400+ Câu hỏi luyện thi chứng chỉ AWS Certified Solutions Architect Associate (SAA-C03) - Phần 6
aws
aws certification
cloud computing
solutions architect
saa c03
aws exam
practice test
Question 1
A manufacturing firm has a large number of smart devices installed in various locations worldwide.
Hourly logs from these devices are stored in an Amazon S3 bucket. Management is looking for
comprehensive dashboards which should incorporate usages of these devices and forecast usage trends
for these devices.
Which tool is the best suited to get this required dashboard?
A.
Use S3 as a source for Amazon QuickSight and create dashboards for usage and forecast trends
B.
Use S3 as a source for Amazon Redshift and create dashboards for usage and forecast trends
C.
Copy data from Amazon S3 to Amazon DynamoDB. Use Amazon DynamoDB as a source for Amazon QuickSight
and create dashboards for usage and forecast trends
D.
Copy data from Amazon S3 to Amazon RDS. Use Amazon RDS as a source for Amazon QuickSight and create
dashboards for usage and forecast trends
Correct Answer: A
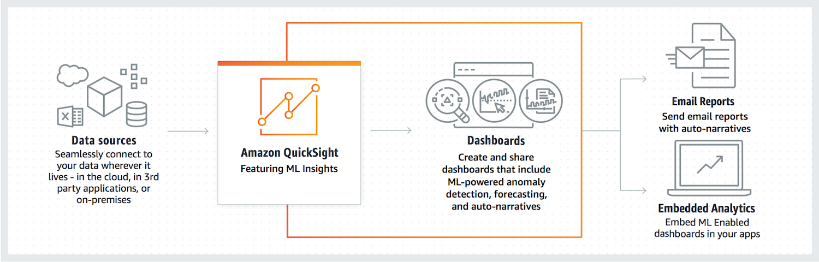
Amazon QuickSight is a business analytical tool that can be used to build visualizations and perform
ad-hoc analysis integrating with ML insights. It can connect to various data sources which can
either be in the AWS cloud or in the on-premises network or in any third-party applications.
For AWS it supports various services such as Amazon RDS, Amazon Aurora, Amazon Redshift, Amazon
Athena, and Amazon S3 as sources. Based on this data, Amazon QuickSight creates custom dashboards
that include anomaly detections, forecasting, and auto-narratives.
In the above case, logs from the devices are stored in Amazon S3. Amazon QuickSight can be used to
fetch this data, perform analysis, and generate comprehensive custom dashboards for device usage as
well as forecasting device usage.
- Option B is incorrect as Amazon Redshift is a data warehousing service for analyzing structured or
semi-structured data. It is not a useful tool for creating dashboards.
- Option C is incorrect as Amazon S3 can be used directly as a source for Amazon QuickSight. There
is no need to copy data from Amazon S3 to Amazon DynamoDB.
- Option D is incorrect as Amazon S3 can be used directly as a source for Amazon QuickSight. There
is no need to copy data from Amazon S3 to Amazon RDS.
Question 2
A company has launched Amazon EC2 instances in an Auto Scaling group for deploying a web
application. The Operations Team is looking to capture custom metrics for this application from all
the instances. These metrics should be viewed as aggregated metrics for all instances in an Auto
Scaling group.
What configuration can be implemented to get the metrics as required?
A.
Use Amazon CloudWatch metrics with detail monitoring enabled and send to CloudWatch console where
all the metrics for an Auto Scaling group will be aggregated by default.
B.
Install a unified CloudWatch agent on all Amazon EC2 instances in an Auto Scaling group and use "
aggregation_dimensions" in an agent configuration file to aggregate metrics for all instances
C.
Install unified CloudWatch agent on all Amazon EC2 instances in an Auto Scaling group and use
“append-config” in an agent configuration file to aggregate metrics for all instances
D.
Use Amazon CloudWatch metrics with detail monitoring enabled and create a single Dashboard to
display metrics from all the instances
Correct Answer: B
Unified CloudWatch agent can be installed on Amazon EC2 instance for the following cases,
The unified CloudWatch agent supports custom metric collection, and the "aggregation_dimensions"
configuration allows aggregation of metrics across instances in the Auto Scaling group, which meets
the requirement of viewing aggregated metrics.
Collect custom metrics from the applications on the Amazon EC2 instance using StatsD and collectd
protocols.
Collect logs from EC2 instances or from on-premises servers for both Windows and Linux OS.
In the case of the Instances which are part of an Auto Scaling group, metrics from all the instances
can be aggregated using "aggregation_dimensions" in the agent configuration file.
- Option A is incorrect as for retrieving custom level metrics for applications on an Amazon EC2
Instance, a unified CloudWatch agent is required. Amazon CloudWatch metrics with detail monitoring
will be capturing metrics every 1 minute but it won’t capture custom application metrics.
- Option C is incorrect as the append-config configuration in an agent configuration file can be
used to have multiple CloudWatch agent configuration files. This command is not suitable for
aggregate metrics from all the instances in an Auto Scaling group.
- Option D is incorrect as for retrieving custom-level metrics for applications on an Amazon EC2
Instance, a unified CloudWatch agent is required. Dashboards can be used to create a customized
view of the metrics, but they won’t aggregate metrics from the instance in an Auto Scaling
Group.
Question 3
A critical web application is deployed on multiple Amazon EC2 instances which are part of an
Autoscaling group. One of the Amazon EC2 instances in the group needs to have a software upgrade.
The Operations Team is looking for your suggestions to advise for this upgrade without impacting
another instance in the group. Post upgrade, the same instance should be part of the Auto Scaling
group.
What steps can be initiated to complete this upgrade?
A.
Hibernate the instance and perform upgrade in offline mode. Post upgrade, start the instance which
will be part of the same auto-scaling group
B.
Use cooldown timers to perform upgrades on the instance. Post cooldown timers’ instances would be
part of the same auto-scaling group
C.
Put the instance in Standby mode. Post upgrade, move instance back to InService mode. It will be
part of the same auto-scaling group
D.
Use lifecycle hooks to perform upgrades on the instance. Once these timers expire, the instance
would be part of the same auto-scaling group
Correct Answer: C
Amazon EC2 instances in an Auto Scaling group can be moved to Standby mode from InService mode. In
standby mode, software upgrade or troubleshooting can be performed on the instance. Post upgrade,
instances can be again put in InService mode back in the same Auto Scaling group. With instance in a
standby mode, Auto Scaling does not terminate this group as a part of health checks or scale-in
events.
- Option A is incorrect as Hibernate is not supported on an Amazon EC2 instance which is part of an
Auto Scaling group. When an instance in an Auto Scaling group is hibernated, the Auto-scaling
group marks the hibernated instance as unhealthy, terminates it, and launches a new instance.
Hibernating an instance will not be useful for upgrading software on an instance.
- Option B is incorrect as cooldown timers are the timers that will prevent launching or terminating
instances in an Auto Scaling group till previous activities of launch or termination are
completed. This timer provides a time for an instance to be in an active state before the Auto
Scaling group adds a new one. This timer would not be useful for troubleshooting an
instance.
- Option D is incorrect as a Lifecycle hook can help to perform custom actions such as data backups
before an instance is terminated or to perform software instances once an instance is launched.
This hook is not useful for upgrading a running instance in an Auto Scaling Group and adding back
to the original group.
Question 4
An eCommerce website is hosted on two EC2 instances that sit behind an Elastic Load Balancer. The
response time of the website has slowed dramatically. The analytics team found that one of the EC2
instances failed, leaving only one instance running. What is the best course of action to prevent
this from happening in the future?
A.
Change the instance size to the maximum available to compensate for the failure.
B.
Use CloudWatch to monitor the instances via VPC Flow Logs.
C.
Configure the ELB to perform health checks on the EC2 instances and implement auto-scaling.
D.
Replicate the existing configuration in several regions for failover
Correct Answer: C
- Option C is correct. Using the elastic load balancer to perform health checks will determine
whether or not to remove a non- or underperforming instance and have the auto-scaling group launch
a new instance.
- Option A is incorrect because increasing the instance size doesn’t prevent the failure of one or
both instances. Therefore the website can still become slow or unavailable.
- Option B is incorrect because monitoring the VPC flow logs for the VPC will capture VPC traffic,
not traffic for the EC2 instance.
- Option D is incorrect because replicating the same two instance deployment may not prevent the
failure of instances and could still result in the website becoming slow or unavailable.
Question 5
A third-party vendor based in an on-premises location needs to have temporary connectivity to
database servers launched in a single Amazon VPC. The proposed connectivity for these few users
should be secure, and access should be provided only to authenticated users.
Which connectivity option can be deployed for this requirement in the most cost-effective way?
A.
Deploy an AWS Client VPN from third-party vendor’s client machines to access databases in Amazon VPC
B.
Deploy AWS Direct Connect connectivity from the on-premises network to AWS
C.
Deploy an AWS Managed VPN connectivity to a Virtual Private gateway from an on-premises network
D.
Deploy an AWS Managed VPN connectivity to the AWS Transit gateway from the on-premises network
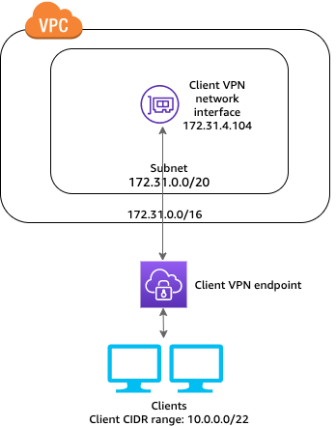
Correct Answer: A
AWS Client VPN is a managed client-based VPN for having secure access to resources in VPC as well as
resources in on-premises networks. Clients looking for access to these resources use an
OpenVPN-based VPN client. Access to resources in VPC is secure over TLS and clients are
authenticated before access is granted.
In the above case, since third-party vendors from on-premises need secure temporary connectivity to
resources in VPC, AWS Client VPN can be used to provide this connectivity.
- Option B is incorrect as since there are only a few users accessing resources from a single VPC
for temporary purposes, using AWS Direct Connect will be costly and will require a longer time for
deployment.
- Option C is incorrect as using Managed VPN for a few users will be costlier than using AWS Client
VPN for those few users accessing databases from VPC.
- Option D is incorrect as Connectivity to AWS Transit gateway will be useful for accessing
resources from multiple VPCs. Also, since only a few users access resources from a single VPC for
temporary purposes, AWS Client VPN is a cost-effective option.
Question 6
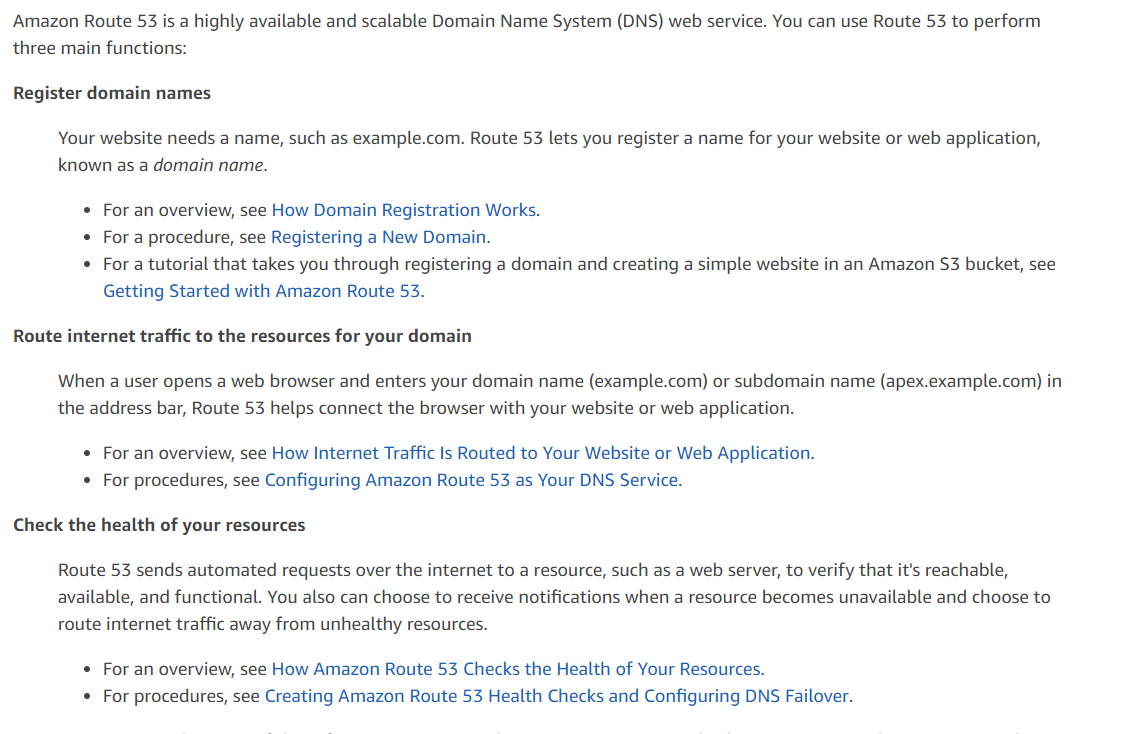
Which of the following are the main functions of AWS Route 53?
