the best certificate that the client can support.
Refer section "Certificate List" under the link:
https://docs.aws.amazon.com/elasticloadbalancing/latest/network/create-tls-listener.html
- Option B is incorrect as this will increase admin work. Also, you will need to monitor the expiry
dates of certificates & renew these certificates before expiration.
- Option D is incorrect as Network Load Balancer does not support certificates with RSA bits higher
than 2048 bits.
Question 10
As a solutions architect, it is your job to design for high availability and fault tolerance.
Company-A is utilizing Amazon S3 to store large amounts of file data. You need to ensure that the
files are still available in the case of an entire region facing an outage due to a natural
disaster. How can you achieve this?
A.
Copy the S3 bucket to an EBS optimized backed EC2 instance
B.
Amazon S3 is highly available and fault tolerant by design and requires no additional configuration
C.
Enable Cross-Region Replication for the bucket
D.
Enable versioning for the bucket
Answer – C
The AWS Documentation mentions the following.
Cross-region replication is a bucket-level configuration that enables automatic, asynchronous
copying of objects across buckets in different AWS Regions. We refer to these buckets as source
bucket and destination bucket. Different AWS accounts can own these buckets.
AWS services are designed with DR considerations in mind. S3, for example, achieves 99.999999999%
durability and 99.99% availability by redundantly storing data across multiple AZs within a region.
It may be rare for the whole AWS region to go down, but it could cause massive permanent damage if
we don’t plan for it; this is when S3 Cross-Region Replication (CRR) solution comes into
play.
- Option A is invalid because this is not the right way to take backups of an S3 bucket.
- Option B is invalid because S3 will ensure that objects are available in multiple availability
zones but not across regions in case of a disaster.
- Option D is invalid because versioning can only help from accidental deletion of objects but not
from disaster recovery.
NOTE:
Most organizations try to implement High Availability (HA) instead of DR to guard them against any
downtime of services. In the case of HA, we ensure there exists a fallback mechanism for our
services. The service that runs in HA is handled by hosts running in different availability zones
but the same geographical region. However, this approach does not guarantee that our business will
be up and running in case the entire region goes down. DR takes things to a completely new level,
wherein you need to recover from a different region that’s separated by over 250 miles. Our DR
implementation is an Active/Passive model, meaning that we always have minimum critical services
running in different regions. Still, a major part of the infrastructure is launched and restored
when required.
Question 11
Your company currently has a set of EC2 Instances hosted on the AWS Cloud. There is a requirement to
ensure the restart of instances if a CloudWatch metric goes beyond a certain threshold. As a
solutions architect, how would you ask the IT admin staff to implement this?
A.
Look at the Cloudtrail logs for events and then restart the Instance based on the events.
B.
Create a CloudWatch metric which looks into the instance threshold, and assign this metric against
an alarm to reboot the instance.
C.
Create a CLI script that restarts the server at certain intervals.
D.
Use the AWS Config utility on the EC2 Instance to check for metrics and restart the server
Answer – B
The AWS Documentation mentions the following.
Using Amazon CloudWatch alarm actions, you can create alarms that automatically stop, terminate,
reboot, or recover your EC2 instances. You can use the stop or terminate actions to help you save
money when you no longer need an instance to be running. You can use the reboot and recover actions
to automatically reboot those instances or recover them onto new hardware if a system impairment
occurs.
- Option A is incorrect because CloudTrail logs will provide event details and not metrics.
- Option C is incorrect because we want to restart Instance as we reach a certain threshold. But
this way, it will keep on restarting the Instance even without any threshold reach.
- Option D is incorrect because AWS Config is a service that enables you to assess, audit, and
evaluate the configurations of your AWS resources.
Question 12
Your company is currently hosting a long-running heavy load application on its On-premise
environment, whose processing time is greater than 15 minutes. The company has developed this
application in-house. Consulting companies then use this application via API calls, and each API
call may take half an hour to finish. You now need to consider moving this application to AWS. Which
of the following services would be best suited in the architecture design, which would also help
deliver a cost-effective solution? (Select TWO)
A.
AWS Lambda
B.
AWS API Gateway
C.
AWS Config
D.
AWS EC2
Answer – B and D
- Option A is incorrect, the question specifies heavy load application, leading to a need for a
time-out of API greater than 15min. As per AWS documentation, AWS Lambda can handle a max time-out
of up to 15 minutes. In this case, the application may take more time to run.
- Option B is correct because Amazon API Gateway is a fully managed service that makes it easy for
developers to create, publish, maintain, monitor, and secure APIs at any scale. With a few clicks
in the AWS Management Console, you can create an API that acts as a “front door” for applications
to access data, business logic, or functionality from your back-end services, such as workloads
running on Amazon Elastic Compute Cloud (Amazon EC2), code running on AWS Lambda, or any web
application.
- Option C is incorrect since this is a configuration service available from AWS.
- Option D is correct because EC2 would fit for using API calls for the application.
Question 13
You have a set of EC2 Instances in a custom VPC. You have installed a web application and need to
ensure that only HTTP and HTTPS traffic is allowed into the instance. Which of the following would
you consider for this requirement?
A.
Add a security group rule to allow HTTP and HTTPS Traffic.
B.
Add a security group rule to an explicit DENY all traffic and a default allow on HTTP and HTTPS
Traffic.
C.
Add a security group rule to deny explicit traffic on HTTP and HTTPS Traffic.
D.
Add a security group rule to allow all traffic.
Answer – A
- Option A is correct because we need to specify the allowed traffic in the security group, i.e.,
HTTP and HTTPS Traffic must be allowed from all sources. No inbound traffic is allowed by default.
By adding security group rules, you can specify which traffic you want to allow. This is
essentially a whitelist.
Options B is incorrect since, by default, nothing is allowed, and in the Security group, we can’t
specify what is denied. We don’t have any deny option in Security Groups.
- Option C is incorrect because we can specify what is allowed in the security group but not what is
denied. If you want to deny explicitly, you should use the Network Access control list.
- Option D is incorrect since this would be a security issue.
Question 14
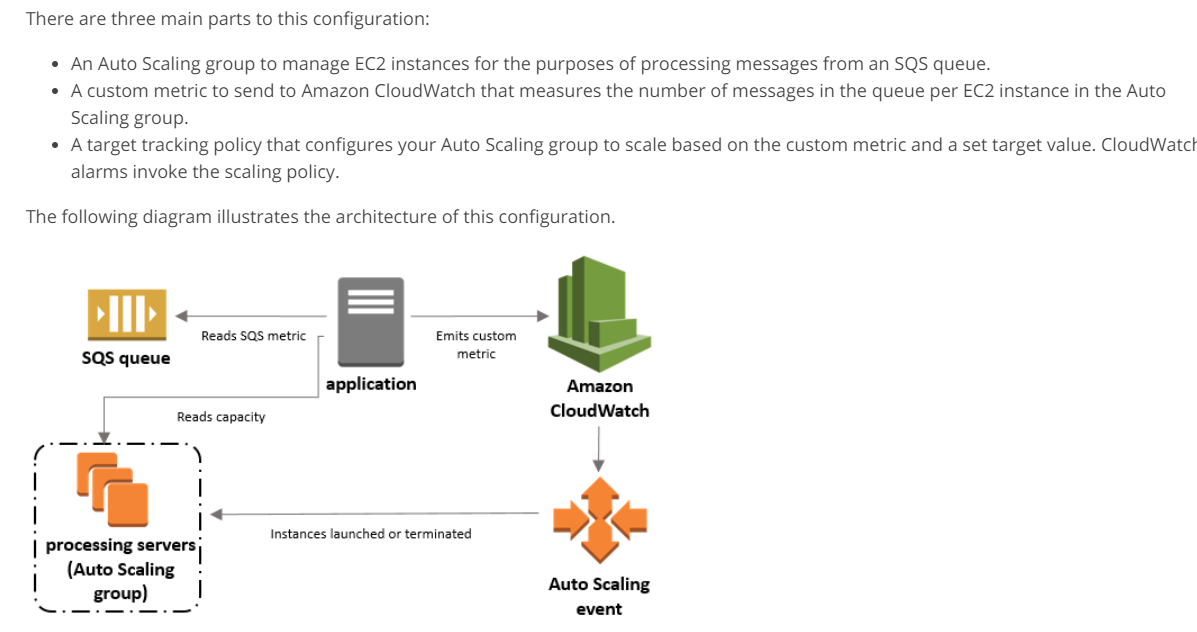
A company has an application defined with the following architecture.
A fleet of EC2 Instances which are used to accept video uploads from users.
A fleet of EC2 Instances which are used to process the video uploads.
Which of the following would help architect an operationally excellent architecture?
A.
Create an SQS queue to store the information for Video uploads. Spin up the processing servers via
an Autoscaling Group. Ensure the Group scales based on the Memory utilization of the underlying
processing servers.
B.
Create an SQS queue to store the information for Video uploads. Spin up the processing servers via
an Autoscaling Group. Ensure the Group scales based on the size of the queue.
C.
Create an SNS topic to store the information for Video uploads. Spin up the processing servers via
an Autoscaling Group. Ensure the Group scales based on the Memory utilization of the underlying
processing servers.
D.
Create an SNS topic to store the information for Video uploads. Spin up the processing servers via
an Autoscaling Group. Ensure the Group scales based on the size of the queue messages.
Answer – B
This architecture is also given in the AWS Documentation.
- Option A is incorrect. The ideal approach is to scale the instances based on the size of the
queue.
Options C and D are incorrect since you should be using SQS queues. SNS topics are used for
notification purposes.
