400+ Câu hỏi luyện thi chứng chỉ AWS Certified Solutions Architect Associate (SAA-C03) - Phần 5
aws
aws certification
cloud computing
solutions architect
saa c03
aws exam
practice test
Question 1
You have implemented AWS Cognito services to require users to sign in and sign up to your app
through social identity providers like Facebook, Google, etc. Your marketing department wants users
to anonymously try out the app because the current log-in requirement is excessive, which may reduce
the demand for products and services offered through the app. What would you suggest to the
marketing department in this regard?
A.
It’s too much of a security risk to allow unauthenticated users access to the app.
B.
Cognito Identity supports guest users for the ability to enter the app and have limited access.
C.
A second version of the app will need to be offered for unauthenticated users.
D.
This is possible only if we remove the authentication from everywhere
Correct Answer - B
- Option B is correct. Amazon Cognito Identity Pools can support unauthenticated identities by
providing a unique identifier and AWS credentials for users who do not authenticate with an
identity
provider. Unauthenticated users can be associated with a role with limited access to resources
compared to a role for authenticated users.
- Option A is incorrect. Cognito will allow unauthenticated users without being a security
risk.
- Option C is incorrect. Cognito supports both authenticated and unauthenticated users.
Question 2
Your app uses AWS Cognito Identity for authentication and stores user profiles in a User Pool. To
expand the availability and ease of signing in to the app, your team is requesting advice on
allowing the use of OpenID Connect (OIDC) identity providers as additional means of authenticating
users and saving the user profile information. What is your recommendation on OIDC identity
providers?
A.
This is supported, along with social and SAML based identity providers.
B.
This is not supported, only social identity providers can be integrated into User Pools
C.
If you want OIDC identity providers, then you must include SAML and social-based support as well
D.
It’s too much effort to add non-Cognito authenticated user information to a User Pool
Correct Answer - A
- Option A is correct. OpenID Connect (OIDC) identity providers (IdPs) (like Salesforce or Ping
Identity) are supported in Cognito, along with social and SAML based identity providers. You can
add
an OIDC IdP to your user pool in the AWS Management Console, with the AWS CLI, or with the user
pool
API method CreateIdentityProvider.
- Option B is incorrect. Cognito supports more than just social identity providers, including OIDC,
SAML, and its own identity pools.
- Option C is incorrect. You can add any combination of federated types. You don’t have to add them
all.
- Option D is incorrect. While there is additional coding to develop this, the effort is most likely
not too great to add the feature.
Question 3
Your company currently has a web distribution hosted using the AWS CloudFront service. The IT
Security department has confirmed that the application using this web distribution now falls under
the scope of PCI (Payment Card Industry) compliance. What are the necessary steps to be followed
before auditing? (SELECT TWO)
A.
Enable CloudFront access logs.
B.
Enable Cache in CloudFront.
C.
Use AWS CloudTrail to capture requests sent to the CloudFront API.
D.
Enable VPC Flow Logs
Correct Answer: A and C
AWS Documentation mentions the following:
If you run PCI or HIPAA-compliant workloads based on the AWS Shared Responsibility Model, we
recommend that you log your CloudFront usage data for the last 365 days for future auditing
purposes.
To log usage data, you can perform the following:
Enable CloudFront access logs.
Capture requests that are sent to the CloudFront API using AWS CloudTrail.
- Option B is incorrect because enabling cache will only reduce latency. It will not help to fulfill
the requirement provided in the question.
- Option D is incorrect. VPC flow logs capture information about the IP traffic going to and from
network interfaces in a VPC, not for CloudFront.
Question 4
A company has applications running in multiple VPCs. These applications require interaction between
Amazon S3 buckets and DynamoDB. The company’s security policy requires that communication should be
secure and should not go over the public internet.
How does a solutions architect design this solution to meet these requirements?
A.
Create VPC Gateway Endpoints for S3 and DynamoDB and update route tables for all the availability
zones.
B.
Use the NAT Gateway and Internet Gateway for all the egress communication to these AWS services.
C.
Set up VPC peering and use VPC gateway endpoint for S3 and interface endpoint for DynamoDB to
communicate over AWS network.
D.
Set up VPC Peering between all VPCs and use public endpoints for both S3 and DynamoDB to facilitate
communication over the AWS network.
Answer: A
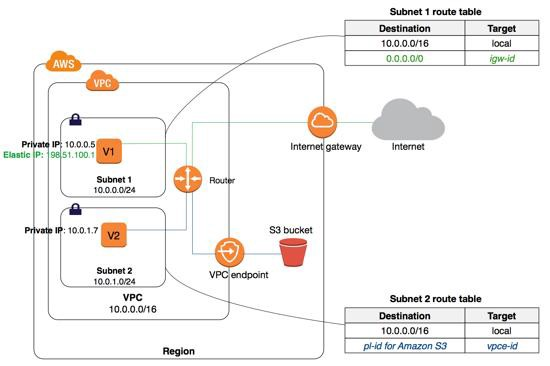
Types of VPC endpoints for Amazon S3
You can use two types of VPC endpoints to access Amazon S3: gateway endpoints and interface
endpoints. A gateway endpoint is a gateway that you specify in your route table to access Amazon S3
from your VPC over the AWS network. Interface endpoints extend the functionality of gateway
endpoints by using private IP addresses to route requests to Amazon S3 from within your VPC,
on-premises, or from a VPC in another AWS Region using VPC peering or AWS Transit Gateway.
There are two types of VPC endpoints:
Interface endpoint is an elastic network interface (ENI) with a private IP address from the IP
address range of the user's subnet that serves as an entry point for traffic destined to a supported
service. It enables you to privately access services by using private IP addresses.
Gateway endpoint is a gateway that you specify as a target for a route in your route table for
traffic destined to support AWS service. Currently supports S3 and DynamoDB services.
- Option A is CORRECT because the VPC gateway endpoint supports S3 and DynamoDB. Using the VPC
endpoint, communication will not go over the internet, and it will use AWS private network. A VPC
endpoint does not require an IGW, NAT device. Instances in the VPC do not require public IP
addresses to communicate with resources in the service. Traffic between VPC and the other service
stays in the Amazon network.
- Option B is incorrect as NAT gateway and IGW use public internet and do not provide secure
channels.
- Option C is incorrect as DynamoDB can be accessed using Gateway endpoint and not interface
endpoint.
VPC peering is between VPCs.
- Option D is incorrect This option is incorrect because it suggests using public endpoints for both
Amazon S3 and DynamoDB. While VPC peering allows communication between VPCs, using public
endpoints
would route traffic over the internet, which does not meet the company's security policy that
requires secure communication without going over the public internet. Both services should utilize
their respective private endpoints (Gateway for S3 and Interface for DynamoDB) to ensure the
communication remains within AWS's private network.
Question 5
A company consists of 50 plus AWS accounts. Each account has multiple VPCs with egress internet
connectivity using NAT gateway per Availability Zone (AZ). A solution architect has been asked to
redesign the network architecture that will reduce costs, and manage egress traffic, and the growing
needs of new accounts.
Which solution meets the requirements?
A.
Create an egress VPC for outbound internet traffic. Use VPC peering between AWS accounts’ VPCs and
connect to a set of redundant NAT gateways in the egress VPC.
B.
Create a Transit Gateway in one central AWS account that will work as a hub and spoke model to other
accounts VPCs using VPC attachments. Setup an egress VPC for egress traffic with redundant Nat
Gateways.
C.
Create an egress VPC for outbound internet traffic. Use AWS Private links between AWS accounts’ VPCs
and connect to a set of redundant NAT gateways in the egress VPC.
D.
Create a Transit Gateway in one central AWS account that will work as a hub and spoke model to other
accounts VPCs using VPN attachments. Set up a Central VPC for egress traffic with redundant Nat
Gateways
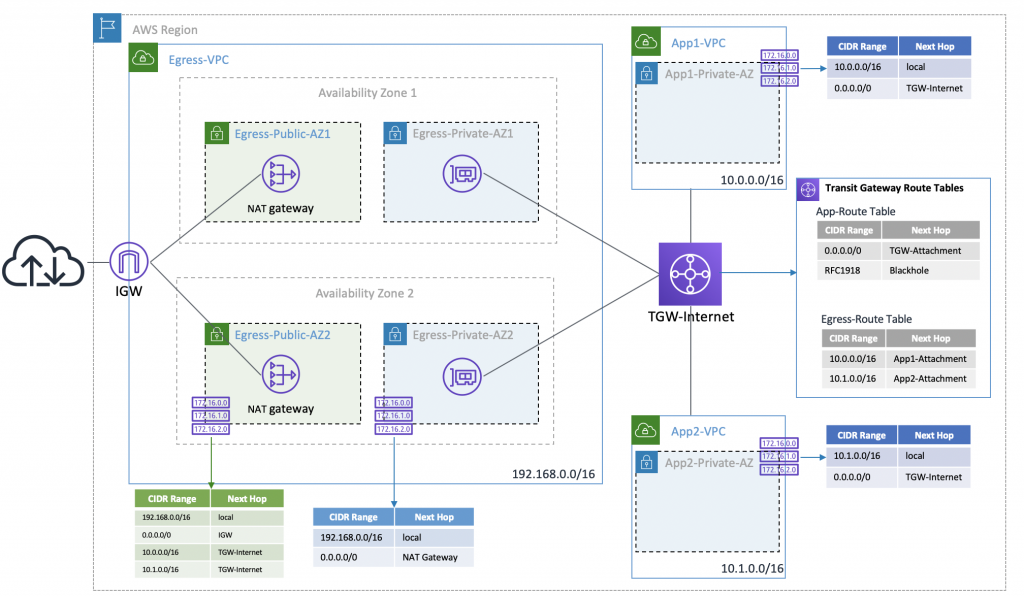
Answer: B
This architecture shows AWS Transit Gateway to centralize outbound internet traffic from multiple
VPCs using a hub-and-spoke design.
- Option A is incorrect because VPC peering doesn’t support transitive routing between Account A VPC
to Account B VPC to egress the internet.
- Option B is CORRECT because this design supports transitive routing and centralizing egress, which
helps to reduce cost.