A.
Register domain names
B.
Route internet traffic to the resources for your domain
C.
Load-balance traffic among geographically-distributed web servers.
D.
Check the health of your resources
E.
All of the above
Answer: E
Associating multiple IP addresses with a single record is often used for balancing the load of
geographically-distributed web servers. Amazon Route 53 allows you to list multiple IP addresses for
an A record and responds to DNS requests with the list of all configured IP addresses.
Question 7
A company is using microservices-based applications using Amazon ECS for an online shopping
application. For different services, multiple tasks are created in a container using the EC2 launch
type. The security team is looking for some specific security controls for the tasks in the
containers along with granular network monitoring using various tools for each task.
What networking mode configuration can be considered with Amazon ECS to meet this requirement?
A.
Use host networking mode for Amazon ECS tasks
B.
By default, an elastic network interface (ENI) with a primary private IP address is assigned to each
task
C.
Use awsvpc networking mode for Amazon ECS tasks
D.
Use bridge networking mode for Amazon ECS tasks
Correct Answer: C
Amazon ECS with EC2 launch type supports the following networking mode,
Host Mode: This is a basic mode in which the networking of the container is directly tied to the
underlying host.
Bridge Mode: In this mode, a network bridge is created between host and container networking. This
bridge mode allows the remapping of ports between host and container ports.
None mode: In this mode, networking is not attached to the container. With this mode, containers do
not have external connectivity.
AWSVPC Mode: In this mode, each task is allocated a separate ENI (Elastic Network Interface). Each
Task will receive a separate IP address and a separate security group can be assigned to each ENI.
This helps to have separate security policies for each task and helps to get granular monitoring for
traffic flowing via each task.
In the above scenario, using AWSVPC mode, the security team can assign different security policies
for each task as well as monitor traffic from each task distinctly.
- Option A is incorrect as with host networking mode, networking of containers uses the network
interface of the Amazon EC2 instance on which it's running. This is a basic network type and each
task does not get assigned a different networking mode.
- Option B is incorrect as an elastic network interface (ENI) with the primary private IP address is
assigned for Fargate task networking, not for ECS task networking.
- Option D is incorrect as Bridge mode uses Docker’s built-in virtual network. Containers connected
to the bridge can communicate with others. Containers using different bridges cannot communicate
with each other while providing isolation. It does not provide each task with a separate
networking mode that can be used for security controls and network monitoring.
Question 8
A start-up firm is planning to deploy container-based applications using Amazon ECS. The firm is
looking for the least latency from on-premises networks to the workloads in the containers. The
proposed solution should be scalable and should support consistent high CPU and memory requirements.
What deployment can be implemented for this purpose?
A.
Create a Fargate launch type with Amazon ECS and deploy it in the AWS Outpost
B.
Create a Fargate launch type with Amazon ECS and deploy it in the AWS Local Zone
C.
Create an EC2 launch type with Amazon ECS and deploy it in the AWS Local Zone
D.
Create an EC2 launch type with Amazon ECS and deploy it in the AWS Outpost
Correct Answer: D
AWS Outpost extends AWS infrastructure and services to on-premises environments, which provides the
lowest latency when connecting from on-premises to AWS workloads. By deploying EC2 launch type with
Amazon ECS on AWS Outpost, the startup firm can leverage scalable EC2 instances that support high
CPU and memory requirements, while maintaining a low-latency connection to their on-premises
networks.
- Option A is incorrect as the AWS Fargate launch type is not supported with Amazon ECS deployed in
the AWS Outpost.
- Option B is incorrect as the AWS Fargate launch type is not supported with Amazon ECS deployed in
the AWS Local Zone.
- Option C is incorrect as with AWS Local Zones, other services such as Amazon EC2 instances, Amazon
FSx file servers, and Application Load Balancers need to be implemented before deploying Amazon
ECS in the Local Zones. With AWS Outposts, native AWS services and infrastructure is enabled which
makes it an ideal choice for low latency from on-premises networks.
Question 9
A new application is deployed in an Amazon EC2 instance which is launched in a private subnet of
Amazon VPC. This application will be fetching data from Amazon S3 as well as from Amazon DynamoDB.
The communication between the Amazon EC2 instance and Amazon S3 as well as with Amazon DynamoDB
should be secure and should not transverse over internet links. The connectivity should also support
accessing data in Amazon S3 from an on-premises network in the future.
What design can be implemented to have secure connectivity?
A.
Access Amazon DynamoDB from an instance in a private subnet using a gateway endpoint. Access Amazon
S3 from an instance in a private subnet using an interface endpoint
B.
Access Amazon S3 and Amazon DynamoDB from an instance in a private subnet using a private NAT
gateway
C.
Access Amazon S3 and Amazon DynamoDB from an instance in a private subnet using a public NAT gateway
D.
Access Amazon S3 and Amazon DynamoDB from an instance in a private subnet using a gateway endpoint
Correct Answer: D
This is the correct and most recommended solution. Gateway endpoints are specifically designed for
Amazon S3 and DynamoDB and allow secure, private connectivity from resources in a VPC without
requiring an internet gateway, NAT device, or VPN. They ensure that traffic to these services
remains within the AWS network, enhancing both security and performance. Additionally, gateway
endpoints are cost-effective and easy to manage, making them ideal for scenarios where secure and
scalable access to S3 and DynamoDB is required from private subnets.
- Option A is incorrect. While using a gateway endpoint for DynamoDB is appropriate, using an
interface endpoint for Amazon S3 is not. Amazon S3 is one of the two AWS services (along with
DynamoDB) that supports gateway endpoints, not interface endpoints. Interface endpoints are based
on AWS PrivateLink and are used for services like Secrets Manager, SSM, and others that do not
support gateway endpoints. Therefore, this configuration would not provide the intended private
connectivity to S3 and would not meet the requirement of avoiding internet traversal.
- Option B is incorrect as a private NAT gateway can be used to have communication between VPCs or
with on-premises networks. It is not an option to have communication from a private subnet in a
VPC to an Amazon S3 or Amazon DynamoDB.
- Option C is incorrect as with a public NAT Gateway, traffic will traverse over the
Internet.
Question 10
A static website named ‘whizexample’ is hosted using the Amazon S3 bucket. JavaScript on the web
pages stored in the Amazon S3 bucket needs to make authenticated GET requests to the bucket using
the Amazon S3 API endpoint for the bucket, example.s3.us-west-1.amazonaws.com.
What additional configuration will be required for allowing this access?
A.
Create CORS configuration with Access-Control-Request-Header as GET using JSON and add CORS
configuration to the bucket from the S3 console
B.
Create CORS configuration with Access-Control-Request-Method as GET using JSON and add CORS
configuration to the bucket from the S3 console
C.
Create CORS configuration with Access-Control-Request-Method as GET using XML and add CORS
configuration to the bucket from the S3 console
D.
Create CORS configuration with Access-Control-Request-Header as GET using XML and add CORS
configuration to the bucket from the S3 console
Correct Answer: B
CORS (Cross Origin resource sharing) is a configuration that allows web applications deployed in one
domain to interact with applications in different domains. Enabling CORS on an S3 bucket selectively
allows content in the S3 bucket to be accessed.
In the above scenario, when CORS is not enabled, JavaScript will not be able to access content in
the S3 bucket using the S3 API endpoint. To allow this access, CORS configuration using JSON needs
to be created and added to the S3 bucket from the S3 console.
CORS can be enabled with the following settings,
Access-Control-Allow-Origin
Access-Control-Allow-Methods
Access-Control-Allow-Headers
For successful access, Origin, Methods, and Headers from the requestor should match the values
defined in the configuration files. In the above scenario, the GET method should be added to the
CORS configuration file.
- Option A is incorrect as for GET requests, Access-Control-Allow-Methods should be defined in the
configuration file and not the Access-Control-Allow-Headers.
- Option C is incorrect as CORS configuration with XML is not supported while configuring CORS using
the S3 console.
- Option D is incorrect as for GET request, Access-Control-Allow-Methods should be defined in the
configuration file and not the Access-Control-Allow-Headers. CORS configuration with XML is not
supported while configuring CORS using the S3 console.
Question 11
The HR Team is using Amazon S3 buckets to save details of the employees. There are some users in the
Development team having an IAM policy with full access to S3 buckets. The HR head wants strict
access control for the HR bucket to ensure only legitimate members from the HR team have access to
the HR bucket. The policy should be applicable when new users are created with the IAM policy of
full access to S3 buckets.
What access control can be created for this purpose with the least admin work?
A.
Create an S3 bucket policy for the HR bucket with explicit ‘deny all’ to Principal elements (users
and roles) other than users who require access to the Amazon S3 bucket
B.
Create an S3 bucket policy for the HR bucket with explicit ‘deny all’ to Principal (only users)
other than users who require access to the Amazon S3 bucket
C.
Create an S3 bucket policy for the HR bucket restricting access only to the roles. Create a role
with access permissions to the Amazon S3 bucket. HR Team users who require access to the bucket can
assume this role
D.
Create an S3 bucket policy for the HR bucket with explicit deny to NotPrincipal element (users and
roles) which will match all users required to access and in turn deny all other user’s access to the
bucket
Correct Answer: C
When an S3 bucket policy is created with permission granting only to the roles, specific users
assuming this role can be able to access this bucket.
Users having an IAM policy with full access to the Amazon S3 bucket will be denied access to the
Amazon S3 bucket with this bucket policy. This bucket policy can be implemented using “Condition” in
a policy statement.
When new users with full access granted by IAM policy are created, there is a need to modify S3
bucket policy which grants access based upon users. When a bucket policy is created using roles,
additional maintenance work of modifying bucket policy is not required.
- Option A is incorrect as any new users or roles who are granted IAM users’ policy of full access
to the Amazon S3, will be able to access all the Amazon S3 buckets even though there is explicit
denial. This approach will require additional admin work to update the bucket policy.
- Option B is incorrect as any new users who are granted full access to the Amazon S3 will be able
to access all the Amazon S3 buckets even though there is explicit denial. This approach will
require additional admin work to update the bucket policy.
- Option D is incorrect as Roles consist of two ARN: role ARN and assume-role ARN. Assume-role ARN
is a variable name that should be matched using wildcard values and is not allowed with the
NotPrincipal element.
Question 12
An online retail store is using Amazon Redshift for its data warehousing service which analyses
petabytes sized data. Operations Head is concerned about the performance of the clusters and
requires near real-time data which should display performance data every minute.
What actions can be initiated to get this monitoring data?
A.
Create custom performance queries and view them in the Amazon CloudWatch console
B.
Create custom performance queries and view them in the Amazon Trusted Advisor console
C.
Create custom performance queries and view them in the Amazon CloudTrail console
D.