As per AWS,
You can use the number of messages stored in an SQS queue as an indicator of the amount of work
waiting in line for eventual processing within an Auto Scaling Group comprised of a variable number
of EC2 instances. Each SQS queue reports a number of metrics to CloudWatch at five minute intervals,
including ApproximateNumberOfMessagesVisible
. If your workload is spikey in nature, you may want to build an application that can respond more
quickly to changes in the size of the queue.
Memory utilization metrics are custom metrics. For this, you need to install a Cloudwatch agent on
the EC2 instances and need to aggregate the dimensions.
However, AWS already has a well-defined architecture based on SQS Queuelength being used for
Autoscaling EC2 instances.
Question 15
A company has an Aurora MySQL DB cluster setup, and the DB needs to invoke a Lambda function. Which
of the following need to be in place for this setup to work. (Select TWO)
A.
Ensure that the Lambda function has an IAM Role assigned to it which can be used to invoke functions
on Amazon Aurora.
B.
Ensure that the Aurora MySQL DB cluster has an IAM Role which allows it to invoke Lambda functions.
C.
Allow the Lambda function to allow outbound communication to Amazon Aurora.
D.
Configure the Aurora MySQL DB cluster to allow outbound connections to the Lambda function.
Answer – B and D
The below snapshot from the AWS Documentation shows the different steps required to ensure that the
Lambda function can access Amazon Aurora.
Options A and C are incorrect since the configurations need to be the other way around.
Question 16
Your company is planning on the following architecture for their application.
· A set of EC2 Instances hosting the web part of the application.
· A relational database for the backend using the AWS RDS MySQL service
· A Load balancer for distribution of traffic
There is a requirement to ensure that all data hosted in the database service is encrypted at rest.
How can you achieve this requirement in the easiest manner? (Select 2)
A.
Encrypt the underlying EBS volumes for the database
B.
Use the Encryption feature for RDS
C.
Use S3 server-side encryption
D.
Use AWS Key Management Service
Answer – B and D
The AWS Documentation mentions the following.
- Option B is correct because, With RDS-encrypted resources, data is encrypted at rest, including
the underlying storage for a database (DB) instance, its automated backups, read replicas, and
snapshots. This capability uses the open standard AES-256 encryption algorithm to encrypt your
data, transparent to your database engine.
This encryption option protects against physical exfiltration or access to your data bypassing the
DB instances. Therefore, it is critical to complement encrypted resources with an effective
encryption key management and database credential management practice to mitigate any unauthorized
access. Otherwise, compromised credentials or insufficiently protected keys might allow unauthorized
users to access the plaintext data directly through the database engine.
Encryption key management is provided using the AWS KMS.
- Option D is correct because Amazon RDS encrypts your databases using keys you manage with the AWS
Key Management Service (KMS). On a database instance running with Amazon RDS encryption, data
stored at rest in the underlying storage is encrypted, as are its automated backups, read
replicas, and snapshots. RDS encryption uses the industry-standard AES-256 encryption algorithm to
encrypt your data on the server that hosts your RDS instance.
Options C is incorrect because this is used for the encryption of objects in S3.
- Option A is incorrect since this can be easily achieved using the encryption at rest feature for
AWS RDS.
The term 'rest' means when data is resting (not in transition-while data is traveling to the
database.
Question 17
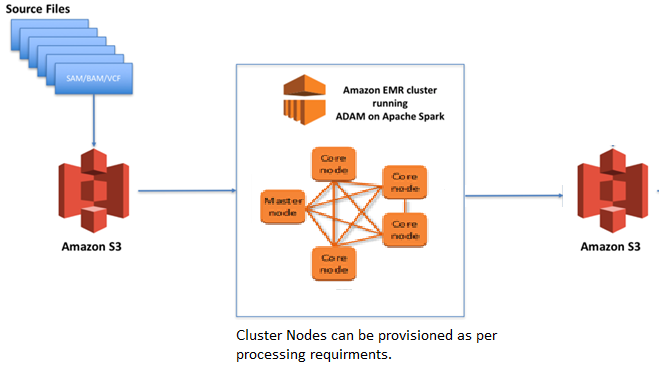
A global IT Firm is working on a project to process Genomics data for a scientific organization.
Researchers are looking for a quick analysis of large amounts of data they need to retrieve from any
part of the world seamlessly. IT Firm has AWS Direct Connect link from on-premise Datacenter to AWS
VPC. As an AWS consultant, they are looking for your guidance to provide a long-term cost-effective
solution that can handle any amount of data reliably.
Which of the following solutions can be deployed to meet IT firm requirements?
A.
Use Amazon EMR with Apache Spark & data stored in Amazon S3 bucket.
B.
Use Apache Spark deployed at on-premise servers with data stored in Amazon S3 bucket.
C.
Use Amazon EMR with Apache Spark & data stored in Amazon EC2 instance store.
D.
Use Apache Spark deployed at on-premise servers with data stored in Amazon EC2 instance store.
Correct Answer: A
Amazon EMR is a big data platform used for processing large amounts of data. For analyzing large
amounts of data, Amazon EMR can be used to provide reliable cost-effective solutions. It supports
open-source tools like Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and
Presto. Data can be stored in an Amazon S3 bucket to have scalable storage options & can be accessed
globally. With EMR Cluster, compute & storage are decoupled. For storage, Amazon S3 can be used. For
compute, clusters can be launched as per processing required & stopped when there is no requirement,
saving additional cost. When Apache Spark is deployed on-premise, customers must manage physical
infrastructure & large processing requirements. There is an additional cost of building new
infrastructure.
- Option B & D are incorrect as deploying Apache Spark at on-premise servers would be a non-scalable
solution & will incur additional cost for managing server farms.
- Option C is incorrect as storing analytical data in Amazon EC2 instance store would be ideal only
for temporary solution & not for long term reliable storage.
Question 18
Your team has an application hosted on AWS. This application currently interacts with a DynamoDB
table which has the Read capacity set to 10. Based on recent cloudwatch alarms which indicated that
throttling was occurring in the requests to the DynamoDB table. Which of the following would help
ensure the issue was resolved now and help ensure the issue does not occur in the future?
A.
Add an Elastic Load Balancer in front of the DynamoDB table.
B.
Change the Read Capacity for the table to 20.
C.
Change the Write capacity for the table to offset the Read capacity.
D.
Enable Autoscaling for the underlying DynamoDB table
Answer – D
The AWS Documentation mentions the following.
DynamoDB auto scaling uses the AWS Application Auto Scaling service to dynamically adjust
provisioned throughput capacity on your behalf, in response to actual traffic patterns. This enables
a table or a global secondary index to increase its provisioned read and write capacity to handle
sudden increases in traffic without throttling. When the workload decreases, Application Auto
Scaling decreases the throughput so that you don't pay for unused provisioned capacity.
You can optionally allow DynamoDB Auto-scaling to manage your table's throughput capacity. However,
you still must provide initial settings for read and write capacity when you create the table.
DynamoDB auto scaling uses these initial settings as a starting point and then adjusts them
dynamically in response to your application's requirements.
As your application data and access requirements change, you might need to adjust your table's
throughput settings. If you're using DynamoDB Auto-scaling, the throughput settings are
automatically adjusted in response to actual workloads. You can also use the UpdateTable
operation to adjust your table's throughput capacity manually. You might decide to do this if you
need to bulk-load data from an existing data store into your new DynamoDB table.
- Option A is incorrect since the Elastic Load balancer in front of the DynamoDB table won’t help
increase the capacity of DynamoDB. Here, We need to scale up and down the capacity automatically
based on the requirement.
- Option B is incorrect since this would only help in temporarily resolving the situation.
- Option C is incorrect since provisioning Write capacity would not help in this case.
Question 19
Your team is developing a Lambda function. The function would need to interact with a database. The
Lambda function and the database will be deployed in different environments. Which of the following
is the most secure approach for the Lambda function to get the database credentials for multiple
environments?
A.
Hardcode the database credentials in GitHub for different environments of the Lambda function.
B.
Create a lambda function for each environment and ensure each has a different programming language.
C.
Store the database credentials in AWS Secrets Manager.
D.
Store the database credentials in a Lambda function tag.
Answer – C
Secrets Manager supports many types of secrets. However, Secrets Manager can natively rotate
credentials for supported AWS databases without any additional programming. However, rotating the
secrets for other databases or services requires creating a custom Lambda function to define how
Secrets Manager interacts with the database or service.
- Option A is incorrect since this has a security issue since the database credentials are hardcoded
in GitHub.
- Option B is incorrect since using different programming languages makes no sense.
- Option C is correct because AWS Secrets Manager can store the database credentials in a secure way
for the Lambda function to get the credentials. AWS Secrets Manager helps users to protect and
manage credentials.
- Option D is incorrect since, you can tag Lambda functions to organize them by owner, project, or
department. Tag keys and tag values are supported across AWS services for use in filtering
resources and adding detail to billing reports. It is not used to store such connection
strings.
Question 20
A telecom company has installed radio devices across the country. On a daily basis, they are looking
to collect logs from these thousands of devices & analyze them further to monitor faults & uptime
trends. For analysis of logs, they are planning to use Amazon Redshift. No additional processing
needs to be done on these logs. The company is concerned about collecting data & sending compressed
data to Amazon Redshift & is looking for a scalable solution without any ad-hoc administration.
Which of the following services can be used to meet this requirement?
A.
Create an Amazon Kinesis Streams, save compressed data in Amazon EC2 and then copy data to Amazon
Redshift.
B.
Create an Amazon Kinesis Data Firehose Delivery Stream, save compressed data in the Amazon S3 bucket
and then copy data to Amazon Redshift.
C.
Create an Amazon Kinesis Data Firehose Delivery Stream, save compressed data in Amazon EC2 and then
copy data to Amazon Redshift.
D.
Create an Amazon Kinesis Streams, save compressed data in the Amazon S3 bucket and then copy data to
Amazon Redshift.