- Option C is incorrect because AWS Private Link doesn’t support NAT devices.
- Option D is incorrect This option proposes using VPN attachments for the Transit Gateway. VPNs are
not necessary for connecting VPCs within the same AWS environment and may introduce additional
costs
and complexity without providing the required benefits for egress traffic management.
AWS PrivateLink enables you to securely connect your VPCs to supported AWS services: to your own
services on AWS, to services hosted by other AWS accounts, and to third-party services on AWS
Marketplace. Since traffic between your VPC and any one of these services does not leave the
Amazon
network, an Internet gateway, NAT device, public IP address, or VPN connection is no longer needed
to communicate with the service.
Question 6
Your organization must perform big data analysis to transform data and store the result in the AWS
S3 bucket. They have implemented the solution using AWS Lambda due to its zero-administrative
maintenance and cost-effective nature. However, in very few cases, the execution is getting abruptly
terminated after 15 minutes. They would like to get a notification in such scenarios. What would you
do?
A.
Setup timer in the code and send a notification when the timer reaches 900 seconds.
B.
Configure SES for failures under the Configuration option in the lambda function.
C.
Setup the ERROR_NOTIFY environment variable with an email address. Lambda function has an inbuilt
feature to send an email during max memory and time out terminations using this environment
variable.
D.
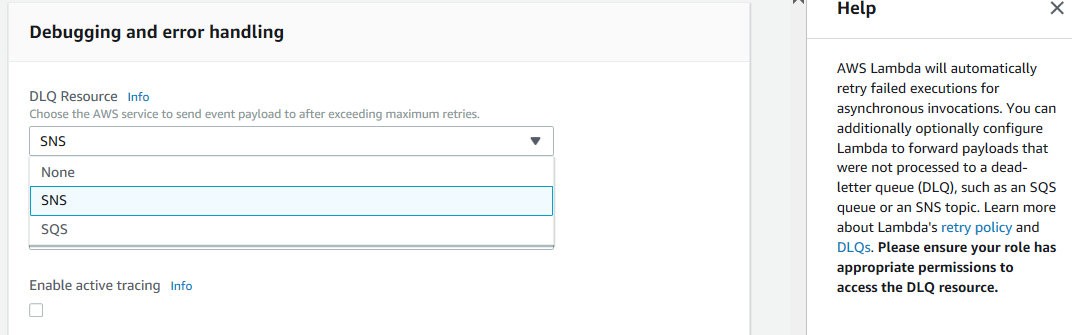
Configure Dead-letter Queue and send a notification to SNS topic
Answer: D
- Option A is not correct. Although you can set the timers in the code, it may not be an accurate
measure to determine if the lambda function is terminated after 900 seconds or just finished
executing on the 900th second.
- Option B is not correct. There is no option to configure AWS SES within the Lambda setup.
- Option C is not a valid statement.
- Option D is correct. You can forward non-processed payloads to Dead Letter Queue (DLQ) using AWS
SQS, AWS SNS.
Question 7
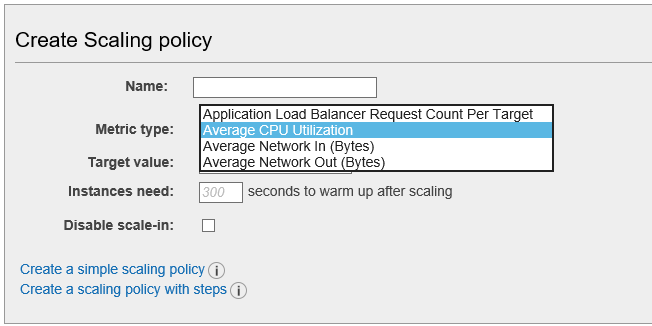
Which of the following is NOT a default metric type for Auto Scaling Group policy?
A.
Average CPU Utilization
B.
Memory Utilization
C.
Network In
D.
Network Out
Answer: B
Following are the default metric types available for Simple Policy and Step Policy
Question 8
Your company has a MySQL database deployed in an on-premise datacenter. You start using AWS Database
Migration Service (AWS DMS) to migrate the database to AWS RDS. You have a replication instance in
DMS to run the migration task. Which of the following options assign permissions that determine who
is allowed to manage AWS DMS resources?
A.
Transport Layer Security (TLS) connections between AWS DMS and local datacenter.
B.
AWS Key Management Service (AWS KMS) encryption used by the replication instance.
C.
AWS Identity and Access Management (IAM) policies.
D.
Network Control Lists (NCLs) in VPC subnets
Correct Answer – C
There are multiple approaches to secure the AWS DMS resources. Details can be found in https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Security.html
- Option A is incorrect: TLS protects the network layer. However, it does not assign
permissions.
- Option B is incorrect: KMS encrypts data. But it cannot manage the permissions.
- Option C is CORRECT: Because IAM policies can be assigned to IAM users who need to manage DMS
resources.
- Option D is incorrect: NCL acts as a firewall to protect the VPC subnets. But it does not
determine
who can access DMS resources.
Question 9
Your company stores a large amount of archive data in expensive on-premises storage systems. You
need to move the data to low-cost storage such as Amazon S3 Glacier. Which of the following tools is
the most suitable to simplify and automate the data transfer from on-premises to S3 Glacier?
A.
AWS DataSync
B.
Server Migration Service
C.
Database Migration Service
D.
Direct Connect
Correct Answer – A
AWS DataSync should be selected to simplify moving data between on-premises storage and AWS services
such as S3 Glacier. Check
https://docs.aws.amazon.com/datasync/latest/userguide/what-is-datasync.html
- Option A is CORRECT: With AWS DataSync, users can create a task to specify the data source and
destination and then configure the data transfer.
- Option B is incorrect: Because Server Migration Service is used to migrate on-premise servers such
as VMware.
- Option C is incorrect: Database Migration Service is used to migrate a database instead of local
storage.
- Option D is incorrect: Direct Connect sets up a dedicated network connection to AWS. However, it
does not automate the data transfer to AWS.
Question 10
You are working in a financial company, and you need to establish the network connections between
on-premises data centers and AWS VPCs. The connectivity needs to be secure with IPsec connections. A
predictable and high-performance network is also required over private lines. Which of the following
methods would you select?
A.
AWS Direct Connect + VPN
B.
AWS Managed VPN
C.
AWS Direct Connect
D.
Software VPN
Correct Answer – A
AWS has provided several connectivity options, according to
https://d1.awsstatic.com/whitepapers/aws-amazon-vpc-connectivity-options.pdf
VPN is needed as it creates an IPsec connection. AWS Direct Connect is also required because it
establishes a private connection with high bandwidth throughput.
- Option A is CORRECT: Because with AWS Direct Connect + VPN, you can create IPsec-encrypted private
connections.
- Option B is incorrect: Because only with VPN, the network performance cannot be guaranteed.
- Option C is incorrect: Because AWS Direct Connect does not use IPsec protocol.
- Option D is incorrect: Because Software VPN is still based on the internet instead of a dedicated
network.
Question 11
Your IT Supervisor is worried about users accidentally deleting objects from an S3 bucket. Which of
the following can help prevent accidental deletion of objects in an S3 bucket? (Select Three)
A.
Enable encryption for the S3 bucket.
B.
Enable MFA Delete on the S3 bucket.
C.
Enable Versioning on the S3 bucket.
D.
Restrict access to the bucket using IAM user policies.
Correct Answers – B, C, and D
When a user performs a DELETE operation on an object, subsequent simple (un-versioned) requests will
no longer retrieve the object. However, all versions of that object will continue to be preserved in
your Amazon S3 bucket and can be retrieved or restored.
Versioning’s MFA Delete capability, which uses multi-factor authentication, can be used to provide
an additional layer of security. By default, all requests to your Amazon S3 bucket require your AWS
account credentials. If you enable Versioning with MFA Delete on your Amazon S3 bucket, two forms of
authentication are required to permanently delete a version of an object: your AWS account
credentials and valid six-digit code and serial number from an authentication device in your
physical possession.
- Option D is correct. Writing IAM user policies that specify the users that can access specific
buckets and objects. IAM policies provide a programmatic way to manage Amazon S3 permissions for
multiple users.
- Option A is incorrect, Enable encryption for the S3 bucket is incorrect because encryption
primarily
protects data at rest by ensuring that the data is unreadable to unauthorized users. However, it
does not prevent accidental deletion of objects. Encryption focuses on data confidentiality rather
than access control or deletion prevention
To know more about Option D, Please refer to the below AWS Document.
https://aws.amazon.com/blogs/security/how-to-restrict-amazon-s3-bucket-access-to-a-specific-iam-role/ https://aws.amazon.com/premiumsupport/knowledge-center/secure-s3-resources/
Question 12
A company has been using AWS cloud services for six months and has just finished a security review.
Which of the following is considered a best practice in the security pillar of the well-architected
framework?
A.
Giving least privilege access to the IAM users.
B.
Monitoring using CloudWatch.
C.
Assigning Private IP address ranges to VPCs that do not overlap.
D.
Designing the system with elasticity to meet changes in demand
Correct Answer: A
- Option A is correct. This is a security best practice that ensures IAM users and roles have only
the
permissions necessary to perform their job functions. By minimizing access rights, organizations
reduce the risk of unauthorized access and potential breaches, aligning with the principle of
least
privilege.
- Option B is incorrect. Monitoring and alerting for key metrics and events are the best practices
of
the Performance Efficiency pillar.
- Option C is incorrect. Non-overlapping Private IP addresses are in the Reliability pillar.
- Option D is incorrect. Designing with elasticity is in the Performance Efficiency pillar (Design
for
Cloud Operations).
Question 13
A company has a Redshift Cluster defined in AWS. The IT Operations team has ensured that both
automated and manual snapshots are in place. Since the cluster will run for a couple of years,
Reserved Instances have been purchased. There has been recent concern about the cost being incurred
by the cluster. Which of the following steps should be carried out to minimize the costs being
incurred by the cluster?
A.
Delete the manual snapshots.
B.
Set the retention period of the automated snapshots to 35 days.
C.
Choose to use Spot Instances instead of Reserved Instances.