Create custom performance queries and view them in the Amazon Redshift console
Correct Answer: D
- Option A is incorrect. CloudWatch is used for monitoring physical aspects of the cluster, but
custom performance queries specific to Redshift are best viewed in the Redshift console.
- Option B is incorrect, as AWS Trusted Advisor does not display custom performance data for Amazon
Redshift clusters.
- Option C is incorrect, as Amazon CloudTrail will log user activity and cannot be used to display
performance data for Amazon Redshift.
- Option D is correct. Amazon Redshift provides performance metrics and data that can be viewed
directly in the Amazon Redshift console. This includes both CloudWatch metrics and query/load
performance data, which are updated every minute\
Question 13
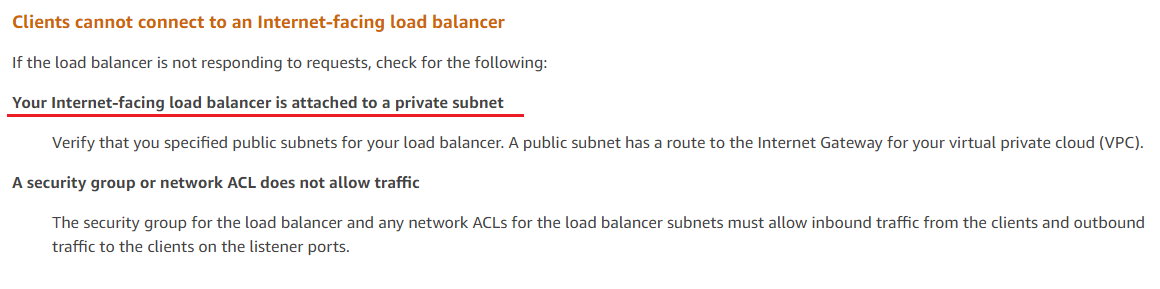
You have created a VPC with an application load balancer and selected two EC2 instances as targets.
However, when you are trying to make a request to the internet-facing load balancer, the request
fails. What could be the reason?
A.
The route table associated with the load balancer’s subnet does not have a route to the internet
gateway.
B.
Target EC2 instances are in a public subnet.
C.
There is no elastic IP address attached to the load balancer.
D.
Cross-zone load balancing is not enabled.
Answer: A
- Option A is correct because there must be a route in a route table to the internet gateway for
internet connectivity
- Option B is incorrect because this does not result in the failure mentioned in the
question.
- Option C is incorrect because any instances in the VPC must either have a public IP address or an
attached Elastic IP address. And for the internet-facing load balancer, AWS manages the underlying
IP addresses. So no need for an Elastic IP address.
- Option D is incorrect because cross-zone load balancing is not a reason to cause the
failure.
Question 14
An IT firm is planning to deploy microservices applications on Amazon ECS. The Project Team is
expecting occasional bursts in the application usage. Amazon ECS clusters should be scalable to meet
this burst without any manual interventions. The relational database for this application should
automatically scale to the application demand without any need to manage underlying instances.
What design can be recommended to have a scalable application?
A.
Create Amazon ECS clusters with Fargate launch type. For Database use, Amazon DynamoDB
B.
Create Amazon ECS clusters with Fargate launch type. For Database use, Amazon Aurora Serverless
C.
Create Amazon ECS clusters with EC2 launch type. For Database use, Amazon Aurora Serverless
D.
Create Amazon ECS clusters with EC2 launch type. For Database use, Amazon DynamoDB
Correct Answer: B
Amazon ECS Cluster with Fargate launch type automatically provisions resources such as Amazon EC2 as
per application demands. It automatically handles cluster optimization without any manual
intervention.
Amazon Aurora Serverless is a relational database that provides on-demand auto-scaling database
configuration. For both Amazon ECS with Fargate launch type and Aurora Serverless, there is no need
to manage the underlying infrastructure and is scalable to application demands.
- Option A is incorrect as Amazon DynamoDB is best suited for NO-SQL databases, not for relational
databases.
- Option C is incorrect as with EC2 launch type, users need to manually provision Amazon EC2
instances in ECS clusters as per growing demands.
- Option D is incorrect as with EC2 launch type, users need to manually provision Amazon EC2
instances in ECS clusters as per growing demands. Amazon DynamoDB is best suited for a NoSQL
database and not for relational databases.
Question 15
A start-up firm has deployed multiple Amazon EC2 instances for its web application. The operations
team is looking to retrieve ami-id for all these running instances. They are seeking your help with
the correct URL for this purpose.
What command can be used to get this detail?
A.
Use http://169.254.169.254/latest/meta-data/ami-id
B.
Use http://168.254.168.254/latest/metadata/ami-id
C.
Use http://169.254.169.254/latest/user-data/ami-id
D.
Use http://168.253.168.253/latest/dynamic/ami-id
Correct Answer: A
Instance Metadata consists of datas like instance-id, AMI ID, public hostname, IPv4 address, etc
which is available from the running Amazon EC2 instances.
URL http://169.254.169.254/latest/meta-data/ can be used to get these details from the running
instance. There are no charges for retrieving these details. There is no need to use the EC2 console
or CLI for getting these details. To get the AMI ID for the running
instance, http://169.254.169.254/latest/meta-data/ami-id can be used.
- Option B is incorrect as IP address 168.254.168.254 is invalid to retrieve meta-data or dynamic
data. Correct IP address is 169.254.169.254
- Option C is incorrect as user-data can be used to specify parameters or add configuration files
for the instance at launch time.
- Option D is incorrect as this is an invalid URL. http://169.254.169.254/latest/dynamic/ is the
correct URL. This can be used to retrieve instance identity documents that are created during the
launch of the instance and cannot be used to retrieve instances-id.
Question 16
You are the Solutions Architect for a health insurance service company that wants to start building
and supporting IoT devices for patients who recently signed new clauses in the contract. This will
open opportunities to expand its market but also introduces some restrictions. All services and data
involved have to guarantee HIPAA compliance and include in-transit encryption. Due to high
sensitivity data, bypassing the internet is crucial. The architecture uses already ELBs. They want
to avoid DNS re-configuration and IP address caching when it comes to the IoT devices. What
combination of services may be the closest option to address this challenge?
A.
AWS ELBs, AWS IoT, and Amazon Route53 configured with geolocation or latency routing policies. This
requires an interface endpoint (PrivateLink) for Route53 to stay inside the AWS backbone.
B.
AWS ELBs, AWS IoT, and AWS Global Accelerator which provisions two anycast static IP addresses.
C.
AWS ELBs, AWS IoT, and Amazon Route53 configured with geolocation or latency routing policies. This
does not require an interface endpoint (PrivateLink) because Route53 is inside the AWS backbone.
D.
AWS ELBs, AWS IoT, and AWS Global Accelerator which provisions one anycast static IP address.
Answer: B
AWS Global Accelerator allocates two IPv4 anycast static IP addresses and keeps the traffic inside
the AWS globally redundant network.
- Option A is incorrect because there is no interface endpoint for Amazon Route53.
- Option C is incorrect because Amazon Route53 is not inside the AWS backbone.
- Option D is incorrect because AWS Global Accelerator provides two anycast static IP
addresses.
Question 17
The fraud detection department in a financial analytics company using Amazon Web Services with
recommended configurations needs to transfer data from their POSIX-compliant file system (Lustre) to
an Amazon S3 bucket. In this context, which statement is correct from below? (Select TWO)
A.
AWS DataSync provides support for Amazon FSx for the Lustre file system
B.
Amazon FSx for Lustre integrates natively with Amazon S3.
C.
Amazon FSx for Windows File Server takes highly durable backups stored in S3.
D.
If you link your Amazon FSx for Lustre to an Amazon S3 data lake, your content will appear as
objects as soon as the attached block-storage is available.
Correct Answer: A and B
- Option A is correct because AWS DataSync supports Amazon FSx for Lustre file system.
- Option B is correct because there is the native integration of Amazon FSx for Lustre with Amazon
S3.
- Option C is incorrect because although the statement is correct, it does not apply to this
scenario.
- Option D is incorrect because when linking Amazon FSx file systems to Amazon S3, the content will
appear as files and directories instead of objects.
Question 18
As a Solutions Architect working with the systems and networking teams, you have been tasked with
providing disaster recovery (DR) and high-availability elements for a security planning document
that involves FSx for Windows. Which of the following statements are true about Amazon FSx for
Windows File Server? (Select TWO)
A.
Amazon FSx for Windows File Server offers instant regional failover, fault-isolating design, and
automatic traffic routing across multiple applications, multiple VPCs, accounts, or Regions.
B.
Amazon FSx for Windows File Server allows to access file systems from multiple Amazon Virtual
Private Clouds (VPCs), AWS accounts, and AWS Regions via VPC Peering or AWS Transit Gateway.
C.
Amazon FSx for Windows File Server offers single-AZ and multi-AZ deployment options with SSD and HDD
storage options.
D.
Direct Connect, VPN, VPC Peering, and AWS Transit Gateway are not supported.
E.
Amazon FSx for Windows File Server is a fully POSIX-compliant filesystem.
Correct Answers: B and C
You can share your file data sets across multiple applications, internal organizations, or
environments spanning multiple VPCs, accounts, or Regions using inter-VPC, inter-account, and
inter-Region access.
Single-AZ files ensure high availability within a single Availability Zone (AZ) by automatically
detecting and addressing component failures. In addition, Multi-AZ file systems provide high
availability and failover support across multiple Availability Zones by provisioning and maintaining
a standby file server in a separate Availability Zone within an AWS Region.
- Option A is incorrect because those benefits are part of the AWS Global Accelerator networking
service.
- Option D is incorrect because Direct Connect or VPN (on-premises) and VPC Peering or AWS Transit
Gateway are supported.
- Option E is incorrect because Amazon FSx for Windows File Server is not POSIX-compliant —Amazon
FSx for Luster is POSIX-compliant.
Question 19
While analyzing billions of web pages in a company, you have noticed some munging processes are
exceeding SLAs even after using X1e instances suitable for HPC applications. After monitoring logs,
trailing, and tracing data closely, you noticed that write operations involving S3 content
pre-processing causing 80% of the bottleneck. In comparison, read operations for post-processing and
LIST operations are together leading to the remaining 20% of congestion. Which two options are
recommended to increase performance in this scenario? (Select TWO)
A.
Migrate S3 files to an RDS database with write-optimized IOPS.
B.
Using Amazon S3 Transfer Acceleration, Multipart upload, parallelized reading via byte-range
fetches, and partitioned prefix for distributing key names as part of naming patterns.
C.
Instead of LIST operations, you can scale storage connections horizontally since Amazon S3 is a very
large distributed system similar to a decoupled parallel, single network endpoint. You can achieve
the best performance by issuing multiple concurrent requests to Amazon S3.
D.
Instead of LIST operations, you can build a search catalog to keep track of S3 metadata by using
other AWS services like Amazon DynamoDB or Amazon OpenSearch Service.
E.
Combining Amazon S3 and Amazon EC2 instances by migrating your current buckets to the region where
the instances are available. This will help to reduce network latency and data transfer costs.
Answers: B and D
The problem description highlights write operations having 80% of the impact when compared to read
operations. Amazon S3 Transfer Acceleration helps especially in this scenario along with multipart
upload.
X1 and X1e instances are memory-optimized instances designed for running large-scale and in-memory
applications in the AWS Cloud.
Generally, it is a recommended practice to benefit from byte-range fetches and appropriate
distributing key names. Another complex practice to avoid expensive LIST operations relies on a
search framework to keep track of all objects in an S3 bucket.
Lambda triggers are used to populate DynamoDB tables with object names and metadata when those
objects are put into Amazon S3 then OpenSearch Service is used to search for specific assets,
related metadata, and data classifications.
- Option A is incorrect because this option is not applicable as you would need to migrate the data
to a relational database in RDS.
- Option C is incorrect because the phrase does not make sense, especially considering that the
Amazon S3 service is exactly the opposite of a single network endpoint.