Correct Answer: B
Amazon Kinesis Data Firehose can be used to deliver data from thousands of sources to AWS service
for further analysis. In the above case, the telecom company will use Amazon Redshift as an
analytical service, so Amazon Kinesis Data Firehose Delivery Stream can be created to collect logs
from thousands of radio devices. Amazon Kinesis Data Firehose cannot directly send data logs to
Amazon Redshift but needs to first store in the Amazon S3 bucket & then it copies data to Amazon
Redshift.
Amazon Kinesis Data Firehose is used when real-time streaming data is required to be delivered to
destinations like Amazon S3 bucket, Amazon Redshift, Amazon OpenSearch (Amazon ES), and AWS Splunk.
While delivering data to destinations, it supports the transformation of data like compression,
batch, or encryption. Amazon Kinesis Data Firehose stores data only up to 24 hours if the
destination is unavailable.
Options A and D are incorrect as the telecom company is not looking for additional processing or
storing logs as all these logs would be generated daily. Creating Amazon Kinesis Data Firehose
Delivery Stream is a better option than using Amazon Kinesis Streams.
- Option C is incorrect as Amazon Kinesis Data Firehose cannot save data to the Amazon EC2
instance.
Question 21
Your company currently has the following architecture for its e-commerce application.
· EC2 Instances hosting the application
· An Autoscaling group for the EC2 Instances
The users who use the application keep on complaining that the application is slow in the morning
from 9:00 – 9:30, after which no issues occur. Which of the following can be done to ensure the
issue is not encountered during the morning time?
A.
Ensure that a Simple scaling policy is added to the Auto scaling Group.
B.
Ensure that a step scaling policy is added to the Auto scaling Group.
C.
Ensure that a scheduled scaling policy is added to the Auto scaling Group.
D.
Ensure that a static scaling policy is added to the Auto scaling Group
Answer – C
The AWS Documentation mentions the following.
Scaling based on a schedule allows you to scale your application in response to predictable load
changes. For example, every week, the traffic to your web application starts to increase on
Wednesday, remains high on Thursday, and starts to decrease on Friday. You can plan your scaling
activities based on the predictable traffic patterns of your web application.
- Option A is incorrect because simple scaling increases or decreases the group's current capacity
based on a single scaling adjustment.
- Option B is incorrect because Step Scaling increases or decreases the group's current capacity
based on a set of scaling adjustments, known as step adjustments, that vary based on the size of
the alarm breach.
- Option D is incorrect since Static scaling policy doesn’t exist.
Question 22
Your company has an existing Redshift cluster. The sales team currently stores historical data in
the cluster. There is now a requirement to ensure that all data is encrypted at rest. What do you
need to do at your end?
A.
Enable the encryption feature for the cluster.
B.
Enable encryption for the underlying EBS volumes.
C.
Use SSL certificates to encrypt the data at rest.
D.
Create a new cluster with encryption enabled and then migrate the data over to the new cluster.
Correct Answer – A
The AWS Documentation mentions the following.
In Amazon Redshift, you can enable database encryption for your clusters to help protect data at
rest.
You can modify an unencrypted cluster to use AWS Key Management Service (AWS KMS) encryption, using
either an AWS-managed key or a customer managed key. When you modify your cluster to enable AWS KMS
encryption, Amazon Redshift automatically migrates your data to a new encrypted cluster. You can
also migrate an unencrypted cluster to an encrypted cluster by modifying the cluster.
- Option A is CORRECT because you can now enable encryption for an existing Redshift cluster.
- Option B is incorrect since the encryption needs to be enabled at the cluster level (database)
rather than EBS volumes.
- Option C is incorrect since SSL certificates are used for the encryption of data in
transit.
- Option D is incorrect because you can now enable encryption for an existing Redshift cluster and
therefore creating a new Redshift cluster is unnecessary.
Question 23
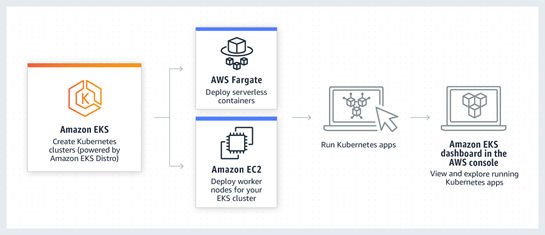
A start-up firm is developing a microservices-based application using open-source container
orchestration. This application will be integrated with other Public Cloud. The firm does not have
any expertise to provision & manage back-end infrastructure to set up this container. You have been
assigned to provide consultation for deploying containers.
Which of the following will you suggest meeting the requirement?
A.
Use Amazon Elastic Kubernetes Service with Amazon EC2 launch type.
B.
Use Amazon Elastic Container Service with AWS Fargate launch type.
C.
Use Amazon Elastic Container Service with Amazon EC2 launch type.
D.
Use Amazon Elastic Kubernetes Service with AWS Fargate launch type
Correct Answer: D
Amazon Elastic Kubernetes Service can be used to set up open-source Container orchestration like
Kubernetes. Amazon Elastic Kubernetes Service can be integrated with other public or private clouds.
AWS Fargate can be used as a serverless compute for deploying containers. With AWS Fargate, there is
no need to set back-end infrastructure for containers. With AWS Fargate, based upon task
definitions, containers are launched. The following diagram depicts the deployment of AWS
Kubernetes, with AWS Fargate, serverless containers can be deployed while using Amazon EC2, compute
nodes are deployed manually as per requirement. Using Amazon EC2 provides more control on back-end
infrastructure for containers. But customers have to perform management of these instances.
- Option A is incorrect as with the Amazon EC2 launch type. The firm will need to set up backend
infrastructure & manage instance provisioning.
- Option B & C are incorrect as the customer is looking for integration with Public Cloud & an
open-source solution. Amazon Elastic Container Service supports integration with AWS services & is
an AWS Proprietary service.
Question 24
A popular podcast in English wants to expand its audience globally by translating its episodes into
multiple languages. Which AWS services can be used to automate the translation and transcription of
podcast episodes? (Select TWO)
A.
Amazon Kendra
B.
Amazon Rekognition
C.
Amazon Lex
D.
Amazon Transcribe
E.
Amazon Translate
Correct Answers: D and E
Amazon Transcribe automatically transcribes audio and video files into text. In this case, it can be
used to convert the English podcast episodes into text format.
Amazon Translate translates text from one language to another. Once the podcast episodes are
transcribed into text, Translate can be used to translate the text into multiple languages.
- Option A is incorrect. Amazon Kendra is used for building enterprise search solutions. It's not
relevant to the task of translating and transcribing audio content.
- Option B is incorrect. Amazon Rekognition is used for analyzing images and videos. It's not
relevant to the task of processing audio content.
- Option C is incorrect. Amazon Lex is used for building conversational interfaces. While it could
be used for future applications involving interactive translations, it's not directly relevant to
the initial translation and transcription process.
Question 25
In your AWS VPC, you need to add a new subnet that will allow you to host a total of 20 EC2
instances. Which IPv4 CIDR block would you use to achieve the same?
A.
151.0.0.0/27
B.
151.0.0.0/28
C.
151.0.0.0/29
D.
151.0.0.0/30
Correct Answer: A
AWS reserves 5 IP addresses.
The first four IP addresses and the last IP address in each subnet CIDR block are not available for
you to use, and cannot be assigned to an instance. For example, in a subnet with CIDR block
10.0.0.0/24, the following five IP addresses are reserved:
10.0.0.0: Network address.
10.0.0.1: Reserved by AWS for the VPC router.
10.0.0.2: Reserved by AWS. The IP address of the DNS server is the base of the VPC network range
plus two. For VPCs with multiple CIDR blocks, the IP address of the DNS server is located in the
primary CIDR. We also reserve the base of each subnet range plus two for all CIDR blocks in the VPC.
For more information, see the Amazon DNS server.
10.0.0.3: Reserved by AWS for future use.
10.0.0.255: Network broadcast address. We do not support broadcast in a VPC, therefore we reserve
this address.
The formula to calculate the number of assignable IP addresses to CIDR networks is similar to
classful networking. Subtract the number of network bits from 32. For example, a /24 network has 2^(
32-24) - 2 addresses available for host assignment.
A. Prefix Length is ‘27’
Therefore 32-27 = 5 and 2 ^ 5 (i.e 2 * 2 * 2 * 2 * 2) – 5 = 27
B. Prefix Length is ‘28’
Therefore 32-28 = 4 and 2 ^ 4 (i.e 2 * 2 * 2 * 2) - 5= 11
C. Prefix Length is ‘29’
Therefore 32-29 = 3 and 2 ^ 3 (i.e 2 * 2 * 2) - 5 = 3
D. Prefix Length is ‘30’
Therefore 32-30 = 2 and 2 ^ 2 (i.e 2 * 2) - 5 = -1
For option ‘A’, we get ‘27’ IP addresses (or indirectly the number of instances to be provisioned)
as shown above.
Since the user has to provision ‘20’ EC2 instances, we need to go with option ‘A’, which is the only
correct IPv4 CIDR block.
- Option B is incorrect because we get only ‘11’ IP addresses (or indirectly the number of instances
to be provisioned ).
- Option C is incorrect because we get only ‘3’ IP addresses.
- Option D is incorrect because we get only ‘-1’ IP address.