D.
Choose to use Instance store volumes to store the cluster data.
Correct Answer - A
AWS Documentation mentions the following.
Regardless of whether you enable automated snapshots, you can take a manual snapshot whenever you
want at any time. By default, manual snapshots are retained indefinitely, even after you delete your
cluster. You can specify the retention period when you create a manual snapshot or change the
retention period by modifying the snapshot.
To reduce cost, we can delete the manual snapshots that are taken, if any.
Backup storage is the storage associated with the snapshots taken for your data warehouse.
Increasing your backup retention period or taking additional snapshots increases the backup storage
consumed by your data warehouse.
For example, if your RA3 cluster has 10 TB of data and 30 TB of manual snapshots, you would be
billed for 10 TB of RMS and 30 TB of backup storage. With dense compute (DC) and dense storage (DS)
clusters, storage is included on the cluster and is not billed separately, but backups are stored
externally in Amazon S3. Backup storage beyond the provisioned storage size on DC and DS clusters is
billed as backup storage at standard S3 rates. Snapshots are billed until they expire or are
deleted, including when the cluster is paused or deleted.
Automated snapshots are automatically deleted within the period of 1(Least) to 35(Max) days (Based
on the retention period settings). So we have to take care of the Manual snapshots instead of
Automated snapshots. Amazon Redshift never deletes Manual snapshots automatically, as how it does
for Automatic Snapshots.
- Option B is incorrect because the Automated snapshots are automatically deleted within the period
of
1(Least) to 35(Max) days. This will NOT have any impact on the cost
- Option C is incorrect because SPOT instances are not a good fit for snapshots and the question
does
not mention one of these.
- Option D is incorrect because instance store volumes are volatile and therefore this is NOT a good
fit for the snapshot.
Question 14
A website is hosted on two EC2 instances that sit behind an Elastic Load Balancer. The website’s
response time has been slowed down drastically, and fewer orders are placed by the customers due to
the wait time. By troubleshooting, it showed that one of the EC2 instances had failed and only one
instance is running now. What is the best course of action to prevent this from happening in the
future?
A.
Change the instance size to the maximum available to compensate for the failure.
B.
Use CloudWatch to monitor the VPC Flow Logs for the VPC, the instances are deployed in.
C.
Configure the ELB to perform health checks on the EC2 instances and implement auto-scaling.
D.
Replicate the existing configuration in several regions for failover
Correct Answer: C
- Option C is correct. Using the elastic load balancer to perform health checks will determine
whether
or not to remove a non-performing or underperforming instance, and have the auto-scaling group
launch a new instance.
- Option A is incorrect. Increasing the instance size doesn’t prevent the failure of one or both
instances. Therefore the website can still become slow or unavailable.
- Option B is incorrect. Monitoring the VPC flow logs for the VPC will capture the VPC traffic, not
the traffic for the EC2 instance. You would need to create a flow log for a network
interface.
- Option D is incorrect. Replicating the same two instance deployment may not prevent instances of
failure and could still result in the website becoming slow or unavailable.
Question 15
A company currently hosts a lot of data on its On-premises location. They want to start storing
backups of these data with low latency access to data on AWS. How could this be achieved most
efficiently?
A.
Create EBS Volumes and store the data.
B.
Create EBS Snapshots and store the data.
C.
Make use of Storage Gateway Stored volumes.
D.
Make use of Amazon Glacier.
Correct Answer – C
AWS Storage Gateway connects an on-premises software appliance with cloud-based storage to provide
seamless integration with data security features between your on-premises IT environment and the AWS
storage infrastructure. You can use the service to store data in the AWS Cloud for scalable and
cost-effective storage to maintain data security.
It has two types of configuration, cached volumes and stored volumes:
We require to start storing backups of the on-premises data to AWS.
In cached volumes, you store your data in S3 and retain a copy of frequently accessed data subsets
locally. It means that we are not storing the backups on S3 but the actual primary data
itself.
But in the stored mode, your primary data is stored locally, and your entire dataset is available
for low-latency access on-premises while asynchronously getting backed up to AWS S3.
- Option A is Incorrect, While Amazon EBS (Elastic Block Store) volumes can be created and used to
store data, they are designed primarily for use with EC2 instances. They do not inherently provide
a
backup solution for on-premises data nor low-latency access to that data if the data needs to be
transferred from on-premises systems. It also does not address backup or hybrid cloud use cases
effectively.
- Option B is Incorrect, EBS Snapshots are a way to create backups of EBS volumes. However, they are
typically used to back up the data stored in EBS volumes rather than acting as a direct method to
back up on-premises data. Snapshots are also not designed for low-latency access from on-premises
data and are more suited for backup and recovery of EC2 instance data.
- Option D is Incorrect, Amazon Glacier is primarily designed for long-term archival storage and is
not suitable for low-latency access. Although it is cost-effective for storing large amounts of
data, the retrieval times can vary from minutes to hours, making it impractical for scenarios that
require quick access to data. Thus, it doesn't meet the requirement for low-latency access.
Question 16
For a new application, you need to build up the logic tier and data storage tier in AWS. The whole
architecture needs to be serverless so that designers can quickly deploy the application without the
need to manage servers. Which of the following AWS services would you choose?
A.
Logic tier: “Amazon Cognito + Lambda”. Data Storage tier: “Amazon RDS”
B.
Logic tier: “API Gateway + Lambda”. Data Storage tier: “Amazon DynamoDB”
C.
Logic tier: “API Gateway + Lambda”. Data Storage tier: “Amazon Redshift”
D.
Logic tier: “Elastic Beanstalk + EC2”. Data Storage tier: “Amazon Aurora”
Correct Answer – B
The key to the question is that the architecture should be serverless.
- Option A is incorrect because Amazon Cognito is not suitable for the logic tier, and Amazon RDS is
not a serverless service.
- Option B is CORRECT because both API Gateway/Lambda and Amazon DynamoDB are serverless, and hence
the process of deploying servers is simplified.
- Option C is incorrect because Amazon Redshift is a data warehouse service and is not
serverless.
- Option D is incorrect because Elastic Beanstalk utilizes EC2 instances as its computing resources
which is not a serverless service.
Question 17
A Solutions Architect is designing a solution to store and archive corporate documents. The
Architect has determined that Amazon Glacier is the right solution. Data has to be retrieved within
3-5 hrs as directed by the management.
Which feature in Amazon Glacier could be helpful to meet this requirement and ensure
cost-effectiveness?
A.
Vault Lock
B.
Expedited retrieval
C.
Bulk retrieval
D.
Standard retrieval
Correct Answer – D
- Option A is incorrect. This feature of Amazon Glacier allows you to lock your vault with various
compliance controls designed to support such long-term records retention. Due to this reason, this
is not the correct answer.
- Option B is incorrect. It allows you to quickly access your data when occasional urgent requests
are
required for a subset of archives. The data is available within 1 - 5 minutes. Since our
requirement
is 3 - 5 hours, we do not need to use this option.
- Option C is incorrect. They are the lowest-cost retrieval option, enabling you to retrieve large
amounts of data within 5 - 12 hours. Due to this reason, it is not the correct answer.
- Option D is correct. Standard retrievals are a low-cost way to access your data within just a few
hours.
For example, you can use Standard retrievals to restore backup data, retrieve archived media
content
for same-day editing or distribution, or pull and analyze logs to drive business decisions within
hours.
Question 18
Your application has two tiers in AWS: the frontend layer and the backend layer. The frontend
includes an Auto Scaling group deployed in a public subnet. The backend Auto Scaling group is
located in another private subnet. The backend instances should only allow the incoming traffic from
the frontend ASG through a custom port. For the backend security group, how would you configure the
source in its inbound rule?
A.
Configure the frontend security group ID as the source.
B.
Configure the public subnet IP range as the source.
C.
Configure the frontend Auto Scaling group ARN as the source.
D.
Configure the frontend Auto Scaling launch configuration as the source.
Correct Answer – A
Refer to
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-security-groups.html#security-group-rules
for how to configure security group rules.
- Option A is CORRECT: By configuring the frontend security group as the source, any frontend
instances that have the specified security group are allowed to access the backend.
- Option B is incorrect: Other instances in this subnet can also access the backend. This option is
not as good as option A.
- Option C is incorrect: Because Auto Scaling group ARN cannot be configured in the source of a
security group inbound rule.
- Option D is incorrect: Because the launch configuration cannot be configured in the source.
Question 19
A company has a business-critical three-tier, highly available web portal in AWS. The web tier runs
on different types of Amazon EC2 families. The application tier runs on one set of EC2 families, and
the database tier runs on Amazon RDS. The Manager has asked the Solutions Architect to reduce the
costs of this architecture without any impact on the company’s business. Which of the following
options is the most cost-effective while maintaining reliability and high availability?
A.
Use Compute Savings Plans for the web tier, EC2 Instance Savings Plans for the application tier, and
Reserved Instances for the database tier.
B.
Use Compute Savings Plans for the web tier, EC2 Instance Savings Plans for the application tier and
the database tier.
C.
Use EC2 Instance Savings Plans for the web tier, Compute Savings Plans for the application tier and
the database tier.
D.
Use EC2 Instance Savings Plans for the web tier, Compute Savings Plans for the application tier, and
OnDemand Instances for the database tier
Correct Answer: A
Compute Savings Plans offer the most flexibility, allowing cost savings across different EC2
instance families, sizes, and AWS services. This is ideal for the web tier, which may run on
different EC2 types.
EC2 Instance Savings Plans are more restrictive but provide better discounts for a specific instance
type. These are a good fit for the application tier, where the architecture is more stable and uses
a specific EC2 instance family.
Reserved Instances (RIs) are ideal for RDS (database tier), as databases often have long-term,
predictable usage. Reserved Instances offer substantial cost savings over On-Demand pricing and
ensure high availability and reliability.
- Option B is incorrect Using EC2 Instance Savings Plans for the database tier is less effective
than
Reserved Instances for RDS. Reserved Instances are specifically optimized for databases and offer
better savings.
- Option C is incorrect Compute Savings Plans for the application tier and database tier are not as
cost-effective as EC2 Instance Savings Plans and Reserved Instances for these tiers, given their
predictable workloads.