- Option E is incorrect because you cannot migrate an existing S3 bucket into another AWS Region,
rather create a new S3 bucket in the region and copy the data to it. However, the statement does
not solve the problem description.
Question 20
A multinational logistics company is looking to modernize its tracking and auditing system for
packages and shipments. They require a solution that provides immutable transaction history,
real-time visibility into data changes, and seamless integration with their existing AWS
infrastructure. Which AWS service would be most suitable for their use case?
A.
Amazon Neptune
B.
Amazon Quantum Ledger Database (Amazon QLDB)
C.
Amazon ElastiCache
D.
Amazon DynamoDB
Correct Answer: B
Amazon Quantum Ledger Database (Amazon QLDB) is the most suitable option for the logistics company's
requirements:
Immutable Transaction History: QLDB provides a fully managed, serverless, and scalable ledger
database service designed specifically to maintain a complete and verifiable history of all changes
to application data.
Real-time Visibility into Data Changes: QLDB allows for real-time visibility into data changes with
its ability to provide an immutable history of all transactions.
- Option A is incorrect because Amazon Neptune is a fully managed graph database service designed
for storing and querying highly connected data, such as social networks or recommendation engines.
It does not provide the built-in features necessary for maintaining an immutable transaction
history
- Option C is incorrect because Amazon ElastiCache is a fully managed in-memory caching service that
provides high-performance, scalable caching solutions. However, it is not designed to maintain
immutable transaction history or provide real-time visibility into data changes.
- Option D is incorrect because Amazon DynamoDB is a fully managed NoSQL database service designed
for high-performance, low-latency applications. It does not provide built-in features for
maintaining immutable transaction history or real-time visibility into data changes. While
DynamoDB Streams can capture changes to data, it does not offer the same level of immutability and
verifiability as Amazon QLDB.
Question 21
You are analyzing dynamic scaling activity defined to process messages from an Amazon SQS queue. You
are using a target tracking policy. CloudWatch alarms are meant to invoke the scaling policy.
However, you have noticed that the EC2 Auto Scaling group does not seem to be responding to a
CloudWatch alarm. Which option may cause it?
A.
Wrong CloudWatch metric is configured in the CloudWatch alarm.
B.
The Auto Scaling group is under the cooldown period.
C.
The minimum number of instances in the ASG is 0.
D.
The desired number of instances in the ASG is 0
Answer: B
The cooldown period is the amount of time to wait for a previous scaling activity to take effect is
called the cooldown period.
- Option A is incorrect because the CloudWatch alarm is already triggered so wrong CloudWatch metric
does not cause the problem.
- Option B is CORRECT because under the cooldown period, scaling activities will not be
triggered.
- Option C is incorrect because this option will not stop the ASG from adding/deleting
instances.
- Option D is incorrect because with the option, the ASG can still add/delete instances by adjusting
the desired number of instances.
Question 22
A project you are part of as a Solutions Architect has a latency-sensitive workload requirement
despite availability. You have to consider building high-performance networking for their VPCs to
operate based on SLAs already signed as part of the contract. Which two statements in this context
are correct? (Select TWO)
A.
A cluster placement group is suitable for this use case as long as the instances remain within a
single Availability Zone
B.
A cluster placement group is appropriate for this use case because of a higher per-flow throughput
limit of up to 10 Gbps except for the traffic over an AWS Direct Connect connection to on-premises
resources.
C.
You can move an instance from one placement group to another, but you cannot combine placement
groups.
D.
You can migrate an instance from one placement group to another and merge placement groups.
E.
A spread placement group is appropriate for this use case but if you start or launch an instance in
the group and there is insufficient unique hardware, the request fails and you have to try again.
Answers: A, C
- Option A is correct. Cluster placement groups are designed to provide low-latency, high-throughput
networking between instances within a single Availability Zone, making them suitable for
latency-sensitive workloads.
- Option C is correct. you can migrate instances between placement groups, but merging placement
groups is not supported
- Option B is incorrect because Cluster placement groups do provide higher per-flow throughput, but
the mention of AWS Direct Connect is irrelevant to the context of placement groups. The focus
should be on the performance within the VPC
- Option D is incorrect because you cannot merge placement groups.
- Option E is incorrect because a spread placement group is more appropriate for availability
scenarios.
Question 23
You are building a solution for a security company that requires real-time monitoring and analysis
of surveillance camera footage for detecting suspicious activities and intrusions. Which AWS service
do you suggest for securely handling the visual data stream originating from multiple cameras
dispersed across various locations?
A.
Implement Amazon Elastic Transcoder for securely facilitating real-time detection of suspicious
activities and intrusions
B.
Enable Amazon Rekognition Video for analyzing the video streams and to detect objects, activities
suitable for real-time video analysis and content moderation
C.
Use Amazon SageMaker to trigger real-time analysis and alerts based on video stream data
D.
Implement Amazon Kinesis Video Streams for securely facilitating real-time detection of suspicious
activities and intrusions
Correct Answer: D
Amazon Kinesis Video Streams is specifically designed for handling live video streams at scale,
providing features like automatic scaling, data retention policies, and integration with other AWS
services for real-time analytics and processing.
- Option A is incorrect because Amazon Elastic Transcoder is primarily used for transcoding media
files from one format to another. It does not provide real-time analysis capabilities required for
detecting suspicious activities and intrusions in surveillance camera footage.
- Option B is incorrect because Amazon Rekognition Video is a service for analyzing video content to
detect objects, activities, and persons of interest, but it is not designed for ingesting and
processing live video streams from multiple cameras in real-time.
- Option C is incorrect because Amazon SageMaker is a managed service for building, training, and
deploying machine learning models.It is suited for building custom machine learning models rather
than handling real-time video stream analysis for security purposes.
Question 24
A web application uses Amazon CloudFront to deliver its static and dynamic web content. You want to
customize the error page returned to the viewer when there is a problem with the origin server. For
example, if the origin server returns a 500 Internal Server Error, CloudFront should present a page
that you have prepared. How would you achieve this requirement in CloudFront?
A.
Modify the application to store custom error pages. CloudFront can cache these error pages
automatically.
B.
Create a new CloudFront distribution to fetch error pages. Configure the original CloudFront to use
the new one as its custom error responses.
C.
Put the static error pages in an S3 bucket. Create custom error responses for the HTTP 5xx status
code in the CloudFront distribution.
D.
Upload custom error pages to the CloudFront distribution. Return the error pages when there is a
server error.
Correct Answer – C
- Option A is incorrect because the custom error pages should be configured through CloudFront
instead of the application.
- Option B is incorrect because there is no need to create a new CloudFront distribution.
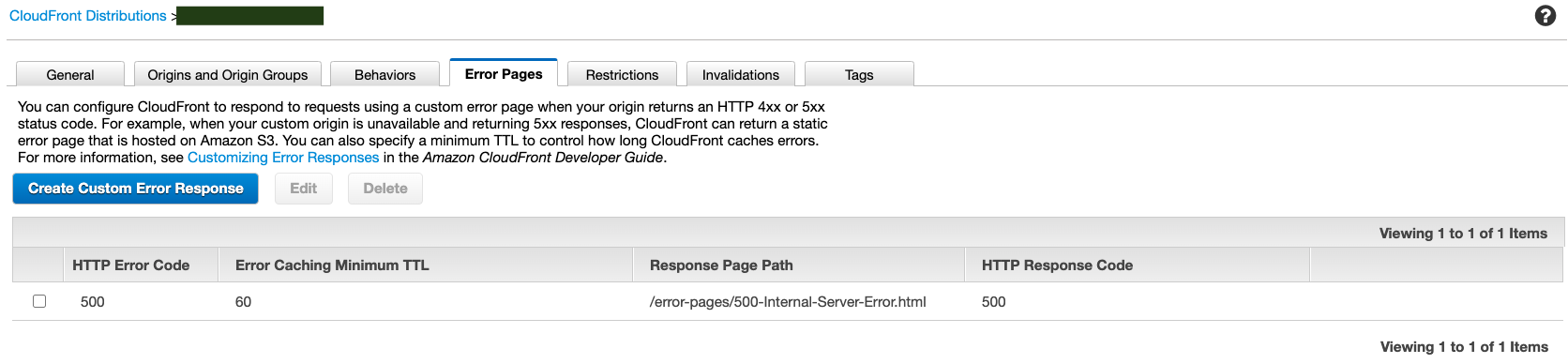
- Option C is CORRECT because the error pages can be customized through CloudFront. The following is
an example.
- Option D is incorrect because this is not how custom error responses are configured in CloudFront.
You cannot upload custom error pages to CloudFront directly.
Question 25
A CloudFront distribution delivers the web content of an application. Some static files are cached
in the CloudFront distribution, and the TTL is set to 1 day. You upgrade the origin server, and a
configuration JSON file is updated. However, when users access the website, the old file cached in
CloudFront is returned, and some services are impacted. How would you resolve this problem?
A.
Wait for a day and the file will be updated automatically.
B.
Invalidate the object in CloudFront so that the object is removed from the CloudFront edge cache.
C.
Modify the default TTL to be 0 in the CloudFront cache setting.
D.
Upgrade the origin application again and add a cache-control header to inform CloudFront to remove
the JSON file from its cache.
Correct Answer – B
- Option A is incorrect because, with the method, the service will be impacted for a day. A better
approach is to invalidate the object from the cache.
- Option B is CORRECT because invalidating the object removes it from the CloudFront edge cache to
return the correct file to the user. The issue can be resolved immediately with this
method.
- Option C is incorrect because the default TTL impacts all objects served by the CloudFront
distribution. In this scenario, there is only 1 file that needs to be cleared from the
cache.
- Option D is incorrect because the application has to be upgraded again, which is unnecessary. -
Option B is faster and simpler.
Question 26
You plan to migrate a Classic Load Balancer to an Application Load Balancer or a Network Load
Balancer. For the new load balancer listener, you need to define two rules that route requests based
on the host name in the host header. Then the traffic will be routed to two different target groups
accordingly. How would you configure the new load balancer?
A.
Create a Network Load Balancer and select the HTTP protocol in the listener. Configure the
host-based routing in the listener.
B.
Launch a new Network Load Balancer and choose the TCP protocol in its listener. Route the traffic
based on the path.
C.
Set up an Application Load Balancer and configure several rules in the listener to perform
path-based routing.
D.
Use an Application Load Balancer and configure host-based routing in the listener rule.
Correct Answer – D
- Option A is incorrect because, in this scenario, Application Load Balancer should be chosen as
Network Load Balancer that runs at the network layer and does not support host-based
routing.
- Option B is incorrect because, with Network Load Balancer, you cannot route the traffic based on
the host header.
- Option C is incorrect because path-based routing routes requests based on the URL in the requests.
However, the requests need to be routed based on the host header.
- Option D is CORRECT because you can define rules in the Application Load Balancer listener by
adding host conditions. Then the requests are forwarded based on the host field of the HTTP
header.
Question 27
Your team uses Amazon ECS to manage containers for several micro-services. To save cost, multiple
ECS tasks should run at a single container instance. When a task is launched, the host port should
be dynamically chosen from the container instance’s ephemeral port range. The ECS service should
select a load balancer that supports dynamic port mapping. Which types of load balancers are
appropriate?
A.
Application Load Balancer or Network Load Balancer.
B.
Application Load Balancer only.
C.
Network Load Balancer only.
D.
Application Load Balancer or Classic Load Balancer.
Correct Answer – A
- Option A is CORRECT because both Application Load Balancer and Network Load Balancer support
dynamic port mapping. You can configure the ECS service to use the load balancer, and a dynamic
port will be selected for each ECS task automatically. With Dynamic port mapping, multiple copies
of a task can run on the same instance.
Options B and C are incorrect: Please check the below references.
- Option D is incorrect because Classic Load Balancer does not support dynamic port mapping. With
Classic Load Balancer, you have to define the port mappings on a container instance
statically.