Question 26
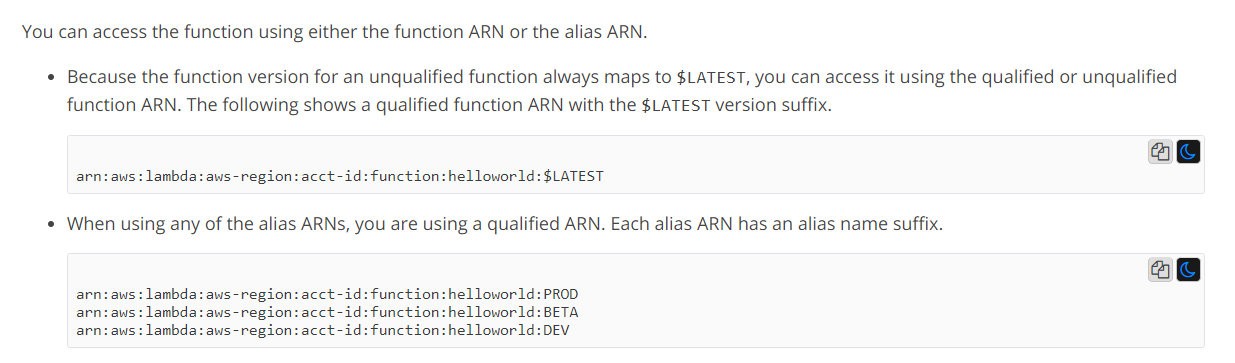
Which of the following are correct ARNs for a Lambda function? (choose 3 options)
A.
arn:aws:lambda:aws-region:acct-id:function:helloworld:$LATEST
B.
arn:aws:lambda:aws-region:acct-id:function:helloworld
C.
arn:aws:lambda:aws-region:acct-id:function:helloworld/$LATEST
D.
arn:aws:lambda:aws-region:acct-id:function:helloworld:PROD
E.
arn:aws:lambda:aws-region:acct-id:function:helloworld/1
Answer: A, B, D
Question 27
A global sports news company has hosted its website on Amazon EC2 instance using a single Public IP
address & is front-ended by TLS-enabled Application Load Balancer. For an upcoming mega sports
event, they plan to launch a new website on the existing Amazon EC2 instance. The company has
registered a different domain name & possesses a separate TLS certificate for this new website.
As an AWS consultant to this company, which of the following recommendations will you provide to
support multiple certificates with existing Public IP addresses in the most cost-effective way?
A.
Launch an additional TLS-enabled ALB front ending Amazon EC2 instance with different certificates
for each domain.
B.
Use Wildcard certificates on ALB matching old & new domain name.
C.
Use a single certificate on ALB & add Subject Alternative Name (SAN) for additional domain name.
D.
Use multiple TLS certificates on ALB using Server Name Indication (SNI).
Correct Answer: D
ALB supports Server Name Indication (SNI), enabling hosting multiple domain names with different TLS
certificates behind a single ALB. With SNI, multiple certificates can be associated with listeners
in ALB, enabling each web application to use separate certificates. The below diagrams shows the
process which takes place when a client tries to access a website. Client Browser starts a TLS
handshake by sending a ClientHello message which consists of protocol version, extensions, cipher
suites, and compression techniques. Based on browser capabilities, ALB responds with a valid
certificate for a domain name of the requested web application.
- Option A is incorrect as launching additional ALB will work. But it will incur additional cost &
admin work for setup.
- Option B is incorrect as using wildcard certificates can be used for related sub-domains & not
different domains.
- Option C is incorrect as using SAN certificates, for any new addition of domain, all certificates
need to revalidate with certificate authority.
Question 28
A company is planning to host an active-active site. One site will be deployed in AWS, and the other
one on their On-premise data center. They need to ensure that the traffic is distributed to multiple
resources, proportionately between both sites. Which of the following routing policy would you use
for this purpose?
A.
Simple Routing
B.
Failover Routing
C.
Latency Routing
D.
Weighted Routing
Answer – D
The AWS Documentation mentions the following.
Weighted routing lets you associate multiple resources with a single domain name (example.com) or
subdomain name (acme.example.com) and choose how much traffic is routed to each resource. This can
be useful for various purposes, including load balancing and testing new versions of
software.
To configure weighted routing, you create records with the same name and type for each of your
resources. You assign each record a relative weight that corresponds with how much traffic you want
to send to each resource. Amazon Route 53 sends traffic to a resource based on the weight you assign
to the record as a proportion of the total weight for all the group records.
- Option A is incorrect since this should be used when you want to configure standard DNS
records.
- Option B is incorrect since this should be used when you want to route traffic to a resource when
the resource is healthy or to a different resource when the first resource is unhealthy.
- Option C is incorrect since this should be used when you want to improve your users' performance
by serving their requests from the AWS Region that provides the lowest latency.
Question 29
A media firm uses the Amazon S3 bucket to save all videos shared by reporters across the globe.
Operation Team has instructed all reporters to use only Multipart Uploads while uploading these
large-sized videos to Amazon S3 bucket in each region. Most of the reporters are working from remote
areas & face challenges in uploading videos. The Finance Team is concerned about high costs incurred
by saving data in the Amazon S3 bucket & seeking your guidance. Post verification, you observe a
large number of incomplete uploads in Amazon S3 buckets in each region. The uncompleted uploads can
be deleted after a certain period of time.
Which of the following actions can minimize charges for saving video files in the Amazon S3 bucket?
A.
Reporter’s need to compress video files locally before uploading to Amazon S3 bucket.
B.
Reporter’s need to upload Videos to Amazon S3 Glacier to save additional charges.
C.
Create a Lifecycle Policy to move all incomplete Multipart uploads to Amazon S3 Glacier after weeks’
time from initiation.
D.
Create a Lifecycle Policy to delete all incomplete Multipart uploads after weeks’ time from
initiation.
Correct Answer: D
Incomplete Multipart Uploads incur storage charges on the Amazon S3 bucket. Lifecycle rules can be
used to abort the uploading of multipart uploads that are incomplete since a specific time frame &
also deletes these parts to free up storage, reducing costs for this storage.
- Option A & B are incorrect as Incomplete Multipart Uploads incur charges. These charges can be
stopped by stopping multipart uploads.
- Option C is incorrect as Moving all incomplete Multipart uploads to Amazon S3 Glacier would not
completely reduce the cost for storing data. As data in Amazon S3 Glacier would incur cost, it
would be less than data storing the Amazon S3 bucket. Also, incomplete Multipart uploads would not
be used until fully uploaded.
Question 30
You have currently contacted an AWS Partner Network (APN) Partner to carry out an audit for your AWS
account. You need to ensure that the partner can carry out an audit on your resources. Which one of
the following steps would you ideally carry out?
A.
Create an IAM user for the partner account for login purposes.
B.
Create a cross account IAM Role and share the ARN with APN
C.
Create an IAM group for the partner account for login purposes.
D.
Create an IAM profile for the partner account for login purposes.
Answer - B
The AWS Documentation mentions the following.
Cross-account IAM roles allow customers to securely grant access to AWS resources in their account
to a third party, like an APN Partner, while retaining the ability to control and audit who is
accessing their AWS account. Cross-account roles reduce the amount of sensitive information APN
Partners need to store for their customers so that they can focus on their product instead of
managing keys.
Using an IAM user to control 3rd party access involves handing over an Access Key/Secret Key - this
is the simple "access badge."
Using AssumeRole to control 3rd party access uses the same information plus a security token. To
assume a role, your AWS account must be trusted by the role. The trust relationship is defined in
the role's trust policy when the role is created. This is the "access badge with fingerprint
validation."
Anyone can use the IAM keys - they're just a key pair. Anyone can take them and use them later on,
and you would not be able to be identified from the trusted party they were given to. To use the
AssumeRole, you must be first authenticated as the trusted entity, and in the case of temporary
credentials, use them while they haven't expired. These extra security features are what make it
more secure.
Typically, you use AssumeRole
for cross-account access.
Options A and C are incorrect since it is not secured as IAM users and IAM group (a set of users)
will be given permissions just like giving keys to them without extra security token.
- Option D is incorrect since IAM Profile doesn’t exist in AWS.
Question 31
Your company is planning to make use of the Elastic Container service for managing their
container-based applications. They are going to process both critical and non-critical workloads
with these applications. Which of the following cost-effective setup would they consider?
A.
Use ECS orchestration and Spot Instances for processing critical data and On-Demand for the
non-critical data.
B.
Use ECS orchestration and On-Demand Instances for processing critical data and Spot Instances for
the non-critical data.
C.
Use ECS orchestration and Spot Instances for both the processing of critical data and non-critical
data.
D.
Use ECS orchestration and On-Demand Instances for both the processing of critical data and
non-critical data.
Correct Answer – B
Spot Instances are a cost-effective choice if you can be flexible about when your applications run
and if your applications can be interrupted.
The hourly price for Spot Instances varies based on demand.
A Spot Instance is an unused EC2 instance that is available for less than the On-Demand price.
Because Spot Instances enable you to request unused EC2 instances at steep discounts, you can
significantly lower your Amazon EC2 costs. The hourly price for a Spot Instance is called a Spot
price. The Spot price of each instance type in each Availability Zone is set by Amazon EC2 and
adjusted gradually based on the long-term supply of and demand for Spot Instances. Your Spot
Instance runs whenever capacity is available, and the maximum price per hour for your request
exceeds the Spot price.
Options A and C are incorrect since Spot Instances can be taken back or flexible and should not be
used for critical workloads.
- Option D is incorrect. You can use Spot Instances for non-critical workloads.
Question 32
A company has recently chosen to use the AWS API Gateway service for managing their API’s. It needs
to be ensured that code hosted in other domains can access the API’s behind the API gateway service.
Which of the below security features of the API gateway can be used to ensure that API’s resources
can receive requests from a domain other than the API’s own domain?
A.
API Stages
B.
API Deployment
C.
API CORS
D.
API Access
Correct Answer: C
The AWS Documentation mentions the following.