- Option D is incorrect On-Demand Instances for the database tier significantly increase costs
compared to Reserved Instances, which are more suitable for consistent workloads.
Question 20
A small company started using EBS backed EC2 instances for the cost improvements over their own
running servers. The company’s policy is to stop the development servers over the weekend and
restart them next week. The first time when the servers were brought back, none of the developers
were able to SSH into them. What did the server most likely overlook?
A.
The associated Elastic IP address has changed and the SSH configurations were not updated.
B.
The security group for a stopped instance needs to be reassigned after the start.
C.
The public IPv4 address has changed on the server start and the SSH configurations were not updated.
D.
EBS backed EC2 instances could not be stopped and were automatically terminated.
Correct Answer: C
- Option C is correct. The instance retains its private IPv4 addresses and any IPv6 addresses when
stopped and started. AWS releases public IPv4 address and assigns a new one when it is stopped &
started.
- Option A is incorrect. An EC2 instance retains its associated Elastic IP addresses.
- Option B is incorrect. Security groups do not need to be reassigned to instances that are
restarted.
- Option D is incorrect. EBS backed instances are the only instance type that can be started and
stopped.
Question 21
A company plans to deploy a business-critical application on Amazon EC2 instances. This application
should be scalable in a clustered environment. It supports high-performance computing (HPC) with
consistency latency and highest throughput.
How can this be achieved by meeting all the requirements above?
A.
Configure the application on EC2 instances with enhanced networking enabled using the Elastic
Network Adapter (ENA).
B.
Configure the application on EC2 instances with enhanced networking enabled using the Elastic Fabric
Adapter (EFA).
C.
Configure the application on EC2 instances with enhanced networking enabled using the Elastic
Network Interface (ENI).
D.
Configure the application on EC2 instances with enhanced networking enabled using the Elastic
Network (EN).
Answer: B
- Option A is incorrect. Although ENA supports low latency and high throughput, it doesn’t meet
high-performance requirements.
- Option B is CORRECT. EFA supports low latency and high throughput with high-performance computing
with the scalability, flexibility, and elasticity provided by the AWS Cloud.
- Option C is incorrect as ENI is used for creating management networks and deploying low budget
solutions. This will not meet HPC and low latency requirements.
- Option D is incorrect. However, ENA or EN supports low latency and high throughput. But it doesn’t
meet high-performance requirements.
Question 22
You have a set of IIS Servers running on EC2 Instances. You want to collect and process the log
files generated from these IIS Servers. Which service would be ideal for utilizing the Big Data
analytics in this scenario?
A.
Amazon S3 for storing the log files and Amazon EMR for processing the log files.
B.
Amazon S3 for storing the log files and EC2 Instances for processing the log files.
C.
Amazon EC2 for storing and processing the log files.
D.
Amazon DynamoDB to store the logs and EC2 for running custom log analysis scripts
Correct Answer – A
Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache
Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. Using these frameworks
and related open-source projects, such as Apache Hive and Apache Pig, you can process data for
analytics purposes and business intelligence workloads. Additionally, you can use Amazon EMR to
transform and move a large amount of data into and out of other AWS data stores and databases, such
as Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB.
Options B and C are incorrect as it would be an overhead for EC2 Instances to process log files when
you already have a ready-made service to help in this regard.
- Option D is incorrect because DynamoDB is not an ideal option to store log files.
Question 23
You need to ensure that the new objects being uploaded to an S3 bucket should be available in
another region also, due to the criticality of the data hosted in the S3 bucket. How could you
achieve this in the easiest way possible?
A.
Enable Cross-Region Replication for the bucket.
B.
Write a script to copy the objects to another bucket in the destination region.
C.
Create an S3 snapshot in the destination region.
D.
Enable versioning that will copy the objects to the destination region.
Correct Answer – A
AWS Documentation mentions the following.
Cross-Region Replication is a bucket-level configuration that enables automatic, asynchronous
copying of objects across buckets in different AWS Regions.
Question 24
A storage solution is required in AWS to store videos uploaded by the user. After accessing these
videos frequently for a period of a month, these videos can be deleted. How could this be
implemented in the most cost-effective manner?
A.
Use EBS Volumes to store the videos. Create a script to delete the videos after a month.
B.
Configure object expiration lifecycle policy rule on the S3 bucket and the policy will take care of
deleting the videos on the completion of 30 days.
C.
Store the videos in Amazon Glacier and then use Lifecycle Policies.
D.
Store the videos using Stored Volumes. Create a script to delete the videos after a month.
Correct Answer – B
AWS Documentation mentions the following on Lifecycle Policies.
Lifecycle configuration enables you to specify the lifecycle management of objects in a bucket. The
configuration is a set of one or more rules, where each rule defines an action for Amazon S3 to
apply to a group of objects. These actions can be classified as follows.
Transition actions – In which you define when objects transition occurs to another storage class.
For example, you may choose transition objects to the STANDARD_IA (IA, for infrequent access)
storage class 30 days after creation or archive objects to the GLACIER storage class one year after
creation.
Expiration actions – In which you specify when the objects expire. Then Amazon S3 deletes the
expired objects on your behalf.
Question 25
You are working as an AWS Architect for a global media firm. They have web servers deployed on EC2
instances across multiple regions. For audit purposes, you have created a CloudTrail trail that
delivers the CloudTrail event log files to the S3 bucket
This trail applies to all regions & delivers the CloudTrail event log files to the S3 buckets in the
EU-Central region. During last year’s audit, auditors have raised a query on the integrity of log
files that are delivered to the S3 buckets and raised a Non-Compliance flag against them. Which
feature could help you to gain compliance from Auditors for given issue?
A.
Use Amazon SSE-S3 encryption for the CloudTrail log file while storing it to S3 buckets.
B.
Use Amazon SSE-KMS encryption for CloudTrail log file while storing it to S3 buckets.
C.
Use an S3 bucket policy to grant access to only Security head for S3 buckets having CloudTrail log
files.
D.
Enable the CloudTrail log file integrity validation feature.
Correct Answer: D
To determine whether a log file was modified, deleted, or unchanged after CloudTrail delivered it,
you can use CloudTrail log file integrity validation. This feature is built using industry-standard
algorithms: SHA-256 for hashing and SHA-256 with RSA for digital signing. This makes it
computationally infeasible to modify, delete or forge CloudTrail log files without detection.
- Option A is incorrect as, by default, all CloudTrail log files are delivered to S3 buckets using
SSE-S3 encryption. This will not ensure the integrity of log files.
- Option B is incorrect as with Amazon SSE-KMS encryption for CloudTrail log files. There would be
an
additional layer of security for log files. But it won’t ensure the integrity of log files.
- Option C is incorrect as this will restrict access to the bucket. But it won’t ensure that no
modification has been done to log files post delivering in S3 buckets.
Question 26
You work in the media industry and have deployed a web application on a large EC2 instance where
users can upload photos to your website. This web application must be able to call the S3 API to
function properly. Where would you store your API credentials while maintaining the maximum level of
security?
A.
Save the API credentials to your PHP files.
B.
Don’t save your API credentials. Instead, create an IAM role and assign that role to an EC2
instance.
C.
Save your API credentials in a public Github repository.
D.
Pass API credentials to the instance using instance user data
Correct Answer – B
We designed IAM roles so that your applications can securely make API requests from your instances,
without requiring you to manage the security credentials that the applications use. Instead of
creating and distributing your AWS credentials, you can delegate permission to make API requests
using IAM roles as follows:
Create an IAM role.
Define which accounts or AWS services can assume the role.
Define which API actions and resources the application can use after assuming the role.
Specify the role when you launch your instance or attach the role to an existing instance.
Have the application retrieve a set of temporary credentials and use them.
Question 27
You are a Solutions Architect working for a financial services firm using a hybrid cloud model.
Applications running on Amazon EC2 instances within your VPC need to communicate with resources in
your on-premises data center. These EC2 instances are in one subnet, and a transit gateway is in
another subnet, with both subnets having different Network Access Control Lists (NACLs). You’ve
configured NACL rules to control traffic between the EC2 instances and the transit gateway.
What must be considered when setting up NACL rules for traffic from the EC2 instances to the transit
gateway?
A.
Outbound rules use the source IP address to evaluate traffic from the instances to the transit
gateway.
B.
Outbound rules use the destination IP address to evaluate traffic from the instances to the transit
gateway.
C.
Outbound rules are not evaluated for the transit gateway subnet
D.
Inbound rules use the destination IP address to evaluate traffic from the transit gateway to the
instances.
Correct Answer: B
The question asks for the NACL rule when the instances and transit gateway are in different subnets
and traffic flows from EC2 instance to transit gateway.
- Option A is incorrect. For traffic outbound from your EC2 instance subnet, the source IP address
is
not valid, the destination IP address is used to evaluate the rule.
- Option B is correct. This is the required rule NACLs should follow when the instances and transit
gateway are in different subnets and the traffic flows from instances to the transit
gateway.
Network ACL Outbound rules use the destination IP address to evaluate traffic from the instances
to
the transit gateway.
- Option C is incorrect because when the instances and transit gateway are in different subnets,
outbound rules are evaluated and provide the flow of traffic as required.
- Option D is incorrect. For traffic inbound from your transit gateway, the source IP address is
used
to evaluate the rule.
Question 28
You are working as an AWS Architect for a start-up company. They have a two-tier production website.
Database servers are spread across multiple Availability Zones.
You have configured Auto Scaling Group for these database servers with a minimum of 2 instances & a
maximum of 6 instances. During post-peak hours, you observe some data loss. Which feature needs to
be configured additionally to avoid future data loss (and copy data before instance termination)?
A.
Modify the cooldown period to complete custom actions before the Instance terminates.