Question 28
You plan to manage API keys in AWS Secrets Manager. The keys need to be automatically rotated to be
compliant with the company policy. From Secrets Manager, applications can get the latest version of
the API credentials. How would you implement the rotation of keys?
A.
Use AWS Parameter Store to store and rotate the keys as Secrets Manager does not support it.
B.
Directly add multiple keys in Secrets Manager for rotation and the keys will be rotated every year
automatically.
C.
Customize the Lambda function that performs the rotation of secrets in Secrets Manager.
D.
Create two secrets in Secrets Manager to store two versions of the API credentials. Modify the
application to get one of them.
Correct Answer – C
- Option A is incorrect because Secrets Manager supports the key rotation for database credentials,
third-party services, etc.
- Option B is incorrect because Secrets Manager natively knows how to rotate secrets for supported
databases such as RDS. For other secret types, such as API keys, users need to customize the
Lambda rotation function.
- Option C is CORRECT because, for API keys, users must provide the code for the Lambda function
that rotates the secrets.
- Option D is incorrect because only one secret in Secrets Manager is required, and the application
should always get the latest version of the secret.
Question 29
Your organization starts to store RDS credentials in AWS Secrets Manager. To be compliant with
security regulations, all secrets stored in the Secrets Manager should automatically rotate. If
rotation is not enabled for a secret, your team should get an email notification. Which method is
the most appropriate?
A.
Configure AWS Secrets Manager to enable the rotation for all existing and new secrets.
B.
Create a CloudWatch Event rule that matches all events in Secrets Manager. Register an SNS topic as
its target to provide notifications.
C.
Enable Amazon GuardDuty that monitors services including Secrets Manager.
D.
Add the rule “secretsmanager-rotation-enabled-check” in AWS Config to check whether AWS Secrets
Manager has enabled the secret rotation. Register an SNS topic to provide notifications.
Correct Answer – D
- Option A is incorrect because there is no such configuration to enable rotation for all secrets.
The rotation is managed in each secret.
- Option B is incorrect because the CloudWatch Event rule needs a Lambda function as its target to
check if rotation is enabled. The description of the option is incomplete.
- Option C is incorrect because Amazon GuardDuty, as a continuous security monitoring service, does
not check the secret rotation for Secrets Manager.
- Option D is CORRECT because the AWS Config rule “secretsmanager-rotation-enabled-check” checks
whether AWS Secrets Manager secret has rotation enabled. Users need to add the rule in AWS Config
and set up a notification.
Question 30
The customer data of an application is stored in an S3 bucket. Your team would like to use Amazon
Athena to analyze the data using standard SQL. However, the data in the S3 bucket is encrypted via
SSE-KMS. How would you create the table in Athena for the encrypted data in S3?
A.
You need to provide the private KMS key to Athena.
B.
Athena decrypts the data automatically, and you do not need to provide key information.
C.
You need to convert SSE-KMS to SSE-S3 before creating the table in Athena.
D.
You need to disable the server-side encryption in S3 before creating the Athena table.
Correct Answer – B
- Option A is incorrect because, for SS3-KMS, Athena can determine the proper materials to decrypt
the dataset when creating the table. You do not need to provide the key information to
Athena.
- Option B is CORRECT because Athena can create the table for the S3 data encrypted by
SSE-KMS.
Options C and D are incorrect because these steps are not required. Athena can create tables for
the dataset encrypted by SSE-KMS.
Question 31
Your organization stores customer data in an Amazon DynamoDB table. You need to use AWS Glue to
create the ETL (extract, transform, and load) jobs to build the data warehouse. In AWS Glue, you
need a component to determine the schema from DynamoDB, and populate the AWS Glue Data Catalog with
metadata. Which of the following components should be used to implement it?
A.
Table in AWS Glue.
B.
Table in Amazon Athena.
C.
Crawler in AWS Glue.
D.
Classifier in AWS Glue
Correct Answer – C
You can use a crawler to populate the AWS Glue Data Catalog with tables. This is the primary method
used by most AWS Glue users. A crawler can crawl multiple data stores in a single run. Upon
completion, the crawler creates or updates one or more tables in your Data Catalog. The AWS Glue
Data Catalog can then be used to guide ETL operations.
- Option A is incorrect because the table in AWS Glue is used to define the data schema. It is not
the correct component to perform the ETL jobs.
- Option B is incorrect because the table in Athena is not the correct component to populate the AWS
Glue Data Catalog.
- Option C is CORRECT because, in AWS Glue, you can use a Crawler that connects to the DynamoBD
table and populates the Data Catalog.
- Option D is incorrect because Classifier is a component in Crawler that generates a schema. You
should use Crawler to perform the ETL jobs instead of Classifier. The classifier is not a separate
component.
Question 32
You work in a start-up company as an AWS solutions architect. You create a new AWS Organization that
includes a large amount of AWS accounts. You want to use a tool to trigger a notification whenever
the administrator performs an action in the Organization. Which of the following AWS services would
you use?
A.
Amazon EventBridge
B.
AWS Config Resources.
C.
AWS CloudTrail.
D.
AWS CloudWatch Logs.
Correct Answer – A
- Option A is CORRECT because Amazon EventBridge can raise events for actions in the AWS
Organization. You can register an SNS topic to trigger a notification in a CloudWatch Event
rule.
- Option B is incorrect because AWS Config Resources do not log events for AWS Organizations.
- Option C is incorrect because AWS CloudTrail is used to create to trail to monitor the AWS API
calls.
- Option D is incorrect because CloudWatch Logs cannot provide a real-time notification like
CloudWatch Events when an administrator-specified action in the Organization occurs.
Question 33
IoT sensors monitor the number of bags that are handled at an airport. The data is sent back to a
Kinesis stream with default settings. Every alternate day, the data from the stream is sent to S3
for processing. But it is noticed that S3 is not receiving all of the data being sent to the Kinesis
stream. What could be the reason for this?
A.
The sensors probably stopped working on somedays, hence data is not sent to the stream.
B.
S3 can only store data for a day.
C.
The default retention period of the data stream is set to 24 hours only, and hence the failure.
D.
Kinesis streams are not meant to handle IoT related data.
Correct Answer – C
Amazon Kinesis Data Streams supports changes to the data record retention period of your data
stream. A Kinesis data stream is an ordered sequence of data records meant to be written to and read
from in real-time. Data records are therefore stored in shards in your stream temporarily. The time
period from when a record is added to when it is no longer accessible is called the retention
period. A Kinesis data stream stores record from 24 hours by default, up to 8760 hours (365
days).
- Option A is incorrect, even though a possibility cannot be considered the right option.
- Option B is incorrect since S3 can store data indefinitely unless you have a lifecycle policy
defined.
- Option D is incorrect because the Kinesis service is perfect for this sort of data
ingestion.
Question 34
Your company uses an S3 bucket to store data for an application. Sometimes the team also downloads
the S3 files for further analysis. As the data is very important, you need to protect against
accidental deletions initiated by someone or an application and restore the files when needed. Which
of the following options is appropriate?
A.
Enable the versioning feature in the S3 bucket.
B.
Modify the S3 bucket to be read-only.
C.
Use an S3 Lifecycle policy to transfer objects to a lower cost storage.
D.
Enable the Server-Side Encryption with AWS KMS-Managed Keys (SSE-KMS)
Correct Answer – A
- Option A is CORRECT: The versioning feature in Amazon S3 helps retain prior versions of objects
stored in S3. Even if the current version is deleted accidentally, the data can still be recovered
from the previous version. Check the reference here
https://d1.awsstatic.com/whitepapers/aws-building-fault-tolerant-applications.pdf
- Option B is incorrect: The application may still need to write data in the S3 bucket. So the
option is not appropriate.
- Option C is incorrect: This method helps to save costs but not protect the data.
- Option D is incorrect: Because the Server-Side Encryption cannot protect against accidental
deletions.
Question 35
You are working as an AWS Administrator for a software firm with a popular Web application hosted on
EC2 instance in various regions. You are using AWS CloudHSM for offloading SSL/TLS processing from
Web servers. Since this is a critical application for the firm, you need to ensure that proper
backups are performed for data in AWS CloudHSM daily. What does the AWS CloudHSM use to perform a
secure & durable backup?
A.
Ephemeral backup key (EBK) is used to encrypt data & Persistent backup key (PBK) is used to encrypt
EBK before saving data to the Amazon S3 bucket in the same region as that of AWS CloudHSM cluster.
B.
Data Key is used to encrypt data & Customer Managed Key (CMK) is used to encrypt Data Key before
saving data to the Amazon S3 bucket in the same region as that of AWS CloudHSM cluster.
C.
Ephemeral Backup Key (EBK) is used to encrypt data & Persistent backup Key (PBK) is used to encrypt
EBK before saving data to the Amazon S3 bucket in a different region than the AWS CloudHSM cluster.
D.
Data Key is used to encrypt data & Customer Managed Key (CMK) is used to encrypt Data Key before
saving data to Amazon S3 bucket in a different region than the AWS CloudHSM cluster.
Correct Answer – A
To back up the AWS CloudHSM data to Amazon S3 buckets in the same region, AWS CloudHSM generates a
unique Ephemeral Backup Key (EBK) to encrypt all data using AES 256-bit encryption key. This
Ephemeral Backup Key (EBK) is further encrypted using Persistent Backup Key (PBK), which is also an
AES 256-bit encryption key.
- Option B is incorrect as AWS CloudHSM does not use data Key & Customer Managed Key to encrypt
data, instead of that EBK & PBK are used.
- Option C is incorrect. While taking the backup of data from different AWS CloudHSM clusters to the
Amazon S3 bucket, the Amazon S3 bucket should be in the same region as that of the AWS CloudHSM
cluster.
- Option D is incorrect as AWS CloudHSM does not use data Key & Customer Managed Key to encrypt
data. Instead of that, EBK & PBK are used to encrypt and save data to the Amazon S3 bucket in the
same region.
Question 36
A company is planning on moving its applications to the AWS Cloud. They have some large SQL data
sets that need to be hosted in a data store on the cloud. The data store needs to have features that
support client connections with many types of applications, including business intelligence (BI),
reporting, data, and analytics tools. Which of the following service should be considered for this
requirement?
A.
Amazon DynamoDB
B.
Amazon Redshift
C.
Amazon Kinesis
D.
Amazon Simple Queue Service
Correct Answer: B
The AWS Documentation mentions the following.
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can
start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to
use your data to acquire new insights for your business and customers.
Although Kinesis has capabilities for analyzing & transforming streaming data, the question refers
to having a data store for storing data from different applications BI, Reporting …which is where a
Data Lake or Data Warehouse solutions come into the picture. Kinesis would be more appropriate in
situations where one needs to process streaming data.
Amazon Redshift supports client connections with many types of applications, including business
intelligence (BI), reporting, data, and analytics tools.
- Option A is incorrect since DynamoDB is used for NoSQL datastore.
- Option C is incorrect since Kinesis is used for analyzing & transforming streaming data.
- Option D is incorrect since SQS is a message queue service used by distributed applications to
exchange messages through a polling mode.
Question 37
You are developing an application that uses the Amazon Kinesis Producer Library (KPL) to put data
records to an encrypted Kinesis data stream. However, when your application runs, there is an
unauthorized KMS master key permission error. How would you resolve the problem?
A.
Configure the application’s IAM role as the key administrator of the KMS key.
B.
In the KMS key policy, assign the permission to the application to access the key.
C.
Re-encrypt the Kinesis data stream with AWS/kinesis.
D.
Configure the KPL not to encrypt the data records for the Kinesis data stream
Correct Answer – B
- Option A is incorrect because the IAM role should be configured as a key user instead of an
administrator.
- Option B is CORRECT because the application would need to have permission to use the KMS key when
putting records in the stream.
- Option C is incorrect because the encryption of the Kinesis data stream should not be changed.
This is a key permission issue, and the key policy should be modified to address the
problem.