When your API's resources receive requests from a domain other than the API's own domain, you must
enable cross-origin resource sharing (CORS) for selected methods on the resource. This amounts to
having your API respond to the OPTIONS preflight request with at least the following CORS-required
response headers:
Access-Control-Allow-Methods
Access-Control-Allow-Headers
Access-Control-Allow-Origin
- Option A and B are invalid because these are used to ensure users can call API’s.
- Option D is invalid because there is no such thing as API Access.
Question 33
You are planning to use Auto Scaling groups to maintain the performance of your web application. How
would you ensure that the scaling activity has sufficient time to stabilize without executing
another scaling action?
A.
Modify the Instance User Data property with a timeout interval.
B.
Increase the Auto Scaling Cooldown timer value.
C.
Enable the Auto Scaling cross zone balancing feature.
D.
Disable CloudWatch alarms till the application stabilizes.
Correct Answer – B
AWS Documentation mentions the following.
The Cooldown period is a configurable setting for your Auto Scaling group, ensuring that it doesn't
launch or terminate additional instances before the previous scaling activity takes effect. After
the Auto Scaling group dynamically scales using a simple Scaling Policy, it waits for the Cooldown
period to complete before resuming scaling activities.
Question 34
An organization is planning to use AWS for its production roll-out. The organization wants to
implement automation for deployment such that it will automatically create a LAMP stack, download
the latest PHP installable from S3, set up the ELB and Auto Scaling. Which AWS service would meet
these requirements for making an orderly deployment of the software?
A.
AWS Elastic Beanstalk
B.
AWS CloudFront
C.
AWS CodePipeline
D.
AWS DevOps
Correct Answer – A
The Elastic Beanstalk is an easy-to-use service for deploying and scaling web applications and
services.
For a typical web application, configuring for HA requires running multiple web servers behind a
load balancer, configuring Auto Scaling to replace lost instances and launch more instances in
response to surges in traffic, and having a standby database instance configured for automatic
failover.
For AWS Elastic Beanstalk, production HA configuration also includes running your database instances
outside of your web server environment which allows you to perform blue/green deployments and
advanced database management operations.
And Elastic Beanstalk uses EC2 Autoscaling Group to handle elasticity but Lightsail doesn’t support
autoscaling.
Hence, - Option A is the correct answer.
Question 35
An application currently writes a large number of records to a DynamoDB table in one region. There
is a requirement for a secondary application to retrieve new records written to the DynamoDB table
every 2 hours and process the updates accordingly. What would be an ideal method to ensure that the
secondary application gets the relevant changes from the DynamoDB table?
A.
Insert a timestamp for each record and then, scan the entire table for the timestamp as per the last
2 hours.
B.
Create another DynamoDB table with the records modified in the last 2 hours.
C.
Use DynamoDB Streams to monitor the changes in the DynamoDB table.
D.
Transfer records to S3 which were modified in the last 2 hours.
Correct Answer – C
AWS Documentation mentions the following.
A DynamoDB Stream is an ordered flow of information about changes to items in an Amazon DynamoDB
table. When you enable a stream on a table, DynamoDB captures information about every modification
to data items in the table.
Whenever an application creates, updates or deletes items in the table, DynamoDB Streams write a
stream record with the primary key attribute(s) of the modified items. A stream record contains
information about a data modification to a single item in a DynamoDB table. You can configure the
stream to capture additional information, such as the "before" and "after" images of modified
items.
Question 36
Your organization is building a collaboration platform for which they chose AWS EC2 for web and
application servers and MySQL RDS instance as the database. Due to the nature of the traffic to the
application, they would like to increase the number of connections to the RDS instance. How could
this be achieved?
A.
Login to RDS instance and modify database config file under /etc/mysql/my.cnf
B.
Create a new parameter group, attach it to DB instance and change the setting.
C.
Create a new option group, attach it to DB instance and change the setting.
D.
Modify setting in default options group attached to DB instance
Correct Answer – B
You can create a custom parameter group, modify the max_connections parameter within this group, and
then associate the parameter group with your RDS instance. This method allows you to adjust the
database configuration without directly modifying the default settings or the instance's
configuration files.
- Option A is incorrect because this option is not applicable. After all, you don't have direct
access to the underlying operating system of an RDS instance. AWS manages the infrastructure, so
you can't modify the configuration files directly.
- Option C is incorrect, Option groups in RDS are used to enable and configure additional features
for your database engine, such as Oracle's TDE or SQL Server's SSRS. They are not used for
changing database parameters like max_connections.
- Option D is incorrect, The default parameter group cannot be modified. You need to create a custom
parameter group to change settings like max_connections.
Question 37
An IT company has a set of EC2 Instances hosted in a VPC. They are hosted in a private subnet. These
instances now need to access resources stored in an S3 bucket. The traffic should not traverse the
internet. The addition of which of the following would help to fulfill this requirement?
A.
VPC Endpoint
B.
NAT Instance
C.
NAT Gateway
D.
Internet Gateway
Correct Answer - A
A VPC endpoint enables you to privately connect your VPC to supported AWS services and VPC endpoint
services powered by PrivateLink without requiring an internet gateway, NAT device, VPN connection,
or AWS Direct Connect connection. Instances in your VPC do not require public IP addresses to
communicate with resources in the service. Traffic between your VPC and the other service does not
leave the Amazon network.
Question 38
A company is developing a big data analytics application that requires access to an object
immediately after a write. A big amount of objects will be stored for the application. You need to
design a proper service to store the data. Is AWS S3 service suitable?
A.
No. AWS uses an eventual consistency model.
B.
Yes. AWS S3 delivers strong read-after-write and list consistency automatically.
C.
No. AWS S3 is not suitable for big data applications.
D.
No. AWS S3 is not cost-effective to store a big amount of data.
Correct Answer – B
Amazon S3 delivers strong read-after-write consistency and is suitable for this scenario.
Reference URL: https://aws.amazon.com/cn/s3/consistency/ https://aws.amazon.com/s3/features/
- Option A is incorrect AWS S3 previously used an eventual consistency model but now offers strong
read-after-write consistency for PUTs of new objects and DELETEs, as well as strong consistency
for object listing.
- Option C is incorrect AWS S3 is highly suitable for big data applications due to its scalability,
durability, and wide integration with other AWS services.
- Option D is incorrect AWS S3 is cost-effective for storing large amounts of data, especially with
features like lifecycle policies and storage classes to optimize costs.
Question 39
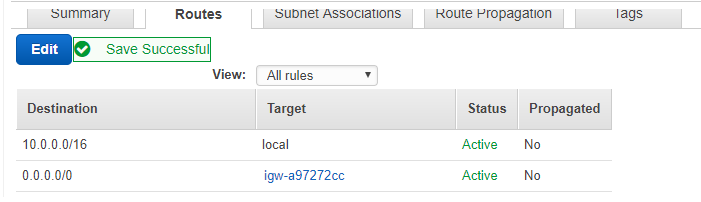
You created your own VPC and subnet in AWS and launched an instance in that subnet. On attaching an
Internet Gateway to the VPC, you see that the instance has a public IP. The route table is shown
below.
Still, the instance cannot reach the Internet. What changes are required to be made to the route
table to ensure that the issue is resolved?
A.
Add the following entry to the route table – Destination as 0.0.0.0/0 and Target as Internet
Gateway.
B.
Modify the above route table – Destination as 10.0.0.0/16 and Target as Internet Gateway.
C.
Add the following entry to the route table – Destination as 10.0.0.0/16 and Target as Internet
Gateway.
D.
Add the following entry to the route table - Destination as 0.0.0.0/16 and Target as Internet
Gateway.
Correct Answer – A
The route table needs to be modified as shown below to ensure that routes from the Instance reach
the Internet.
Hence by default, all other options become invalid.
Question 40
You have been assigned the task of architecting an application in AWS. The architecture would
consist of EC2, the Application Load Balancer, Auto Scaling, and Route 53. You need to ensure that
Blue-Green deployments are possible in this architecture. Which routing policy should you ideally
use in Route 53 to achieve Blue-Green deployments?
A.
Simple
B.
Multivalue Answer
C.
Latency
D.
Weighted
Correct Answer – D
AWS Documentation mentions that the Weighted routing policy is good for testing new versions of the
software. Also, It is the ideal approach for Blue-Green deployments.
Weighted routing lets you associate multiple resources with a single domain name (example.com) or
subdomain name (acme.example.com) and choose how much traffic is routed to each resource. This can
be useful for various purposes, including load balancing and testing new versions of the
software.
NOTE:
Multivalue-answer is recommended to use only when you want to route traffic randomly to multiple
resources, such as web servers. You can create one multivalue answer record for each resource and,
optionally, associate an Amazon Route 53 health check with each record.
However, in this case, we need to choose how much traffic is routed to each resource (blue and
green). For example, Blue is currently live, and we need to send less portion of traffic to Green to
check everything works fine. If yes, then we can decide to go with Green resources. If not, we can
change the weight for that record to 0. Blue will be completely live again.
NOTE:
When you implement the Blue-Green Deployment, it's not always fixed that the Blue environment is in
an Alive state and the Green environment in an Idle state and vice versa. During the testing phase,
you can route your traffic to both the Blue and Green environments with a specified traffic
load.