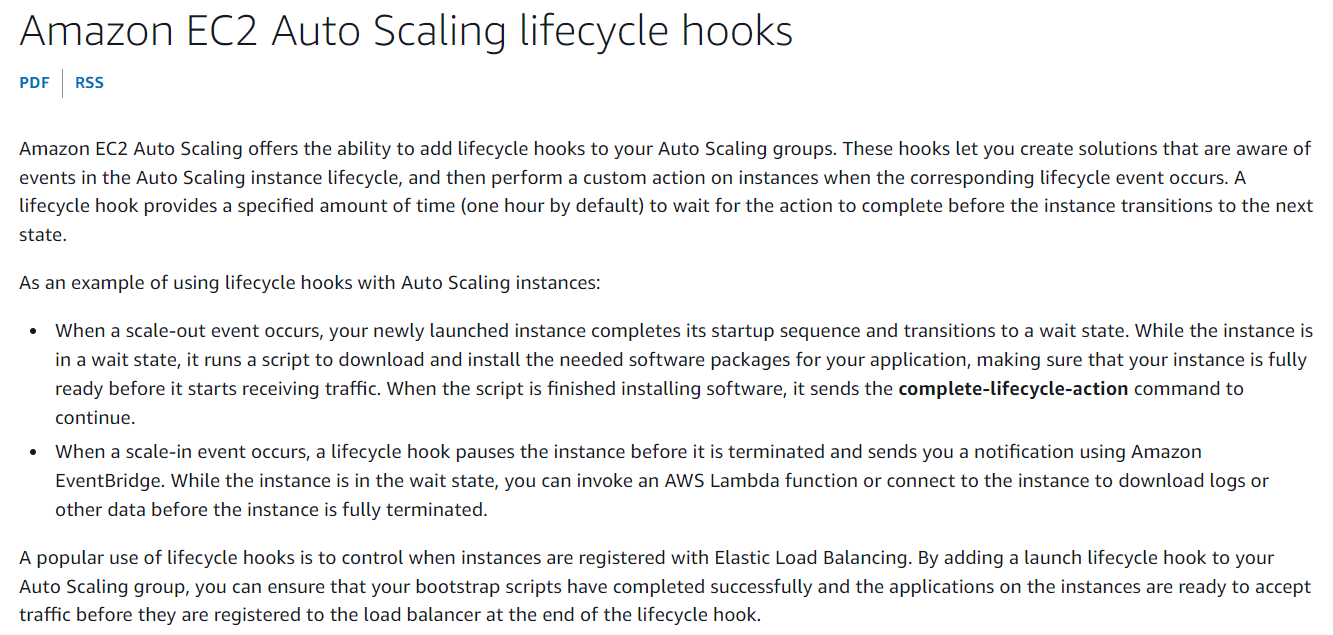
B.
Add lifecycle hooks to Auto Scaling group.
C.
Customize Termination policy to complete data copy before termination.
D.
Suspend Terminate process that will avoid data loss.
Correct Answer – B
Explanation: Adding Lifecycle Hooks to the Auto Scaling group puts the instance into a wait state
before termination. During this wait state, you can perform custom activities to retrieve critical
operational data from a stateful instance. The Default Wait period is 1 hour.
- Option A is incorrect as the cooldown period will not help copy data from the instance before
termination.
- Option C is incorrect as the Termination policy is used to specify which instances to terminate
first during scale-in. Configuring termination policy for the Auto Scaling group will not copy
data
before instance termination.
- Option D is incorrect as the Suspending Terminate policy will not prevent data loss but disrupt
other processes & prevent scale-in.
Question 29
You have an application running in us-west-2 that requires 6 EC2 Instances running at all times.
With 3 Availability Zones in the region us-west-2a, us-west-2b, and us-west-2c, which of the
following deployments provides fault tolerance if ONE Availability Zone in us-west-2 becomes
unavailable? (SELECT TWO.)
A.
2 EC2 Instances in us-west-2a, 2 EC2 Instances in us-west-2b, and 2 EC2 Instances in us-west-2c
B.
3 EC2 Instances in us-west-2a, 3 EC2 Instances in us-west-2b, and no EC2 Instances in us-west-2c
C.
4 EC2 Instances in us-west-2a, 2 EC2 Instances in us-west-2b, and 2 EC2 Instances in us-west-2c
D.
6 EC2 Instances in us-west-2a, 6 EC2 Instances in us-west-2b, and no EC2 Instances in us-west-2c
E.
3 EC2 Instances in us-west-2a, 3 EC2 Instances in us-west-2b, and 3 EC2 Instances in us-west-2c
Answer – D and E
Option D- US West 2a-6 , US West 2b - 6, US West 2c-0
If US West 2a goes down, we will still have 6 instances running in US West 2b.
If US West 2b goes down, we will still have 6 instances running in US West 2a.
If US West 2c goes down, we will still have 6 instances running in US West 2a, 6 instances running
in US West 2b.
Option E- US West 2a-3 , US West 2b - 3, US West 2c-3
If US West 2a goes down, we will still have 3 instances running in US West 2b and 3 instances
running in US West 2c.
If US West 2b goes down, we will still have 3 instances running in US West 2a and 3 instances
running in US West 2c.
If US West 2c goes down, we will still have 3 instances running in US West 2a and 3 instances
running in US West 2b.
- Option A is incorrect because, even if one AZ becomes unavailable, we will only have 4 instances
available. This does not meet the specified requirements.
- Option B is incorrect because, when either us-west-2a or us-west-2b is unavailable, you would only
have 3 instances available. This does not meet the specified requirements.
- Option C is incorrect because, if us-west-2a becomes unavailable, you would only have 4 instances
available. This also does not meet the specified requirements.
Question 30
There is an application that allows a manufacturing site to upload files. Each uploaded file of 2500
MB needs to extract metadata, which can take a few seconds per file for processing. The frequency at
which the uploading happens is unpredictable. Sometimes there can be no upload for hours, followed
by several files being uploaded concurrently.
Which architecture will address this workload in the most cost-efficient manner?
A.
Use a Kinesis Data Delivery Stream to store the file. Use Lambda for processing.
B.
Use an SQS queue to store the file to be accessed by a fleet of EC2 Instances.
C.
Store the file in an EBS volume, which can then be accessed by another EC2 Instance for processing.
D.
Store the file in an S3 bucket. Use Amazon S3 event notification to invoke a Lambda function for
file processing
Correct Answer: D
You can first create a Lambda function with the code to process the file.
Then, you can use an Event Notification from the S3 bucket to invoke the Lambda function whenever a
file is uploaded.
- Option A is incorrect as Kinesis is used to collect, process, and analyze real-time data.
- Option B is incorrect as SQS cannot store a message that is 3GB. The maximum payload supported by
SQS is 2GB.
To manage large Amazon Simple Queue Service (Amazon SQS) messages, you can use Amazon Simple
Storage
Service (Amazon S3) and the Amazon SQS Extended Client Library for Java. This is especially useful
for storing and consuming messages up to 2 GB.
- Option C is incorrect as EBS is a service to provide block-level storage. S3 is more suitable in
this scenario.
Note: The total volume of data and the number of objects you can store are unlimited. Individual
Amazon S3 objects can range in size from a minimum of 0 bytes to a maximum of 5 terabytes. The
largest object that can be uploaded in a single PUT is 5 gigabytes.
Question 31
You are part of an IT team who have created a streaming application. The application is hosted in
two separate regions, us-east-1(N Virginia) and ap-south-1 (Mumbai). Your application recently
became very popular, and now has users from all around the world. However, these new users have been
experiencing high latency in the application. How can you solve this problem, keeping in mind that
possible failovers in the app need to be solved very quickly?
A.
Enable a DNS-based traffic management solution with Geolocation route policies in Route53.
B.
Enable AWS WAF to securely serve your application content to the nearest Edge Locations to the
users.
C.
Enable Global Accelerator endpoint for your two regions.
D.
Enable Direct Connect
Correct Answer: C
- Option A is incorrect because if there is a failover, you will need to modify the source
application's IP address or configure Route53 records. That will take time to solve the
failover.
More details please check
https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html#routing-policy-geo
- Option B is incorrect because AWS WAF is a service to protect applications from attacks. It does
not
help to improve the performance or reduce latency.
- Option C is CORRECT because AWS Global Accelerator is a service that redirects users requests to
the
nearest edge location and then routes the data to the Amazon global network, increasing the speed
and security of data transfer, therefore, increasing the performance of our applications. It also
reroutes requests to healthy IPs if it fails and changes propagations. It is automatic and lasts
some seconds.
More details please check
https://aws.amazon.com/global-accelerator/faqs/
- Option D is incorrect because Direct Connect is a service used to increase data transfer between
On-Premise data centers and AWS services.
More
details: https://aws.amazon.com/directconnect/.
Here is the additional explanation on AWS website on Global accelerator FAQ. Why DNS/Route 53 is
an
inferior option as compared to Global accelerator.
Q: How is AWS Global Accelerator different from a DNS-based traffic management solution?
A: First, some client devices and internet resolvers cache DNS answers for long periods of time. So
when you make a configuration update, or there’s an application failure or change in your routing
preference, you don’t know how long it will take before all of your users receive updated IP
addresses. With AWS Global Accelerator, you don’t have to rely on the IP address caching settings of
client devices. Change propagation takes a matter of seconds, which reduces your application
downtime. Second, with Global Accelerator, you get static IP addresses that provide a fixed entry
point to your applications. This lets you easily move your endpoints between Availability Zones or
between AWS Regions, without having to update the DNS configuration or client-facing
applications.
Question 32
A new VPC with CIDR range 10.10.0.0/16 has been set up with a public and a private subnet. Internet
Gateway and a custom route table have been created, and a route has been added with the '
Destination’ as ‘0.0.0.0/0’ and the ‘Target’ with Internet Gateway ( igw-id ). A new Linux EC2
instance has been launched on the public subnet with the auto-assign public IP option enabled, but
the connection is getting failed when trying to SSH into the machine. What could be the reason?
A.
Elastic IP is not assigned.
B.
The NACL of the public subnet disallows the SSH traffic.
C.
A public IP address is not assigned.
D.
The Security group of the instance disallows the egress traffic on port 80.
Answer: B
- Option A is incorrect. An Elastic IP address is a public IPv4 address with which you can mask the
failure of an instance or software by rapidly remapping the address to another instance in your
account.
If your instance does not have a public IPv4 address, you can associate an Elastic IP address with
your instance to enable communication with the internet; for example, to connect to your instance
from your local computer.