- Option D is incorrect because KPL does not have such a configuration.
Question 38
Your company plans to host its development, test, and production applications on EC2 Instances in
AWS. The team is worried about how access control would be given to relevant IT Admins for each of
the above environments. As an architect, what would you suggest to manage the relevant accesses?
A.
Add tags to the instances marking each environment and then segregate access using IAM Policies.
B.
Add Userdata to the underlying instances to mark each environment.
C.
Add Metadata to the underlying instances to mark each environment.
D.
Add each environment to a separate Auto Scaling Group.
Correct Answer - A
AWS Documentation mentions the following to support this requirement.
Tags enable you to categorize your AWS resources differently, for example, by purpose, owner, or
environment. This is useful when you have many resources of the same type — you can quickly identify
a specific resource based on the tags you've assigned to it.
Each tag consists of a key and an optional value, both of which you define. For example, you could
define a set of tags for your account's Amazon EC2 instances that help you track each instance's
owner and stack level.
We recommend you to devise a set of tag keys that will meet your needs for each resource type. Using
a consistent set of tag keys makes it easier for you to manage your resources. You can search and
filter the resources based on the tags you add.
Question 39
You have a web application that processes customer orders. The frontend application forwards the
order messages to an SQS queue. The backend contains an Elastic Load Balancer and an Auto Scaling
group. You want the ASG to auto-scale depending on the queue size. Which of the following CloudWatch
metrics would you choose to discover the SQS queue length?
A.
ApproximateNumberOfMessagesVisible
B.
NumberOfMessagesReceived
C.
NumberOfMessagesDeleted
D.
ApproximateNumberOfMessagesNotVisible
Correct Answer – A
The backend nodes can scale based on the queue length. Check the reference in
https://aws.amazon.com/blogs/compute/building-loosely-coupled-scalable-c-applications-with-amazon-sqs-and-amazon-sns/
- Option A is CORRECT: ApproximateNumberOfMessagesVisible describes the number of messages available
for retrieval. It can be used to decide the queue length.
- Option B is incorrect: Because NumberOfMessagesReceived is the number of messages returned by
calls to the ReceiveMessage action. It does not measure the queue length.
- Option C is incorrect: Because NumberOfMessagesDeleted is the number of messages deleted from the
queue. It is not suitable to be used in this scenario.
- Option D is incorrect: Because ApproximateNumberOfMessagesNotVisible measures the number of
messages in flight. It should not be used here.
Question 40
You are performing a Load Testing exercise on your application that is hosted on AWS. While testing
your Amazon RDS MySQL DB Instance, you notice that your application becomes non-responsive when you
reach 100% CPU utilization due to large read-heavy workloads. Which methods would help scale your
data tier to meet the application’s needs? (Select TWO)
A.
Add Amazon RDS Read Replicas, and have your application direct read queries to them.
B.
Add your Amazon RDS DB instance to storage Auto Scaling, and set your desired maximum storage limit.
C.
Use an Amazon SQS queue to throttle data going to the Amazon RDS Instance.
D.
Use ElastiCache to cache common queries of your Amazon RDS DB.
E.
Enable Multi-AZ for your Amazon RDS Instance.
Correct Answers: A and D
Amazon RDS Read Replicas provide enhanced performance and durability for database (DB) instances.
This replication feature makes it easy to elastically scale out beyond the capacity constraints of a
single DB Instance for read-heavy database workloads.
For more information on Read Replicas, please refer to the link below: https://aws.amazon.com/rds/details/read-replicas/
Amazon ElastiCache is a web service that makes it easy to deploy, operate, and scale an in-memory
data store or cache in the cloud. The service improves the performance of web applications by
allowing you to retrieve information from fast, managed, in-memory data stores instead of relying
entirely on slower disk-based databases.
For more information on ElastiCache, please refer to the link below. https://aws.amazon.com/elasticache/
- Option B is incorrect because it is not an ideal way to scale a database. Amazon RDS storage Auto
Scaling is to scale the storage capacity. If the storage capacity threshold is reached, then
capacity will be scaled through storage Auto Scaling.
RDS storage auto scaling does not look for the CPU utilization threshold. So it cannot be a
solution for bottlenecks to read heavy databases.
- Option C is incorrect. When there is a need for queue management of processing messages, then we
can modernize the architecture by using SQS with RDS. Currently, there is no requirement for a
queue service, hence this option is incorrect. https://aws.amazon.com/blogs/architecture/modernized-database-queuing-using-amazon-sqs-and-aws-services/
- Option E is incorrect because the Multi-AZ feature is used as a failover option, not suitable for
read-heavy workloads.
Question 41
You create several SQS queues to store different types of customer requests. Each SQS queue has a
backend node that pulls messages for processing. Now you need a service to collect messages from the
frontend and push them to the related queues using the publish/subscribe model. Which service would
you choose?
A.
Amazon MQ
B.
Amazon Simple Notification Service (SNS)
C.
Amazon Simple Queue Service (SQS)
D.
AWS Step Functions
Correct Answer – B
AWS SNS can push notifications to the related SQS endpoints. SNS uses a publish/subscribe model that
provides instant event notifications for applications.
- Option A is incorrect: Amazon MQ is a managed message broker service, which is not suitable for
this scenario.
- Option B is CORRECT: Because SNS uses Pub/Sub messaging to provide asynchronous event
notifications. Please check the link-
https://aws.amazon.com/pub-sub-messaging/
- Option C is incorrect: Because SQS does not use the publish/subscribe model.
- Option D is incorrect: AWS Step Functions coordinate application components using visual
workflows. The service should not be used in this scenario.
Question 42
You need a new S3 bucket to store objects using the write-once-read-many (WORM) model. After objects
are saved in the bucket, they cannot be deleted or overwritten for a fixed amount of time. Which
option would you select to achieve this requirement?
A.
Enable the Amazon S3 object lock when creating the S3 bucket.
B.
Enable versioning for the S3 bucket.
C.
Modify the S3 bucket policy to only allow the read operation.
D.
Enable the WORM model in the S3 Access Control List (ACL) configuration.
Correct Answer – A
Amazon S3 object lock should be enabled to store objects using the write once and read many (WORM)
models. The reference can be found in
https://docs.aws.amazon.com/AmazonS3/latest/dev/object-lock.html
- Option A is CORRECT: After the S3 object lock is enabled, you can prevent the S3 objects from
being deleted or overwritten for a fixed amount of time or indefinitely.
- Option B is incorrect: Because versioning does not prevent objects from being deleted or
modified.
- Option C is incorrect: Because the S3 bucket should still allow the write operation. Otherwise,
new objects cannot be saved in the bucket.
- Option D is incorrect: Because there is no such configuration in Access Control List (ACL).
Question 43
You are building up a Lambda function that runs periodically and processes the data stored in a
DynamoDB table. As the data in the DynamoDB table grows fast, you need to estimate the cost of the
Lambda function. Which of the following factors directly determine the monthly cost of Lambda? (
Select TWO.)
A.
The programming language used by the Lambda function.
B.
The Lambda function handler.
C.
The memory allocated to the Lambda function.
D.
The timeout value of the Lambda function.
E.
The total number of requests for the Lambda function.
Correct Answer – C, E
- Option A is incorrect: Because users are charged based on the number of requests and the time it
takes for the code to execute. The programming language does not directly determine the
cost.
- Option B is incorrect: Because the Lambda function handler does not impact the monthly cost at
all.
- Option C is CORRECT: Because the duration price depends on the amount of memory allocated to the
function.
- Option D is incorrect: Because the timeout value is not a direct factor in calculating the price.
Please check the below reference for details.
- Option E is CORRECT: Because the Lambda function charges you based on the number of requests, such
as $0.20 per 1M requests.
Question 44
You have a lifecycle rule for an S3 bucket that archives objects to the S3 Glacier storage class 60
days after creation. The archived objects are no longer needed one year after being created. How
would you configure the S3 bucket to save more cost?
A.
Configure a rule in S3 Glacier to place delete markers for objects that are one year old.
B.
Configure the S3 lifecycle rule to expire the objects after 365 days from object creation.
C.
Modify the S3 lifecycle rule to clean up expired object delete markers for one year old objects.
D.
Modify the S3 lifecycle rule to use S3 Glacier Deep Archive which automatically deletes objects one
year after creation.
Correct Answer – B
The question clearly says that archived objects are no longer required one year after being created.
So in total objects expiry should be kept to 365 days.
- Option A is incorrect because users cannot configure a rule to place delete markers in S3
Glacier.
- Option B is CORRECT because users can configure the object expiration in the S3 life cycle, Amazon
S3 will remove the expired objects.
- Option C is incorrect because cleaning up expired object delete markers does not expire the
objects. This action does not save costs.
- Option D is incorrect because S3 Glacier Deep Archive does not automatically delete
objects.
Question 45
You are working for an electrical appliance company that has a web-application hosted in AWS. This
is a two-tier web application with web-servers hosted in VPC’s & on-premise data-center. You are
using a Network Load balancer in the front end to distribute traffic between these servers. You are
using instance Id for configuring targets for Network Load Balancer. Some clients are complaining
about the delay in accessing this website.
To troubleshoot this issue, you are looking for a list of Client IP address having longer TLS
handshake time. You have enabled access logging on Network Load balancing with logs saved in Amazon
S3 buckets. Which tool could be used to quickly analyze many log files without any visualization in
a cost-effective way?
A.
Use Amazon Athena to query logs saved in Amazon S3 buckets.
B.
Use Amazon S3 console to process logs.
C.
Export Network Load Balancer access logs to third-party application.
D.
Use Amazon Athena along with Amazon QuickSight to query logs saved in Amazon S3 buckets.
Correct Answer – A
Amazon Athena is a suitable tool for querying Network Load Balancers logs. In the above case, since
a large amount of logs are saved in S3 buckets from the Network load balancer, Amazon Athena can be
used to query logs and generate required details of client IP address and TLS handshake time.
- Option B is incorrect as processing many logs directly from the S3 console will be a
time-consuming process.
- Option C is incorrect as using a third-party tool will not be a cost-effective solution.
- Option D is incorrect as in the above case, we require only details of Client IP details along
with TLS handshake time for troubleshooting purposes. Amazon QuickSight will be useful in case you
need data visualization.
Question 46
You are requested to guide a large Pharma company. They are looking for a solution to save all their
R&D test analysis data securely. Daily large numbers of reports are generated; this data would be
accessed from multiple R&D centers spread across the globe. The company requires this data to be
instantaneously available to all users. Which of the following is the most suitable way for AWS
storage to provide low latency access to users across the globe with the least cost?
A.
Use Amazon EC2 instance with instance store to store data.
B.
Use Amazon EFS volumes to store data.
C.
Use Amazon EBS volumes connected to the EC2 instance to store data
D.
Use Amazon S3 Standard storage class from Amazon S3 to store data.
Correct Answer – D
S3 Standard offers high durability, availability, and performance object storage for frequently
accessed data. Because it delivers low latency and high throughput, S3 Standard is appropriate for a
wide variety of use cases, including cloud applications, dynamic websites, content distribution,
mobile and gaming applications, and big data analytics.
- Option A is incorrect as the Instance store will provide low latency access from EC2 instances,
but it’s a temporary storage option.
- Option B is incorrect. Since this data would be accessed globally, Amazon EFS will not be ideal
for this requirement.
- Option C is incorrect as Amazon EBS volumes would be useful storage for single Amazon EC2
instances.
Question 47
A company hosts a popular web application that connects to an Amazon RDS MySQL DB instance running
in a private VPC subnet created with default ACL settings. The IT Security department has identified
a DoS attack from a suspect IP. How would you protect the subnets from this attack?
A.
Change the Inbound Security Groups to deny access from the suspecting IP.
B.
Change the Outbound Security Groups to deny access from the suspecting IP.
C.
Change the Inbound NACL to deny access from the suspecting IP.
D.
Change the Outbound NACL to deny access from the suspecting IP.