Question 41
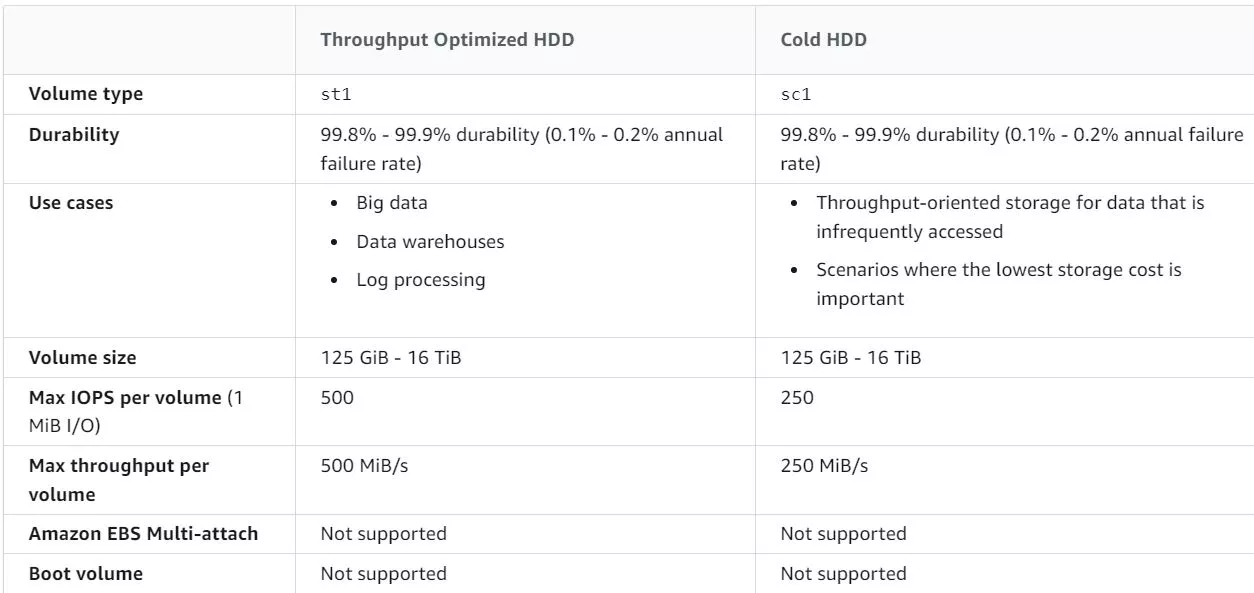
A company is planning to deploy an application in AWS. This application requires an EC2 Instance to
continuously perform log processing activities requiring Max 500MiB/s of data throughput. Which of
the following is the most cost-effective storage option for this requirement?
A.
General Purpose SSD volumes
B.
Provisioned IOPS SSD volumes
C.
Throughput Optimized HDD volumes
D.
Cold HDD volumes
Correct Answer – C
While considering storage volume types for batch processing activities with large throughput,
consider using the EBS Throughput Optimized HDD volume type.
AWS Documentation mentions this, as shown below.
Question 42
There are two folders, A and B, in an S3 bucket. Folder A stores objects that are frequently
accessed. Folder B saves objects that are infrequently accessed and non-critical. The retrieval time
for files in folder B should be within milliseconds. You want to use different storage classes for
objects in these two folders to save cost. Which storage classes are suitable for the requirement?
A.
Standard for folder A and S3 Glacier Instant Retrieval for folder B.
B.
Intelligent-Tiering for folder A and Reduced Redundancy for folder B.
C.
Standard for folder A and One Zone-IA for folder B.
D.
Two S3 buckets are required as an S3 bucket cannot have two storage classes simultaneously
Correct Answer – C
Folder A (Frequently Accessed Objects):
Standard Storage Class is suitable for frequently accessed objects because it offers low latency and
high throughput performance. It is designed for durability and availability, making it ideal for
frequently accessed data.
Folder B (Long-Lived, Infrequently Accessed, Non-Critical Objects):
One Zone-IA (Infrequent Access) is a cost-effective option for infrequently accessed data that does
not require multiple Availability Zone (AZ) redundancy. It provides millisecond access times, making
it suitable for non-critical data that still needs to be accessed quickly when needed. It is less
expensive than the Standard Storage Class and provides a good balance between cost and performance
for infrequent access.
- Option A is incorrect: S3 Glacier Instant Retrieval is designed for long-term archival storage
with quick access, but it may not be as cost-effective as One Zone-IA for non-critical,
infrequently accessed data that still requires millisecond access times.
- Option B is incorrect: Because Reduced Redundancy is not cost-efficient for infrequently accessed
objects.
- Option D is incorrect: Each object in an S3 bucket can have a user-defined storage class. There is
no need to maintain two S3 buckets in this scenario.
Question 43
You are developing a new mobile application which is expected to be used by thousands of customers.
You are considering to store user preferences in AWS and need a non-relational data store to save
the same. Each data item is expected to be 20KB in size. The solution needs to be cost-effective,
highly available, scalable, and secure. Which of the following designs is the most suitable?
A.
Create a new Amazon RDS instance and store the user data there.
B.
Create a Amazon DynamoDB table with the required Read and Write capacity and use it as the data
layer.
C.
Use Amazon Glacier to store the user data.
D.
Use an Amazon Redshift Cluster for managing the user preferences.
Correct Answer – B
In this case, since each data item is 20KB and given the fact that DynamoDB is an ideal data layer
for storing user preferences, this would be the ideal choice. Also, DynamoDB is a highly scalable
and available service.
- Option A is incorrect Amazon RDS is a relational database solution, which is not ideal for
handling highly scalable, non-relational data like user preferences in this use case.
Additionally, it might not be as cost-effective as DynamoDB for this purpose.
- Option C is incorrect Amazon Glacier is designed for long-term archival storage and is not
suitable for frequent access or real-time data operations like storing and retrieving user
preferences.
- Option D is incorrect Amazon Redshift is a data warehouse solution optimized for analytical
queries, not for real-time storage and retrieval of small data items like user preferences.
Question 44
Instances hosted in the private subnet of your VPC need to access some important documents from the
S3 bucket which is outside the VPC. Due to the confidential nature of these documents, you have to
ensure that the traffic does not traverse through the internet. As an architect, how would you
implement this solution?
A.
Consider using a VPC Endpoint.
B.
Consider using an EC2 Endpoint.
C.
Move the instances to a public subnet.
D.
Create a VPN connection and access the S3 resources from the EC2 Instance.
Correct Answer – A
AWS documentation mentions the following:
A VPC endpoint enables you to privately connect your VPC to supported AWS services and VPC endpoint
services powered by PrivateLink without requiring an internet gateway, NAT device, VPN connection or
AWS Direct Connect connection. Instances in your VPC do not require public IP addresses to
communicate with resources in the service. Traffic between your VPC and the other services does not
leave the Amazon network.
Question 45
A company currently hosts its architecture in the us-east-1 region. They now need to duplicate this
architecture to the eu-west-1 region and extend the application hosted on this architecture to the
new AWS Region. To ensure that users in both AWS Regions get the same seamless experience, what
should be done?
A.
Create an Elastic Load Balancer setup to route traffic to both locations.
B.
Create a weighted Route 53 policy to route the policy based on the weightage for each location.
C.
Create an Auto Scaling Group to route traffic to both locations.
D.
Create a Latency-based Route 53 Policy to route the traffic based on the location.
Correct Answer - D
A latency-based Route 53 policy directs traffic to the AWS Region that provides the lowest latency
for users. This ensures a seamless experience for users in both us-east-1 and eu-west-1, optimizing
performance.
Question 46
Your Development team wants to use EC2 Instances to host their Application and Web servers. In the
automation space, they want the Instances always to download the latest version of the Web and
Application servers when launched. As an architect, what would you recommend for this scenario?
A.
Ask the Development team to create scripts which can be added to the User Data section when the
instance is launched.
B.
Ask the Development team to create scripts which can be added to the Meta Data section when the
instance is launched.
C.
Use Auto Scaling Groups to install the Web and Application servers when the instances are launched.
D.
Use EC2 Config to install the Web and Application servers when the instances are launched.
Correct Answer - A
AWS Documentation mentions the following:
When you launch an instance in Amazon EC2, you have the option of passing user data to the instance
that can be used to perform common automated configuration tasks and even run scripts after the
instance starts.
You can pass two types of user data to Amazon EC2: shell scripts and cloud-init directives. You can
also pass this data into the launch wizard as plain text, as a file (this is useful for launching
instances using the command line tools), or as base64-encoded text (for API calls).
- Option B is incorrect because it is generally used to retrieve instance-specific information, such
as instance ID, public keys, and security group information. It is not intended for running
scripts or commands, so this approach is incorrect.
- Option C is incorrect because While Auto Scaling Groups can be used to launch and manage EC2
instances, the installation and configuration of software on those instances should still be
handled via User Data scripts. Auto Scaling Groups themselves do not handle software
installation.
- Option D is incorrect because it is a service used primarily in Windows environments to perform
initial configuration tasks on EC2 instances. Using User Data scripts is recommended for general
purposes and broader compatibility (including Linux).
Question 47
A company website is set to launch in the upcoming weeks. There is a probability that the traffic
will be quite high during the initial weeks. How is it possible to set up DNS failover to a static
website in the event of a load failure?
A.
Duplicate the exact application architecture in another region and configure DNS Weight-based
routing.
B.
Enable failover to an on-premises data center to the application hosted there.
C.
Use Route 53 with the failover option, to failover to a static S3 website bucket or CloudFront
distribution.
D.
Add more servers in case the application fails
Correct Answer – C
Amazon Route 53 health checks monitor the health and performance of your web applications, web
servers, and other resources.
If you have multiple resources that perform the same function, you can configure DNS failover so
that Amazon Route 53 will route your traffic from an unhealthy resource to a healthy resource. For
example, if you have two web servers and one web server becomes unhealthy, Amazon Route 53 can route
traffic to the other web server. So you can route traffic to a website hosted on S3 or to a
CloudFront distribution.
Question 48
A company is running web server reserved EC2 Instances with EBS-backed root volumes. These instances
have a consistent CPU load of 80%. Traffic is being distributed to these instances by an Elastic
Load Balancer. They also have Multi-AZ RDS MySQL databases in both development and production
environments. What recommendation would you make to reduce cost without affecting the availability
of mission-critical systems? Choose the correct answer from the options given below.