From our problem statement, EC2 is launched with Auto-assign public IP enabled. So, since public IP
is available, Elastic IP is not necessary to connect from the internet.
- Option C is incorrect because the problem statement clearly states that EC2 is launched with
Auto-assign Public IP enabled, so this option cannot be true.
- Option B is CORRECT as the NCL may not allow the ingress SSH traffic so the connection failed to
connect.
- Option D is incorrect because SSH uses port 22. A security group is stateful and in this scenario,
the security group may disallow the ingress SSH traffic instead of egress.
Question 33
You need to install a 150 GB volume on an EC2 Instance for a new application. While the data in the
volume is used less frequently with small peaks in the morning and evening, which storage type would
be the most cost-effective option for the given requirement?
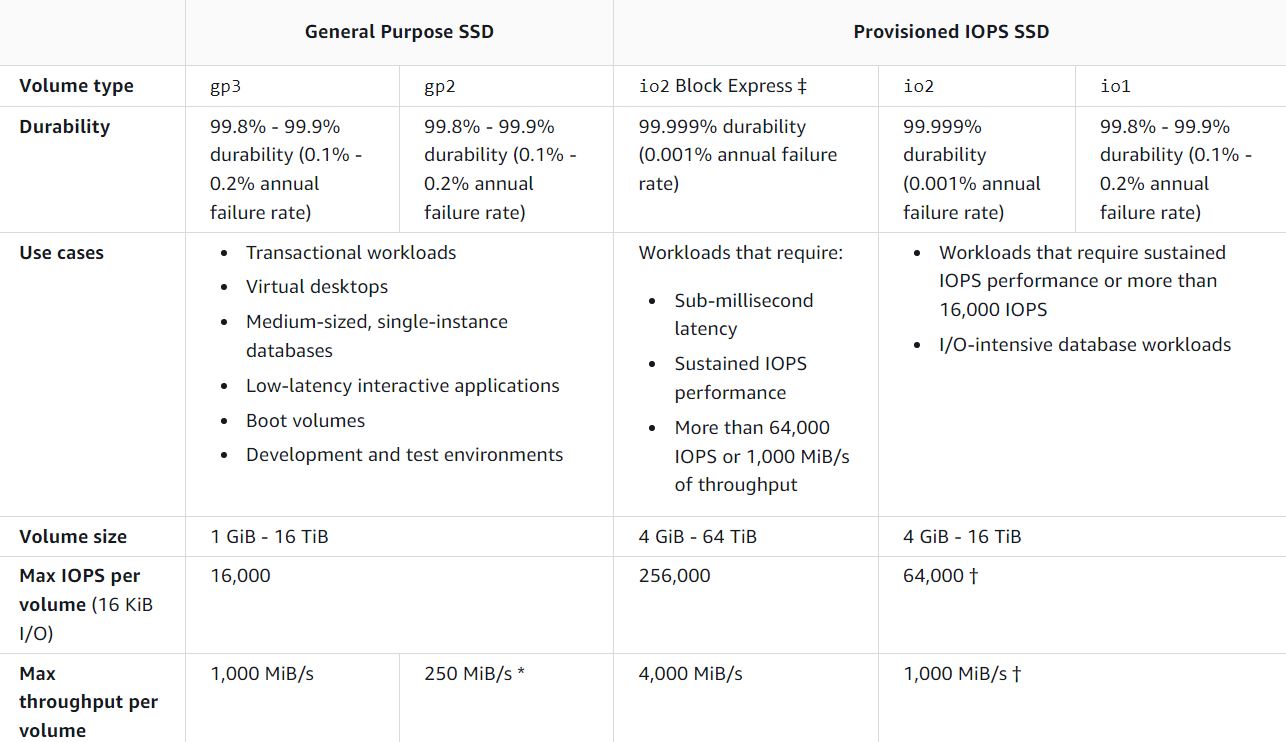
A.
Amazon EBS provisioned IOPS SSD.
B.
Amazon EBS Cold HDD.
C.
Amazon EBS General Purpose SSD.
D.
Amazon EFS.
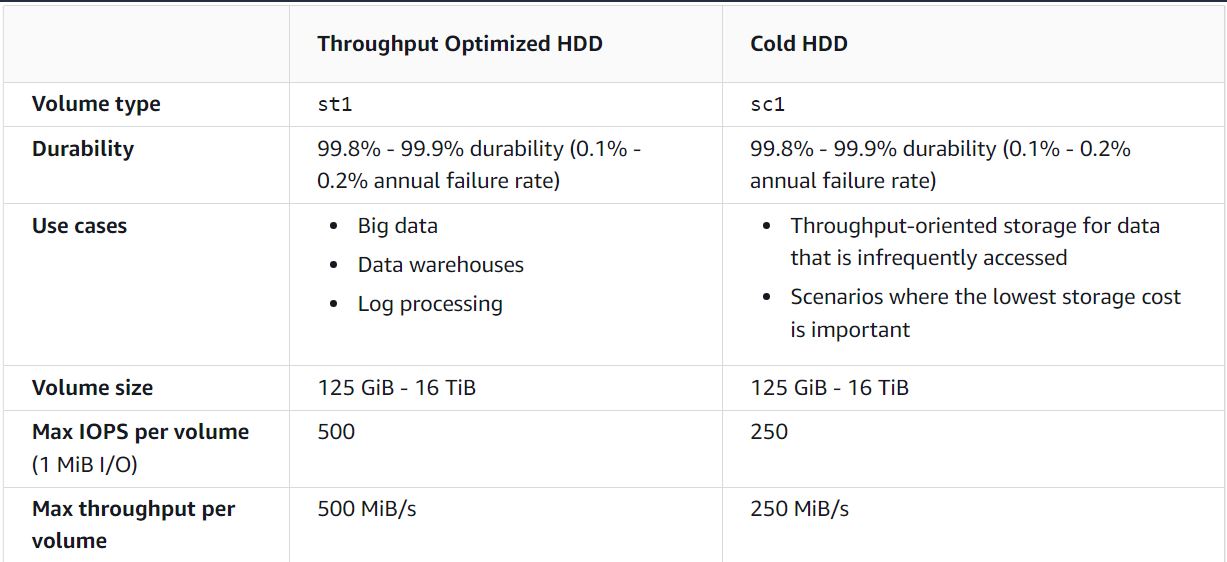
Answer – B
The volume data is used infrequently, not throughout the day, and the question requires the MOST
cost-effective storage type. So the preferred choice would be Amazon Cold HDD. Cold HDD is suitable
for the following scenarios:
Throughput-oriented storage for data that is infrequently accessed.
Scenarios where the lowest storage cost is important.
The volume size of EBS Cold HDD is 125 GiB - 16 TiB. The database size is 150G and is suitable in
this scenario.
Options A and C are incorrect as 'Provisioned IOPS SSD' and 'General Purpose SSD' are not
cost-efficient.
- Option D is incorrect because EFS is file storage, not block or volume storage. Hence not suitable
for the given requirement
Note: IOPS measures the number of reads and writes operations per second, while throughput measures
the number of bits reads or written per second.
Question 34
You are working as an AWS consultant for a start-up company. They have developed a web application,
that requires a lot of memory, for their employees to share files with external vendors securely.
They created an AutoScaling group for the web servers that require two m4.large EC2 instances
running at all times, scaling up to a maximum of twelve instances. Post-deployment of the
application, a huge rise in cost was observed. Due to a limited budget, the CTO has requested your
advice to optimize the usage of instances in the Auto Scaling groups. What do you suggest for
reducing the costs and minimizing the risk of adverse impact on the performance?
A.
Create an Auto Scaling group with t2. micro On-Demand instances.
B.
Create an Auto Scaling group with a mix of On-Demand & Spot Instance. Select the On-Demand base as
zero. Above On-Demand base, select 100% of On-Demand instance & 0% of Spot Instance.
C.
Create an Auto Scaling group with all Spot Instance.
D.
Create an Auto Scaling group with a mix of On-Demand & Spot Instance. Select the On-Demand base as
Above On-Demand base, select 20% of On-Demand instance & 80% of Spot Instance.
Correct Answer – D
Auto Scaling group supports a mix of On-Demand & Spot instances, which helps design a cost-optimized
solution without impacting the performance. You can choose the percentage of On-Demand & Spot
instances based on the application requirements. With Option D, the Auto Scaling group will have 2
instances initially as the On-Demand instances. In contrast, the remaining instances will be
launched in a 20 % On-Demand instance & 80% Spot Instance ratio.
No matter, if 80% of spot instances get terminated. The required 20% on-demand will be available
with 2 on-demand instances always running.
- Option A is incorrect. With t2. Micro, there would be a cost reduction, but it will impact the
performance of the application. The question requires that the performance is not impacted, so
changing the instance type is not suitable.
- Option B is incorrect as there would not be any cost reduction with all On-Demand
instances.
- Option C is incorrect. Although this will reduce cost, all spot instances in an auto-scaling group
may cause inconsistencies in the application & lead to poor performance.
Question 35
You are working as an AWS Architect for a start-up company. The company has a two-tier production
website on AWS with web servers in the front end & database servers in the back end. The third-party
firm has been looking after the operations of these database servers. They need to access these
database servers in private subnets on the SSH port. As per standard operating procedure provided by
the Security team, all access to these servers should be over a jumpbox accessible from internet.
What will be the best solution to meet this requirement?
A.
Deploy Bastion hosts in Private Subnet
B.
Deploy NAT Instance in Private Subnet
C.
Deploy NAT Instance in Public Subnet
D.
Deploy Bastion hosts in Public Subnet
Correct Answer – D
External users will be unable to access the instance in private subnets directly. To provide such
access, we need to deploy Bastion hosts in public subnets. In case of the above requirement,
third-party users will initiate a connection to Bastion hosts in public subnets & from there, they
will access SSH connection to database servers in private subnets.
- Option A is incorrect as Bastion hosts need to be in Public subnets & not in Private subnets, as
third-party users will be accessing these servers from the internet.