Correct Answer: C
Options A and B are incorrect because the Security Groups block traffic by default. You can use
NACLs as an additional security layer for the subnet to deny traffic.
- Option D is incorrect since just changing the Inbound Rules is sufficient.
The following are the characteristics of security groups:
You can specify allow rules, but not deny rules.
You can specify separate rules for inbound and outbound traffic.
Security group rules enable you to filter traffic based on protocols and port numbers.
Security groups are stateful — if you send a request from your instance, the response traffic for
that request is allowed to flow in regardless of inbound security group rules. Responses to allowed
inbound traffic are allowed to flow out, regardless of outbound rules.
A Network Access Control List (ACL) is an optional layer of security for your VPC that acts as a
firewall for controlling traffic in and out of one or more subnets. You might set up network ACLs
with rules similar to your security groups to add an additional layer of security to your
VPC.
Question 48
Your company has a set of 100 servers hosted on the AWS Cloud. There is a need to stream the Logs
from the Instances for analysis purposes. From a security compliance perspective, additional logic
will be executed to analyze the data for any sort of abnormal behaviour. Which of the following
would be used to stream the log data?
A.
Amazon CloudFront
B.
Amazon SQS
C.
Amazon Kinesis Data Streams (KDS)
D.
Amazon SES (Simple Email Service)
Correct Answer: C
The AWS Documentation mentions the following
Amazon Kinesis Data Streams enables you to build custom applications that process or analyze
streaming data for specialized needs. You can continuously add various types of data such as
clickstreams, application logs, and social media to an Amazon Kinesis data stream from hundreds of
thousands of sources. Within seconds, the data will be available for your Amazon Kinesis
Applications to read and process from the stream.
Use cases of Kinesis Data Streams:
Log and event data collection
Real-time analytics
Mobile data capture
Gaming data feed
- Option A is incorrect since CloudFront is a content distribution service.
- Option B is incorrect since SQS is used as a messaging service.
- Option D is incorrect since SES is an email service.
Question 49
A startup company wants to launch an online learning portal on AWS using CloudFront and S3. They
have different subscription models. One model where all the members will have access to basic
content but another model where the company provides premium content that includes access to
multiple private contents without changing their current links.
How should a Solution Architect design this solution to meet the requirements?
A.
Design the learning portal using CloudFront web distribution to deliver the premium private content
using Signed Cookies.
B.
Design the learning portal using CloudFront web distribution to deliver the premium private content
using Signed URLs.
C.
Design the learning portal using CloudFront web distribution to deliver the premium private content
using S3 pre-signed URLs.
D.
Design the learning portal using CloudFront web distribution to deliver the premium private content
using CloudFront geographic restrictions feature.
Answer: A
- Option A is CORRECT. Use signed cookies in the following cases to provide access to multiple
restricted files. For example, all the files for a video in HLS format or all of the files in the
subscribers' area of the website. You don't want to change your current URLs.
- Option B is incorrect.CloudFront signed URLs and signed cookies provide the same basic
functionality, and they allow users to control who can access the content.
Use signed URLs in the following cases.
You want to restrict access to individual files, for example, an installation download for your
application-
Your users are using a client (for example, a custom HTTP client) that doesn't support
cookies.
- Option C is incorrect because S3 pre-signed URLs won’t provide access without changing current
links.
- Option D is incorrect because the CloudFront geographic restrictions feature is used to prevent
users in specific countries from accessing your content, but there is no such requirement in the
question.
Question 50
A small company started using EBS backed EC2 instances due to the cost improvements over running
their own servers. The company’s policy is to stop the development servers over the weekend and
restart them each week. The first time the servers were brought back. None of the developers were
able to SSH into them. What did the server most likely overlook?
A.
The associated Elastic IP address has changed and the SSH configurations were not updated.
B.
The security group for a stopped instance needs to be reassigned after start.
C.
The public IPv4 address has changed on server restart and the SSH configurations were not updated.
D.
EBS backed EC2 instances cannot be stopped and were automatically terminated
Correct Answer: C
Correct:
C. The instance retains its private IPv4 addresses and any IPv6 addresses when stopped and
restarted. AWS releases the public IPv4 address and assigns a new one when it's restarted.
Incorrect:
A. An EC2 instance retains its associated Elastic IP addresses.
B. Security groups do not need to be reassigned to instances that are restarted.
D. EBS backed instances are the only instance type that can be started and stopped.
Question 51
An Organization has an application using Amazon S3 Glacier to store large CSV objects. While
retrieving these large objects end users are observing some performance issue. In most cases, users
only need a small part of the data instead of the entire objects.
A solutions Architect has been asked to re-design this solution to improve the performance. Which
solution is the most cost-effective?
A.
Use AWS Athena to retrieve only the data that users need.
B.
Use S3 Select to retrieve only the data that users need.
C.
Use Glacier Select to retrieve only the data that users need.
D.
Use custom SQL statements and S3 APIs to retrieve only the data that users need.
Correct Answer : C
- Option A is incorrect because Athena supports standard SQL to retrieve data, but it's more used
for analytical data.
- Option B is incorrect because the objects are stored in Glacier. The correct method should be
Glacier Select.
- Option C is CORRECT because the application needs to retrieve data from Glacier. With Glacier
Select, you can perform filtering directly against a Glacier object using standard SQL
statements.
- Option D is incorrect because writing custom SQL statements with S3 APIS wouldn't improve
performance.
Question 52
An IT firm is using AWS cloud infrastructure for its three-tier web application. They are using
memory-optimized EC2 instances for application hosting & SQL-based database servers deployed in
Multi-AZ with auto-failover. Recently, they are observing heavy loads on database servers. This is
impacting user data lookup from application servers resulting in slow access. As AWS Consultants,
they are looking for guidance to resolve this issue. Which of the following will provide a faster
scalable option to deliver data to users without impacting backend servers?
A.
Use Amazon ElastiCache to cache data.
B.
Configure the Multi-AZ replicas to serve the read traffic.
C.
Use Amazon CloudFront to save recently accessed data in cache.
D.
Use on-host caching on memory optimised EC2 instance.
Correct Answer – A
Amazon ElastiCache provides a scalable faster approach to cache data which can be used with both
SQL/NoSQL databases. These can be used to save application data, significantly improving latency &
throughout the application, and offloading load on back-end database servers.
- Option B is incorrect as a Multi-AZ replica is used for data redundancy. It is not used to share
the read traffic.
- Option C is incorrect as Amazon CloudFront is more suitable for website caching & not for
application caching.
- Option D is incorrect as this would provide a faster lookup of data, but it’s not scalable.
Question 53
Your company has setup EC2 Instances in a VPC for their application. They now have a concern that
not all of the EC2 instances are being utilized. Which of the below mentioned services can help you
find underutilized resources in AWS? Choose 2 answers from the options given below
A.
AWS Cloudwatch
B.
SNS
C.
AWS Trusted Advisor
D.
Cloudtrail
Correct Answers: A and C
The AWS Documentation mentions the following
"An online resource to help you reduce cost, increase performance,and improve security by optimizing
your AWS environment,Trust Advisor provides real time guidance to help you provison your resources
following AWS best practices"
Amazon CloudWatch is a monitoring and management service built for developers, system operators,
site reliability engineers (SRE), and IT managers. CloudWatch provides you with data and actionable
insights to monitor your applications, understand and respond to system-wide performance changes,
optimize resource utilization, and get a unified view of operational health.
- Option B is incorrect since this is a notification service
- Option D is incorrect since this is an API monitoring service
Question 54
A Solutions Architect has been asked to design a serverless media upload web application that will
have the functionality to upload thumbnail images, transcode videos, index files, validate contents,
and aggregate data in real-time. The architect needs to visualize the distributed components of his
architecture through a graphical console.
How can this be designed wisely?
A.
Host a static web application using Amazon S3, upload images to Amazon S3, trigger a Lambda function
when media files are uploaded, coordinate other media files processing Lambdas using several SQS
queues, and store the aggregated data in DynamoDB.
B.
Host a static web application using Amazon S3, upload images to Amazon S3, trigger a Lambda function
when media files are uploaded, coordinate other media files processing Lambdas using Simple Workflow
Service, and store the aggregated data in DynamoDB.
C.
Host a static web application using Amazon S3, upload images to Amazon S3, trigger a Lambda function
when media files are uploaded, process media files using various Lambdas, and store the aggregated
data in DynamoDB.
D.
Host a static web application using Amazon S3, upload images to Amazon S3, use S3 event notification
to trigger a Lambda function when media files are uploaded, coordinate other media files processing
Lambda using Step functions, and store the aggregated data in DynamoDB.
Correct Answer : D
As an above diagram, Steps functions are used to coordinate processing Lambda functions and store
the data on DynamoDB.
Differences between Steps function and SWF are as follows:
- Option A is incorrect: Using SQS queues to coordinate several Lambda functions is not
suitable.
- Option B is incorrect: SWF can manage workflows, but managing Lambda functions with step functions
are better. SWF is used to manage the infrastructure that runs workflow logic and tasks. SWF is
the least used service
- Option C is incorrect: Managing Lambda functions will be challenging without a managed workflow
service such as Step functions.
- Option D is CORRECT: This is the best answer as Step functions are used to coordinate the
processing of Lambda functions. It also provides a graphical way to visualize the processing
steps.
Question 55
Which of the following actions is required by the Lambda execution role to write the logs into AWS
CloudWatch? (Select THREE)
A.
logs:CreateLogGroup
B.
logs:GetLogEvents
C.
logs:CreateLogStream
D.
logs:DescribeLogStreams
E.
logs:PutLogEvents
Answer: A, C, and E
Question 56
An organization has a distributed application running. This application is implemented with
microservices architecture using AWS services including Lambda, API Gateway, SNS, and SQS.
What is the cost-effective best way to analyze, debug and notify if any issues arise in production?
A.
Use the CloudWatch dashboard to monitor the application, and create a cloud watch alarm to notify of
any errors.
B.
Use CloudWatch events to trigger a lambda and notify.
C.
Use X-Ray to analyze and debug the application and Enable insights notifications.
D.
Use 3rd party tools to debug and notify.
Correct Answer: C
- Option A is incorrect. Amazon cloud watch dashboards can help to monitor all the resources. You
can have a single view and multiple view across all the AWS regions to see how things are going
across the services. But it cannot give detailed debugging and monitoring of each service.
- Option B is incorrect because a cloud watch event is created if any event happens in service and
can not be used for detailed analysis and debugging.
- Option C is CORRECT as AWS X-ray collects data, analysis, and debugs of microservice applications.
Amazon X-Ray helps to analyze and debug modern applications. It will also collect the traces of
the request from each of the applications. It also records the traces. After recording, it can
create a view service map that can be seen to trace data latency and analyze the issues.
Insights feature helps to create notifications that alert your team in real-time. Notifications
help respond more quickly when troubleshooting is required, thus improving application
availability.
- Option D is incorrect. Any custom monitoring tool will not help for detailed debugging of any
microservices applications running on AWS.
Question 57
You have been hired as an AWS Architect in a global financial firm. They provide daily consolidated
reports to their clients for trades in stock markets. For a large amount of data processing, they
store daily trading transaction data in S3 buckets, which triggers the AWS Lambda function. This
function submits a new AWS Batch job in the Job queue. These queues use EC2 compute resources with
this customized AMI and Amazon ECS to complete the job.
You have been working on an application created using the above requirements. While performing a
trial for the application, even though it has enough memory/CPU resources, the job is stuck in a
Runnable state. Which of the following checks would help to resolve the issue?
A.
Ensure that AWS logs driver is configured on compute resources.
B.
AWS Batch does not support customized AMI, use ECS-optimized AMI.
C.
Check dependencies for the job which holds the job in Runnable state.
D.