A.
Consider using On-demand instances instead of Reserved EC2 instances.
B.
Consider not using the Multi-AZ RDS deployment for the database in the development environment.
C.
Consider using Spot instances instead of Reserved EC2 instances.
D.
Consider removing the Elastic Load Balancer
Correct Answer – B
Multi-AZ databases are more suitable for production environments than for development environments.
So you can reduce costs by not using these for development environments.
Amazon RDS Multi-AZ deployments provide enhanced availability and durability for Database (DB)
Instances, making them a natural fit for production database workloads. When you provision a
Multi-AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronously
replicates the data to a standby instance in a different Availability Zone (AZ). Each AZ runs on its
own physically distinct, independent infrastructure and is engineered to be highly reliable. In case
of an infrastructure failure, Amazon RDS performs an automatic failover to the standby (or to a read
replica in the case of Amazon Aurora). Thus you can resume database operations as soon as the
failover is complete. Since the endpoint for your DB Instance remains the same after a failover,
your application can resume database operation without the need for manual administrative
intervention.
Note:
Mission Critical system refers to production Instances and Databases. However, if you notice, they
have Multi-AZ RDS in the Development environment, which is unnecessary. Because management is always
concerned about production, the environment should be perfect.
To reduce the cost, we can disable the Multi-AZ RDS for the Development environment and keep it only
for the Production environment.
Question 49
Currently, you’re responsible for the design and architect of a highly available application. After
building the initial environment, you discover that your application does not work correctly until
port 443 is added to the security group. After adding port 443 to the appropriate security group,
how much time will it take for the application to work correctly?
A.
Generally, it takes 2-5 minutes for the rules to propagate.
B.
Immediately after a reboot of the EC2 Instances, belonging to that security group.
C.
Changes apply instantly to the security group, and the application should be able to respond to
requests on port 443.
D.
It will take 60 seconds for the rules to apply to all Availability Zones within the region.
Correct Answer – C
When you add port 443 to a security group in AWS, the changes are applied almost instantly. So, the
correct answer is that changes apply instantly to the security group, and the application should be
able to respond to requests on port 443.
Option A: This is not accurate for AWS security groups. Changes to security group rules are applied
almost instantly.
Option B: Rebooting EC2 instances is not necessary for security group changes to take effect. The
changes are applied immediately without needing a reboot.
Option D: This is also incorrect. Security group changes are propagated instantly across all
Availability Zones within the region.
Question 50
A company is planning to use the AWS ECS service to work with containers in the “us-east-1” region.
There is a need for the least amount of administrative overhead while provisioning and managing
containers. How could this be achieved?
A.
Use the Fargate launch type in AWS ECS.
B.
Use the EC2 launch type in AWS ECS.
C.
Use the Auto Scaling launch type in AWS ECS.
D.
Use the ELB launch type in AWS ECS.
Correct Answer - A
AWS Documentation mentions the following:
The Fargate launch type allows you to run your containerized applications without the need to
provision and manage the backend infrastructure. Just register your task definition and Fargate
launches the container for you.
Question 51
A mid-sized company is planning to migrate a large, legacy database to AWS. The company is primarily
concerned with minimizing downtime and cost during the migration process.
Which AWS service is best suited for migrating a large, legacy database to AWS while minimizing
downtime and cost?
A.
AWS Application Discovery Service
B.
AWS Application Migration Service
C.
AWS Database Migration Service (AWS DMS)
D.
AWS DataSync
Correct Answer: C
- Option C is correct. AWS DMS service is specifically designed for migrating relational databases
to AWS. It minimizes downtime by replicating data in real-time to the target database, allowing
for a seamless cutover. Additionally, DMS is highly cost-effective as it automates the migration
process, reducing manual effort and associated costs.
- Option A is incorrect. AWS Application Discovery Service is used to discover and document existing
IT infrastructure. While it's a valuable tool for planning migrations, it doesn't directly migrate
databases.
- Option B is incorrect. AWS Application Migration Service is used to migrate entire applications to
AWS, including their servers and databases. While it's a powerful tool, it might be overkill for a
simple database migration and could potentially be more expensive than using a specialized service
like DMS.
- Option D is incorrect. AWS DataSync service is used for transferring large amounts of data between
on-premises storage and AWS storage. While it can be used for data migration, it's not
specifically designed for database migrations and might not offer the same level of automation and
cost-effectiveness as DMS.
Question 52
A 50 year old Computer Solutions company has a very big application that needs to be deployed to the
AWS cloud from its existing server. The application is media access control (MAC) address dependent
as per the application licensing terms. This application will be deployed in an on-demand EC2
instance with instance type r4.2xlarge. In this scenario, how can you ensure that the MAC address of
the EC2 instance will not change even if the instance is restarted or rebooted?
A.
Assign static MAC Address to EC2 instance while setting up the server.
B.
Use a VPC with an elastic network interface that has a fixed MAC Address.
C.
Use a VPC with a private subnet for the EC2, by default MAC address will be fixed.
D.
Use a VPC with a private subnet and configure the MAC address to be tied to that subnet
Correct Answer - B
- Option A is incorrect because you cannot assign a static MAC Address to EC2 Server. If the server
restarts, it will also change.
- Option B is correct because for the server to be MAC Dependent, you must use VPC with an ENI (
Elastic Network Interface).
- Option C and D are incorrect because using a private subnet in VPC cannot help get MAC Address
fixed.
Question 53
One of your colleagues, who is new to the company where you work as a cloud Architect, has some
issues with IP Addresses. He has created an Amazon VPC with an IPV4 CIDR block 10.0.0.0/24, but now
there is a requirement of hosting a few more resources to that VPC. As per his knowledge, he is
thinking of creating a new VPC with a greater range. Could you suggest to him a better way that
should be reliable?
A.
Delete the existing subnets in the VPC and create new Subnets in VPC.
B.
He is thinking of the right approach.
C.
You can create new VPC and connect old VPC with a new one.
D.
You can expand existing VPC by adding Secondary CIDR to your current VPC
Correct Answer - D
Options A, B, C are incorrect because it is not reliable to go for this type of approach as VPC to
VPC connection will take new resources like VPC Peering. Creating a new VPC or Subnet is also not
suggested.
- Option D is correct because you can associate Secondary CIDR to your current VPC to accommodate
more hosts.
Question 54
You have an application running on EC2. The operation fails when the application tries to upload a 7
GB file to S3. What could be the reason for failure, and what could be the solution?
A.
With a single PUT operation, you can upload objects up to 5 GB in size. Use multi-part upload for
larger file uploads.
B.
EC2 is designed to work best with EBS volumes. Use EBS Provisioned IOPs and use an Amazon
EBS-optimized instance.
C.
NAT gateway only supports data transfers going out upto 5 GB. Use EBS Provisioned IOPs and use an
Amazon EBS-optimized instance.
D.
VPC Endpoints only supports data transfers going out upto 5 GB. Use EBS Provisioned IOPs and use an
Amazon EBS-optimized instance.
Answer: A
AWS recommends using multi-part uploads for larger objects.
Option B, Amazon EBS is a storage for the drives of your virtual machines. It stores data as blocks
of the same size and organizes them through a hierarchy similar to a traditional file system. EBS is
not a standalone storage service like Amazon S3. So you can use it only in combination with Amazon
EC2.
Objects can be stored on EBS volumes, but not cost-effective and not highly resilient and
fault-tolerant compared to S3.
Options C and D are incorrect. NAT Gateway ad VPC endpoints do not have any data transfer
limitations.
Question 55
You are a solutions architect working for a media company that produces and stores image and video
content that is sold as stock content to other companies that wish to use your stock content in
their web and mobile apps. You are storing your stock content in S3 and you need to optimize for
cost. Some of your images are small, less than 128 KB in size. However, most of your stock content
is much larger. The amount of content you manage is very large, with over 1 million objects in S3.
These objects have varying access patterns. Some are accessed frequently, while others are accessed
very infrequently. Also, the access patterns for the stock objects change over time.
Which S3 storage class should you choose for your stock content to optimize your costs while also
providing the best overall performance?
A.
S3 Standard
B.
S3 Standard-IA
C.
S3 Intelligent-Tiering
D.
S3 One Zone-IA
Correct Answer: C
- Option A is incorrect. S3 Standard tiering is not a cost-optimized solution. You have a lot of
objects and many of them are accessed very infrequently. With S3 Standard, all objects are charged
at the same rate, regardless of how often they are accessed.
- Option B is incorrect. S3 Standard-IA, or Infrequent Access, would be a cost-optimized solution
for less frequently accessed objects. However, retrieval latency will not be optimal for
frequently accessed objects.
- Option C is correct. S3 Intelligent-Tiering gives you the ability to have S3 monitor the access
patterns of your objects and move objects across the various storage tiers based on the relevant
access patterns. This will give you both cost and performance optimization. Also, smaller files (
less than 128 KB) can be stored in S3 Intelligent-Tiering but they will always remain in the S3
Standard storage class.
- Option D is incorrect. S3 One Zone-IA is used for files that are easily recreated if the one AZ
becomes unavailable. Also, an infrequent access tier such as S3 One Zone-IA would be a
cost-optimized solution for less frequently accessed objects. However, retrieval latency will not
be optimal for frequently accessed objects.
Question 56
You have an application that writes application logs to version enabled S3 bucket. Each object has
multiple versions attached to it. After 60 days, the application deletes the objects in S3 through
DELETE API on the object. However, in next month’s bill, you see charges for S3 usage on the bucket.
What could have caused this?
A.
DELETE API call on the object only deletes latest version.
B.