- Option B is incorrect as NAT instance is used to provide internet traffic to hosts in private
subnets. Users from the internet will not be able to do SSH connections to hosts in private
subnets
using NAT instance. NAT instance is always present in Public subnets.
- Option C is incorrect as NAT instance is used to provide internet traffic to hosts in private
subnets. Users from the internet will not be able to do SSH connections to hosts in private
subnets
using NAT instance.
- Option B and C (Deploy NAT Instance in Private/Public Subnet) are used to provide internet access
for outbound traffic from instances in private subnets but do not help with secure inbound access
to
the database servers via SSH.
Question 36
You are working for a start-up company that develops mobile gaming applications using AWS resources.
For creating AWS resources, the project team is using CloudFormation Templates. The Project Team is
concerned about the changes made in EC2 instance properties by the Operations Team, apart from
parameters specified in CloudFormation Templates. To observe changes in AWS EC2 instance, you advise
using CloudFormation Drift Detection. After Drift detection, when you check drift status for all AWS
EC2 instances, drift for certain property values with default values for resource properties is not
displayed. What would you do to include these resource properties to be captured in CloudFormation
Drift Detection?
A.
Run CloudFormation Drift Detection on individual stack resources instead of entire CloudFormation
stack.
B.
Explicitly set the property value, which can be the same as the default value.
C.
Manually check these resources as this is not supported in CloudFormation Drift Detection.
D.
Assign Read permission to CloudFormation Drift Detection to determine drift.
Correct Answer – B
AWS CloudFormation Drift Detection can be used to detect changes made to AWS resources outside the
CloudFormation Templates. AWS CloudFormation Drift Detection only checks property values explicitly
set by stack templates or by specifying template parameters. It does not determine drift for
property values that are set by default. To determine drift for these resources, you can explicitly
set property values that can be the same as that of the default value.
- Option A is incorrect. If property values are assigned explicitly to these properties, running AWS
CloudFormation Drift Detection would be detected in both individuals and the entire CloudFormation
Stack.
- Option C is incorrect as CloudFormation Drift Detection supports the AWS EC2 instance.
- Option D is incorrect. Since for all other resources, CloudFormation Drift Detection has already
determined drift, there is no other read permission to be granted further.
Question 37
You are responsible for performing a migration from your company’s on-premise data to the AWS cloud.
You have about 400 GB of data stored in an NFS. One requirement of this migration is to transfer
some of this data to AWS EFS and the other part to S3. Which is the easiest to use and with the most
cost-effective solution?
A.
Use AWS Storage gateway.
B.
Use S3 Transfer Acceleration.
C.
Use AWS DataSync.
D.
Use AWS Database Migration Service
Answer: C
- Option A is incorrect. Storage Gateway is a hybrid cloud storage service to share and access data
between your on-premise resources and AWS resources. It is not mainly designed to migrate data
from
On-Premise to AWS. Additionally, all three storage gateway patterns are backed by S3, not EFS.
More
details: https://aws.amazon.com/storagegateway/faqs/.
- Option B is incorrect. S3 Transfer Acceleration is used to transfer data to S3 using Amazon
CloudFront’s globally distributed edge locations, increasing data transfer speed. However, this
option doesn't work to transfer data to AWS EFS. More
details: https://docs.aws.amazon.com/AmazonS3/latest/dev/transfer-acceleration.html.
- Option C is CORRECT. DataSync is a service used to transfer data between on-premise storage to AWS
S3, EFS and FSx. It is cost-effective, easy to use, and can handle the transfer to EFS and S3.
More
details: https://aws.amazon.com/datasync/faqs/.
- Option D is incorrect because AWS Database Migration Service is used to migrate databases to AWS
databases like Aurora, DynamoDB, etc. In this scenario, we don’t mention a database migration, and
with this service, you can not transfer data to EFS nor S3. More
details: https://aws.amazon.com/dms/.
Question 38
A company hosts a popular web application that connects to an Amazon RDS MySQL DB instance running
in a default VPC private subnet with the default NACL settings created by AWS. The web servers must
be accessible only to customers on HTTPS connections, and the database must only be accessible to
web servers in a public subnet. Which solution would meet these requirements without impacting other
applications? (SELECT TWO)
A.
Create a network ACL on the Web Server’s subnets, allow HTTPS port 443 inbound and specify the
source as 0.0.0.0/0.
B.
Create a Web Server security group that allows HTTPS port 443 inbound traffic from anywhere (
0.0.0.0/0) and apply it to the Web Servers.
C.
Create a DB Server security group that allows MySQL port 3306 inbound and specify the source as the
Web Server security group.
D.
Create a network ACL on the DB subnet, allow MySQL port 3306 inbound for Web Servers and deny all
outbound traffic.
E.
Create a DB Server security group that allows HTTPS port 443 inbound and specify the source as a Web
Server security group.
Correct Answer – B and C
This sort of setup is explained in the AWS documentation.
1) To ensure that traffic can flow into your webserver from anywhere on secure traffic, you need to
allow inbound security at 443.
2) And then, you need to ensure that traffic can flow from the webserver to the database server via
the database security group.
The below snapshots from the AWS Documentation show rule tables for security groups related to the
same requirements as in the question.
Options A and D are incorrect. Network ACLs are stateless. So we need to set rules for both inbound
and outbound traffic for Network ACLs.
- Option E is incorrect because, in order to communicate with the MySQL servers, we need to allow
traffic to flow through port 3306.
Note: The above correct options are the combination of steps required to secure your web and
database servers. Besides, the company may implement additional security measures from their
end.
Question 39
You lead a team to develop a new web application in AWS EC2. The application will have a large
number of users globally. For a great user experience, this application requires very low network
latency and jitter. If the network speed is not fast enough, you will lose customers. Which tool
would you choose to improve the application performance? (Select TWO.)
A.
AWS VPN
B.
AWS Global Accelerator
C.
Direct Connect
D.
API Gateway
E.
CloudFront
Correct Answer – B, E
This web application has global users and needs low latency. Both CloudFront and Global Accelerator
can speed up the distribution of contents over the AWS global network.
- Option A is incorrect: AWS VPN links on-premise network to AWS network. However, no on-premise
services are mentioned in this question.
- Option B is CORRECT: AWS Global Accelerator works at the network layer and can direct traffic to
optimal endpoints. For reference, check the
link https://docs.aws.amazon.com/global-accelerator/latest/dg/what-is-global-accelerator.html.
- Option C is incorrect: Direct Connect links on-premise network to AWS network. However, no
on-premise services are mentioned in this question.
- Option D is incorrect: API Gateway is a regional service and cannot improve the application
performance. API Gateway is suitable for serverless applications such as Lambda.
- Option E is CORRECT: Because CloudFront delivers content through edge locations, and users are
routed to the edge location with the lowest time delay.
Question 40
A Solutions Architect is designing a highly scalable system to track records. These records must
remain available for immediate download for up to three months and then must be deleted. What is the
most appropriate decision for this use case?
A.
Store the files in Amazon EBS and create a Lifecycle Policy to remove files after 3 months.
B.
Store the files in Amazon S3 and create a Lifecycle Policy to remove files after 3 months.
C.
Store the files in Amazon Glacier and create a Lifecycle Policy to remove files after 3 months.
D.
Store the files in Amazon EFS and create a Lifecycle Policy to remove files after 3 months
Correct Answer – B
- Option A is incorrect since the records need to be stored in a highly scalable system.
- Option C is incorrect since the records must be available for immediate download.
- Option D is incorrect since EFS lifecycle management is used to migrate files that have not been
accessed for a certain period of time to the Infrequent Access storage class. Files moved to this
storage remain indefinitely and not get deleted. And due to this reason, this option is not
correct.
AWS Documentation mentions the following about Lifecycle Policies:
Lifecycle configuration enables you to specify the Lifecycle Management of objects in a bucket. The
configuration is a set of one or more rules, where each rule defines an action for Amazon S3 to
apply to a group of objects. These actions can be classified as follows:
Transition actions – In which you define when the transition of the object occurs to another storage
class. For example, you may choose to transition objects to the STANDARD_IA (IA, for infrequent
access) storage class 30 days after creation or archive objects to the GLACIER storage class one
year after creation.
Expiration actions – In which you specify when the objects will expire. Then Amazon S3 deletes the
expired objects on your behalf.
Question 41
A consulting firm repeatedly builds large architectures for their customers using AWS resources from
several AWS services, including IAM, Amazon EC2, Amazon RDS, DynamoDB and Amazon VPC. The
consultants have architecture diagrams for each of their architectures and are frustrated that they
cannot use them to create their resources automatically.
Which service should provide immediate benefits to the organization?
A.
AWS Elastic Beanstalk
B.
AWS CloudFormation
C.
AWS CodeBuild
D.
AWS CodeDeploy
Correct Answer - B
AWS CloudFormation enables consultants to use their architecture diagrams to construct
CloudFormation templates.
AWS CloudFormation is a service that helps you model and set up your Amazon Web Service resources.
You create a template that describes all the AWS resources that you want (like Amazon EC2 instances
or Amazon RDS DB instances), and AWS CloudFormation takes care of provisioning and configuring those
resources for you.
AWS Elastic Beanstalk is an easy-to-use service for deploying and scaling web applications and
services developed with Java, .NET, PHP, Node.js etc.
Options C and D are incorrect because Code Build and Code Deploy do not provision or configure
resources automatically via a template.
AWS CodeBuild is a fully managed continuous integration service that compiles source code, runs
tests, and produces software packages that are ready to deploy.
AWS CodeDeploy is a deployment service that automates application deployments to Amazon EC2
instances, on-premises instances, serverless Lambda functions, or Amazon ECS services.
Question 42
The security policy of an organization requires an application to encrypt data before writing to the
disk. Which solution should the organization use to meet this requirement?
A.
AWS KMS API
B.
AWS Certificate Manager
C.
API Gateway with STS
D.
IAM Access Key
Correct Answer – A
- Option B is incorrect. The AWS Certificate Manager can be used to generate SSL certificates to
encrypt traffic in transit, but not at rest.
- Option C is incorrect. It is used for issuing tokens while using the API gateway for traffic in
transit.
- Option D is used for providing secure access to EC2 Instances.