Use only On-Demand EC2 instance in compute resources
Correct Answer – A
If your compute environment contains compute resources, but your jobs don't progress beyond
the RUNNABLE
status, then there is something preventing the jobs from actually being placed on a compute
resource. Here are some common causes for this issue:
The awslogs
log driver isn't configured on your compute resources
Insufficient resources
No internet access for compute resources
Amazon EC2 instance limit reached
- Option A is correct as this is one of the reasons which is preventing the jobs from actually being
placed on a compute resource.
- Option B is incorrect as AWS Batch supports both customized AMI and Amazon ECS-optimized AMI. This
is not a reason for Job being stuck in the Runnable state.
- Option C is incorrect as a Job moves into a Runnable state only after all dependencies are
processed. If there are any dependencies, Job stays in the Pending state, not the Runnable
state.
- Option D is incorrect as Compute resource can be an On-Demand Instance or a Spot Instance. In the
question, it is given that the application has enough memory/CPU resources, so this is not a
reason for Job being stuck in the Runnable state.
For more information on AWS Batch Job state & troubleshooting,
Question 58
You currently work for a company that is specialized in baggage management. GPS devices are
installed on all the baggage which delivers the unit’s coordinates every 10 seconds. You need to
collect and analyze these coordinates in real time from multiple sources. Which tool should you use
to collect the data in real time for processing?
A.
Amazon EMR
B.
Amazon SQS
C.
AWS Data Pipeline
D.
Amazon Kinesis
Correct Answer – D
The AWS Documentation mentions the following.
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can
get timely insights and react quickly to new information. Amazon Kinesis offers key capabilities to
cost-effectively process streaming data at any scale, along with the flexibility to choose the tools
that best suit the requirements of your application.
With Amazon Kinesis, you can ingest real-time data such as video, audio, application logs, website
clickstreams, and IoT telemetry data for machine learning, analytics, and other applications. Amazon
Kinesis enables you to process and analyze data as it arrives and responds instantly instead of
having to wait until all your data is collected before the processing can begin.
- Option A is incorrect Amazon EMR is used for big data processing using tools like Apache Hadoop,
Spark, and others, but it is not specifically designed for real-time data ingestion or stream
processing.
- Option B is incorrect Amazon SQS is a message queuing service, but it is designed for asynchronous
messaging between decoupled systems, not real-time data streaming and processing.
- Option C is incorrect AWS Data Pipeline is used for batch processing and the orchestration of data
workflows, but it is not suitable for real-time data ingestion and processing.
Question 59
As an AWS Solutions Architect, you are helping the team to set up an AWS Site-to-Site VPN so that
the AWS resources in a VPC can communicate with one remote site. You plan to use IPSec VPN tunnels
in the VPN connections as they provide secure connections with redundancy. When creating the
Site-to-Site VPN connection in AWS console, which of the following options can you configure for the
VPN tunnels?
A.
The number of VPN tunnels.
B.
The encryption algorithms used by the VPN tunnels.
C.
The memory used by the VPN tunnels.
D.
The TCP ports allowed by the VPN tunnels.
Correct Answer: B
- Option A is incorrect because AWS Site-to-Site VPN has two tunnels for redundancy and users cannot
modify this setting.
- Option B is CORRECT because the encryption algorithms of VPN IPSec tunnels can be configured by
users such as AES128 and AES256. Please check the following screenshot when configuring the VPN
tunnels:
AWS Site-to-Site VPN provides two tunnels for redundancy shown by the following snapshot:
When one tunnel becomes unavailable, network traffic is automatically routed to the other available
tunnel.
- Option C is incorrect because users cannot configure memories used by VPN tunnels.
- Option D is incorrect because when creating a VPN tunnel, users cannot allow or block any TCP
ports.
Question 60
You are working as an AWS Architect for a media firm. The firm has large text files that need to be
converted into audio files. They are using S3 buckets to store these text files.
AWS Batch is used to process these files along with Amazon Polly. You have a mix of EC2 On-Demand &
Spot instances for the compute environment. Critical Jobs must be completed quickly, while
non-critical Jobs can be scheduled during non-peak hours. While using AWS Batch, management wants a
cost-effective solution with no performance impact.
Which of the following Job Queue can be selected to meet this requirement?
A.
Create single Job Queue with EC2 On Demand instance having higher priority & Spot Instance having
lower priority.
B.
Create multiple Job Queues with one Queue having EC2 On Demand instance & having higher priority
while another queue having Spot Instance & lower priority.
C.
Create multiple Job Queues with one Queue having EC2 On Demand instance & having lower priority
while another queue having Spot Instance & higher priority.
D.
Create single Job Queue with EC2 On Demand instance having lower priority & Spot Instance having
higher priority.
Correct Answer – B
You can create multiple Job queues with different priorities & mapped Compute environments to each
Job queue. When Job queues are mapped to the same compute environment, queues with higher priority
are evaluated first.
Options A and D are incorrect because a Single queue will not provide the solution for a mix of EC2
On-Demand & Spot instances. The same single queue cannot have high priority and low priority at the
same time.
- Option C is incorrect as the Priority for a Job queue is selected in descending order. A higher
priority Job queue is preferred first.
Question 61
You have a requirement to get a snapshot of the current configuration of resources in your AWS
Account. Which service can be used for this purpose?
A.
AWS CodeDeploy
B.
AWS Trusted Advisor
C.
AWS Config
D.
AWS IAM
Correct Answer - C
AWS Documentation mentions the following.
With AWS Config, you can do the following.
Evaluate your AWS resource configurations for desired settings.
Get a snapshot of the current configurations of the supported resources that are associated with
your AWS account.
Retrieve configurations of one or more resources that exist in your account.
Retrieve historical configurations of one or more resources.
Receive a notification whenever a resource is created, modified or deleted.
View relationships between resources. For example, you might want to find all resources that use a
particular security group.
Question 62
You work for a company that has a set of EC2 Instances. There is an internal requirement to create
another instance in another availability zone. One of the EBS volumes from the current instance
needs to be moved from one of the older instances to the new instance. How can you achieve this?
A.
Detach the volume and attach to an EC2 instance in another AZ.
B.
Create a new volume in the other AZ and specify the current volume as the source.
C.
Create a snapshot of the volume and then create a volume from the snapshot in the other AZ
D.
Create a new volume in the AZ and do a disk copy of contents from one volume to another
Answer – C
For a volume to be available in another availability zone, you need to create a snapshot from the
volume. Then in the snapshot from creating a volume, you can then specify the new availability zone
accordingly.
The EBS Volumes attached to the EC2 Instance will always have to remain in the same availability
zone as the EC2 Instance. A possible reason for this could be because EBS Volumes are present
outside of the host machine, and instances have to be connected over the network. If the EBS Volumes
are present outside the Availability Zone, there can be potential latency issues and subsequent
performance degradation.
What one can do in such a scenario is to get the Snapshot of the EBS Volume. Snapshot sequentially
captures the state of your EBS Volume. You can create an EBS Volume from this snapshot in your
desired Availability Zone and attach it to your new Instance.
Later you can detach the volume from the older instance and delete then.
- Option A is invalid because the Instance and Volume have to be in the same AZ to be attached to
the instance. After all, we have to specify AZ while creating Volume.
- Option B is invalid because there is no way to specify a volume as a source.
- Option D is invalid because the Diskcopy would be a tedious process.
Question 63
Which of the following is a limitation of the Elastic Fabric Adapter (EFA)?
A.
EFA-only interfaces support only the EFA device capabilities.
B.
EFA traffic can’t cross Availability Zones or VPCs.
C.
EFA traffic refers to the traffic transmitted through the EFA device of either an EFA (EFA with ENA)
or EFA-only interface.
D.
EFA supports Nvidia Collective Communications Library (NCCL) for AI and ML applications.
Correct Answer: B
An Elastic Fabric Adapter (EFA) is a network device that can be attached to an Amazon EC2 instance
to accelerate Artificial Intelligence (AI), Machine Learning (ML), and High Performance Computing (
HPC) applications.
EFA (EFA with ENA) interfaces provide both ENA devices for IP networking and EFA devices for
low-latency, high-throughput communication.
EFA-only interfaces support only the EFA device capabilities, without the ENA device for traditional
IP networking.
- Option A is incorrect as it is one of the features of EFA.
- Option B is correct because it is one of the limitations of EFA (Elastic Fabric Adapter).
- Option C is incorrect because it is a true feature.
- Option D is incorrect because it is also a feature. EFA integrates with Libfabric 1.7.0 and later.
It supports Nvidia Collective Communications Library (NCCL) for AI and ML applications, Open MPI 4
and later, and Intel MPI 2019 Update 5 and later for HPC applications.
Question 64
A global media firm is using AWS CodePipeline as an automation service for releasing new features to
customers with periodic checks in place. All the codes are uploaded in the Amazon S3 bucket. Changes
in files stored in the S3 bucket should trigger AWS CodePipeline that will further initiate AWS
Elastic Beanstalk for deploying additional resources. What is the additional requirement that should
be configured to trigger CodePipeline in a faster way?
A.
Enable periodic checks and create a Webhook which triggers pipeline once S3 bucket is updated.
B.
Disable periodic checks, create an Amazon CloudWatch Events rule & AWS CloudTrail trail.
C.
Enable periodic checks, create an Amazon CloudWatch Events rule & AWS CloudTrail trail.
D.
Disable periodic checks and create a Webhook which triggers pipeline once S3 bucket is updated.
Correct Answer – B
To automatically trigger pipeline with changes in the source S3 bucket, Amazon CloudWatch Events
rule & AWS CloudTrail trail must be applied. When there is a change in the S3 bucket, events are
filtered using AWS CloudTrail & then Amazon CloudWatch events are used to trigger the start of the
pipeline. This default method is faster & periodic checks should be disabled to have events-based
triggering of CodePipeline.
You can use the following tools to monitor your CodePipeline pipelines and their resources:
Amazon CloudWatch Events — Use Amazon CloudWatch Events to detect and react to pipeline execution
state changes (for example, send an Amazon SNS notification or invoke a Lambda function).
AWS CloudTrail — Use CloudTrail to capture API calls made by or on behalf of CodePipeline in your
AWS account and deliver the log files to an Amazon S3 bucket. You can choose to have CloudWatch
publish Amazon SNS notifications when new log files are delivered so you can take quick
action.
Console and CLI — you can use the CodePipeline console and CLI to view details about the status of a
pipeline or a particular pipeline execution.
- Option A is incorrect as Webhooks are used to trigger pipeline when the source is GitHub
repository. Also, the periodic check will be a slower process to trigger CodePipeline.
- Option C is incorrect as Periodic checks are not a faster way to trigger CodePipeline.
- Option D is incorrect as Webhooks are used to trigger pipeline when the source is GitHub
repository.
Question 65
You are working as an AWS Architect for a retail company using AWS EC2 instance for a web
application. The company is using Provisioned IOPS SSD EBS volumes to store all product database.
This is a critical database & you need to ensure appropriate backups are accomplished every 12
hours. Also, you need to ensure that storage space is optimally used for storing all these snapshots
removing all older files. Which of the following can help to meet this requirement with the least
management overhead?
A.
Manually create snapshots & delete old snapshots for EBS volumes as this is a critical data.
B.
Use Amazon CloudWatch events to initiate AWS Lambda which will create snapshot of EBS volumes along
with deletion of old snapshots.
C.
Use Amazon Data Lifecycle Manager to schedule EBS snapshots and delete old snapshots as per
retention policy.
D.
Use Third party tool to create snapshot of EBS volumes along with deletion of old snapshots.
Correct Answer – C
Amazon Data Lifecycle Manager can be used for creation, retention & deletion of EBS snapshots. It
protects critical data by initiating backup of Amazon EBS volumes at selected intervals, along with
storing & deletion of old snapshots to save storage space & cost.
- Option A is incorrect as this will result in additional admin work & there can be a risk of losing
critical data due to manual errors.
- Option B is incorrect as for this we will need to do additional config changes in CloudWatch & AWS
Lambda. Also, AWS Lambda would need a script to create snapshots which can be an overhead
- Option D is incorrect as this will result in an additional cost to maintain a third-party
software.