DELETE API call on the object does not delete the actual object, but places delete marker on the
object.
C.
DELETE API call moves the object and its versions to S3 recycle bin from where the object can be
restored till 30 days.
D.
DELETE API for all versions of the object in version enabled bucket cannot be done through API. It
can be only done by bucket owners through the console.
Answer: B
When versioning is enabled, a simple DELETE cannot permanently delete an object.
Instead, Amazon S3 inserts a delete marker in the bucket, and that marker becomes the current
version of the object with a new ID. When you try to GET an object whose current version is a
delete marker, Amazon S3 behaves as though the object has been deleted (even though it has not been
erased) and returns a 404 error.
The following figure shows that a simple DELETE does not actually remove the specified object.
Instead, Amazon S3 inserts a delete marker.
To permanently delete versioned objects, you must use DELETE Object versioned.
The following figure shows that deleting a specified object version permanently removes that
object.
- Option A is not true. DELETE call on an object does not delete the latest version unless the
DELETE call is made with the latest version id.
- Option C is not true. AWS S3 does not have to recycle bin.
- Option D is not true. DELETE call on a versioned object can be made through API by providing the
version id of the object’s version to be deleted.
Question 57
You are uploading multiple files ranging 10 GB – 20 GB in size to the AWS S3 bucket by using a
multi-part upload from an application on EC2. Once the upload is complete, you would like to notify
a group of people who do not have AWS IAM accounts. How can you achieve this? (Select TWO)
A.
Use S3 event notification and configure Lambda function which sends email using AWS SES non-sandbox.
B.
Use S3 event notification and configure SNS, which sends email to subscribed email addresses.
C.
Write a custom script on your application side to poll S3 bucket for new files and send email
through SES non-sandbox.
D.
Write a custom script on your application side to poll S3 bucket for new files and send email
through SES sandbox.
Answer: A and B
The Amazon S3 notification feature enables you to receive notifications when certain events happen
in your bucket. To enable notifications, you must first add a notification configuration identifying
the events you want Amazon S3 to publish and the destinations where you want Amazon S3 to send the
event notifications.
AWS Simple Email Service (SES) is a cost-effective email service built on the reliable and scalable
infrastructure that Amazon.com developed to serve its own customer base. With Amazon SES, you can
send transactional emails, marketing messages, or any other type of high-quality content.
While your account is in the sandbox, you can use all of the features of Amazon SES. However, when
your account is in the sandbox, we apply the following restrictions to your account:
You can only send mail to verified email addresses and domains or to the Amazon SES mailbox
simulator.
You can only send mail from verified email addresses and domains.
- Option A triggers Lambda function which uses non-sandbox SES to send email to people who does not
have an AWS IAM account nor are verified in AWS SES.
- Option B is correct as it triggers SNS.
Options C and D are incorrect because they needs compute resources to monitor S3 for new files
continuously.
Question 58
You are planning to launch the AWS ECS container instance. You would like to set the ECS container
agent configuration during the ECS container instance initial launch. What should you perform to
configure container agent information?
A.
Set configuration in the ECS metadata parameter during cluster creation.
B.
Set configuration in the user data parameter of EC2 instance.
C.
Define configuration in the task definition.
D.
Define configuration in the service definition.
Answer: B
When you launch an Amazon ECS container instance, you have the option of passing user data to the
instance. The data can be used to perform common automated configuration tasks and even run scripts
when the instance boots. For Amazon ECS, the most common use cases for user data are to pass
configuration information to the Docker daemon and the Amazon ECS container agent.
Question 59
You are working for an organization which is actively using AWS. They have noticed that few AWS ECS
clusters are running and they do not know who and when the clusters are created. They tasked you to
find out the logs regarding this. What will you do?
A.
Check CloudWatch event logs.
B.
Check CloudTrail logs.
C.
Check CloudWatch metrics dashboard.
D.
Check Trusted Advisor.
Answer: B
Amazon ECS is integrated with AWS CloudTrail, a service that provides a record of actions taken by a
user, role, or AWS service in Amazon ECS. CloudTrail captures all API calls for Amazon ECS as
events, including calls from the Amazon ECS console and from code calls to the Amazon ECS
APIs.
Options A and C are for monitoring the ECS resources, not for the API actions made on ECS. You can
monitor your Amazon ECS resources using Amazon CloudWatch, which collects and processes raw data
from Amazon ECS into readable, near real-time metrics.
Question 60
Which of the following are valid integration sources for API Gateway? (choose 3 options)
A.
Public facing HTTP-based endpoints outside AWS network.
B.
Lambda functions from another account.
C.
Database connections on internet outside AWS network.
D.
VPC Link
E.
SFTP connection
Answer: A, B, D
- Option A is correct. AWS API Gateway can integrate with any HTTP-based endpoints available over
the internet.
Q: With what backends can Amazon API Gateway communicate?
Amazon API Gateway can execute AWS Lambda functions in your account, start AWS Step Functions state
machines, or call HTTP endpoints hosted on AWS Elastic Beanstalk, Amazon EC2, and also non-AWS
hosted HTTP based operations that are accessible via the public Internet. API Gateway also allows
you to specify a mapping template to generate static content to be returned, helping you mock your
APIs before the backend is ready. You can also integrate API Gateway with other AWS services
directly. For example, you could expose an API method in API Gateway that sends data directly to
Amazon Kinesis.
- Option B is correct. AWS can use Lambda function from another account as an integration
type.
- Option C is incorrect. AWS API gateway can connect to AWS services, making proxy calls only to
their respective AWS APIs. There is no integration type for database connections directly from API
Gateway. You can use the Lambda function to connect with the database and make Lambda as an
integration type for API Gateway.
- Option D is correct. AWS has introduced VPC Link, a way to connect to the resources within a
private VPC.
Question 61
You are a solutions architect working for a financial services firm. Your firm requires a very low
latency response time for requests via API Gateway and Lambda integration to your securities master
database. The securities master database, housed in Aurora, contains data about all of the
securities your firm trades. The data consists of the security ticker, the trading exchange, trading
partner firm for the security, etc. As this securities data is relatively static, you can improve
the performance of your API Gateway REST endpoint by using API Gateway caching. Your REST API calls
for equity security request types and fixed income security request types to be cached separately.
Which of the following options is the most efficient way to separate your cache responses via
request type using API Gateway caching?
A.
Payload compression
B.
Custom domain name
C.
API Stage
D.
Query string
Correct Answer: D
- Option A is incorrect. Payload compression is used to compress and decompress the payload to and
from your API Gateway. It is not used to separate cache responses.
- Option B is incorrect. Custom domain names are used to provide more readable URLs for the users of
your AIPs. They are not used to separate cache responses.
- Option C is incorrect. An API stage is used to create a name for your API deployments. They are
used to deploy your API in an optimal way.
- Option D is correct. You can use your query string parameters as part of your cache key. This
allows you to separate cache responses for equity requests from fixed income request
responses.
Question 62
You are a solutions architect working for a healthcare provider. Your company uses REST APIs to
expose critical patient data to internal front-end systems used by doctors and nurses. The data for
your patient information is stored in Aurora.
How can you ensure that your patient data REST endpoint is only accessed by your authorized internal
users? (Select TWO)
A.
Run your Aurora DB cluster on an EC2 instance in a private subnet
B.
Use a Gateway VPC Endpoint to make your REST endpoint private and only accessible from within your
VPC
C.
Use IAM resource policies to restrict access to your REST APIs by adding the aws:SourceVpce
condition to the API Gateway resource policy
D.
Use an Interface VPC Endpoint to make your REST endpoint private and only accessible from within
your VPC and through your VPC endpoint.
E.
Use IAM resource policies to restrict access to your REST APIs by adding the aws:SourceArn condition
to the API Gateway resource policy
Correct Answers: C and D
- Option A is incorrect. Controlling access to your back-end database running on Aurora will not
restrict access to your API Gateway REST endpoint. Access to your API Gateway REST endpoint must
be controlled at the API Gateway and VPC level.
- Option B is incorrect. The Gateway VPC Endpoint is only used for the S3 and DynamoDB
services.
- Option C is correct. You can make your REST APIs private by using the aws:SourceVpce condition in
your API Gateway resource policy to restrict access to only your VPC Endpoint.
- Option D is correct. Use a VPC Interface Endpoint to restrict access to your REST APIs to traffic
that arrives via the VPC Endpoint.
- Option E is incorrect. The aws:SourceArn condition key is not used to restrict access to traffic
that arrives via the VPC Endpoint.
Question 63
Which of the following are AWS CloudFront events that can trigger AWS Lambda@edge function? (choose
3 options)
A.
Viewer Request
B.
CloudFront Cache
C.
Sender Request
D.
Origin Request
E.
Origin Response
Answer: A, D, E
Question 64
You created an AWS Lambda function to process files uploaded to AWS S3 bucket. Lambda function
started receiving requests and working properly. You have changed the code and uploaded new version
of code to AWS Lambda function. What will happen to the requests sent right after the AWS lambda
function update?
A.
Requests will queue until the changes are fully propagated. You could experience up to 5 minutes of
wait during this period.
B.
Requests will be served by old version till you enable new version as latest.
C.
When you have multiple versions of Lambda function, in the code you need to define which version of
function to be used. Otherwise, requests would fail.
D.
Requests might be served by old or new version for a brief period of less than one minute
Answer: D
- Option A is not a valid statement. It will not continually queue automatically or 5 minute wait
time.
- Option B is not correct. By default, whenever you update the code, it updates the LATEST
version.
- Option C is not correct. There is no need to define in code which version to be used. However, you
can define which version to be used at the source which triggers Lambda function by providing
version qualified ARN if you have published version.
Question 65
Which of the following services use event source mappings to invoke AWS Lambda functions? (Select
THREE)