AWS Documentation mentions the following on AWS KMS:
AWS Key Management Service (AWS KMS) is a managed service that makes it easy for you to create and
control the encryption keys used to encrypt your data. AWS KMS is integrated with other AWS services
including Amazon Elastic Block Store (Amazon EBS), Amazon Simple Storage Service (Amazon S3), Amazon
Redshift, Amazon Elastic Transcoder, Amazon WorkMail, Amazon Relational Database Service (Amazon
RDS), and others to make it simple to encrypt your data with encryption keys that you manage.
Question 43
You have developed a new web application on AWS for a real estate firm. It has a web interface where
real estate employees upload photos of newly constructed houses in S3 buckets. Prospective buyers
log in to the website and access photos. The marketing team has initiated an intensive marketing
event to promote new housing schemes which will lead to customers who frequently access these
images. As this is a new application, you have no projection of traffic on the S3 bucket. You need
an S3 storage class that can automatically optimize the storage costs with changing access patterns.
Which of the following is a recommended storage solution to meet this requirement?
A.
Use One Zone-IA storage class to store all images.
B.
Use Standard-IA to store all images.
C.
Use S3 Intelligent-Tiering storage class.
D.
Use Standard storage class and use Storage class analytics to identify & move objects using
lifecycle policies
Correct Answer – C
When the access pattern to web applications using S3 storage buckets is unpredictable, you can use
S3 intelligent-Tiering storage class. S3 Intelligent-Tiering storage class includes two access
tiers: frequent access and infrequent access. Based upon access patterns, it moves data between
these tiers, which helps in cost saving. S3 Intelligent-Tiering storage class has the same
performance as that of Standard storage class.
- Option A is incorrect. Although it will save costs, it will not provide any protection in case of
AZ
failure. Also, this class is suitable for infrequently accessed data & not for frequently access
data.
- Option B is incorrect as Standard-IA storage class is for infrequently accessed data & there are
retrieval charges associated. In the above requirement, you do not know the data access pattern,
which may result in a higher cost.
- Option D is incorrect. It has operational overhead to set up Storage class analytics & moves
objects
between various classes. Also, since the access pattern is undetermined, this will run into a
costlier option.
Question 44
A company is developing a web application to be hosted in AWS. This application needs a data store
for session data.
As an AWS Solution Architect, what would you recommend as an ideal option to store session data? (
SELECT TWO)
A.
CloudWatch
B.
DynamoDB
C.
Elastic Load Balancing
D.
ElastiCache
E.
Storage Gateway
Correct Answer - B and D
DynamoDB and ElastiCache are perfect options for storing session data.
AWS Documentation mentions the following on Amazon DynamoDB:
Amazon DynamoDB is a fast and flexible NoSQL database service for all applications that need
consistent, single-digit millisecond latency at any scale. It is a fully managed cloud database and
supports both document and key-value store models. Its flexible data model, reliable performance,
and automatic scaling of throughput capacity make it a great fit for mobile, web, gaming, ad tech,
IoT, and many other applications.
For more information on AWS DynamoDB, please visit the following URL: https://aws.amazon.com/dynamodb/
AWS Documentation mentions the following on AWS ElastiCache:
AWS ElastiCache is a web service that makes it easy to set up, manage, and scale a distributed
in-memory data store or cache environment in the cloud. It provides a high-performance, scalable,
and cost-effective caching solution while removing the complexity associated with the deployment and
management of a distributed cache environment.
For more information on AWS Elasticache, please visit the following URL: https://docs.aws.amazon.com/AmazonElastiCache/latest/UserGuide/WhatIs.html
- Option A is incorrect. AWS CloudWatch offers cloud monitoring services for the customers of AWS
resources.
- Option C is incorrect. AWS Elastic Load Balancing automatically distributes incoming application
traffic across multiple targets.
- Option E is incorrect. AWS Storage Gateway is a hybrid storage service that enables your
on-premises
applications to use AWS cloud storage seamlessly.
Question 45
You are creating a new architecture for a financial firm. The architecture consists of some EC2
instances with the same type and size (M5.large). In this architecture, all the EC2 mostly
communicate with each other. Business people have asked you to create this architecture keeping in
mind low latency as a priority. Which placement group option could you suggest for the instances?
A.
Partition Placement Group
B.
Clustered Placement Group
C.
Spread Placement Group
D.
Enhanced Networking Placement Group
Answer: B
- Option A is incorrect. Partition Placement Groups distribute the instances in different
partitions.
The partitions are placed in the same AZ, but do not share the same rack. This type of placement
group does not provide low latency throughput to the instances. More details- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
- Option B is CORRECT. Clustered Placement Group places all the instances on the same rack. This
placement group option provides 10 Gbps connectivity between instances ( Internet connectivity in
the instances has a maximum of 5 Gbps). This option of placement group is perfect for the workload
that needs low latency. More details- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
- Option C is incorrect. Placement Groups place all the instances in different racks in the same AZ.
These types of placement groups do not provide low latency throughput to the instances. More
details- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
- Option D is incorrect. Enhanced Networking Placement Group does not exist. More details- https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
Question 46
A media company is looking for a solution to transcode media files into different formats for
efficient delivery across various devices. They need a service that can handle large volumes of
media files and automatically convert them into optimized formats. Which AWS service would you
recommend for this scenario?
A.
Amazon Kinesis Video Streams
B.
AWS IoT Core
C.
AWS IoT Greengrass
D.
Amazon Elastic Transcoder
Correct Answer: D
Amazon Elastic Transcoder is the correct option for this scenario. It is a scalable media
transcoding service that automatically converts media files into formats suitable for various
devices, making it ideal for efficiently delivering media content across different platforms.
- Option A is incorrect because Amazon Kinesis Video Streams is designed for securely capturing,
processing, and storing video streams for analytics and machine learning. It is not suitable for
media transcoding tasks like converting media files into different formats.
- Option B is incorrect because AWS IoT Core provides communication and management capabilities for
IoT devices, enabling secure connectivity and data exchange between devices and the cloud. It is
not
intended for media transcoding tasks.
- Option C is incorrect because AWS IoT Greengrass extends IoT functionality to edge devices,
allowing
local processing and secure communication between devices. However, it is not designed for media
transcoding tasks.
Question 47
A company has a media processing application deployed in a local data center. Its file storage is
built on a Microsoft Windows file server. The application and file server need to be migrated to
AWS. You want to set up the file server in AWS quickly. The application code should continue working
to access the file systems. Which method should you choose to create the file server?
A.
Create a Windows File Server from Amazon WorkSpaces.
B.
Configure a high performance Windows File System in Amazon EFS.
C.
Create FSx for Windows File Server.
D.
Configure a secure enterprise storage through Amazon WorkDocs
Correct Answer – C
In this question, a Windows file server is required in AWS, and the application should continue to
work unchanged. Amazon FSx for Windows File Server is the correct answer as it is backed by a fully
native Windows file system.
- Option A is incorrect because Amazon WorkSpace configures a desktop server which is not required
in
this question. Only a Windows file server is needed.
- Option B is incorrect because EFS cannot be used to configure a Windows file server.
- Option C is CORRECT because Amazon FSx provides fully managed Microsoft Windows file servers.
Check
the reference in
https://docs.aws.amazon.com/fsx/latest/WindowsGuide/what-is.html
- Option D is incorrect because Amazon WorkDocs is a file-sharing service in AWS. It cannot provide
a
native Windows file system.
Question 48
There is a requirement to get the source IP addresses that access resources in a private subnet.
Which of the following cost-optimized service could be used to fulfill this purpose?
A.
AWS Trusted Advisor
B.
VPC Flow Logs
C.
Use CloudWatch metrics
D.
Use CloudTrail
Correct Answer – B
The AWS Documentation mentions the following:
VPC Flow Logs is a feature that enables you to capture information about the IP traffic going to and
from network interfaces in your VPC. Flow log data is stored using Amazon CloudWatch Logs. After
you've created a flow log, you can view and retrieve its data in Amazon CloudWatch Logs.
- Option A is incorrect because AWS Trusted Advisor is your customized cloud expert! It helps you to
observe the best practices for using AWS by inspecting your AWS environment to save money, improve
system performance and reliability, and close security gaps.
- Option C is incorrect because CloudWatch Metric is mainly used for performance metrics and cannot
provide the source IP addresses.
- Option D is incorrect because AWS CloudTrail is a service that enables governance, compliance,
operational auditing, and risk auditing of your AWS account. With CloudTrail, you can log,
continuously monitor, and retain account activity related to actions across your AWS
infrastructure.
However, it is costly to use a CloudTrail.
Question 49
You are part of the IT team of a small car manufacturer company. The company is starting to move its
On-Premise resources to the cloud. The Marketing department was the first department to migrate its
applications to the cloud. Now the finance team wants to do the same. Each department should have
its own AWS account but you need one management account to pay for the bills of all the AWS
accounts. What do you suggest to solve this?
A.
Create a different VPC for the Finance Department and limit their access to resources with IAM Roles
and Policies.
B.
Use AWS Control Tower.
C.
Use AWS Organizations to manage both AWS accounts.
D.
Use AWS Cost Explorer to divide the bills and use IAM policies to limit the access to resources.
Correct Answer: C
- Option A is incorrect. This option does not cover the splitting bill requirements. Also, a
different
VPC is not the best option to separate projects or environments.
- Option B is incorrect. Control Tower is more suitable to automate a deployment in multi-account
environments. More details:
https://aws.amazon.com/controltower/faqs/
- Option C is CORRECT. With AWS Organizations, you can have separate bills for every account and pay
it with the same account using consolidating billing. More details:
https://aws.amazon.com/organizations/faqs/
- Option D is incorrect. With AWS Cost Explorer, you can analyze and explore your bills and service
usage in the account. But in the end, there will be one bill for the account. More details-
https://aws.amazon.com/aws-cost-management/faqs/
Question 50
Your team is developing a high-performance computing (HPC) application. The application resolves
complex, compute-intensive problems and needs a high-performance and low-latency Lustre file system.
You need to configure this file system in AWS at a low cost. Which method is the most suitable?
A.
Create a Lustre file system through Amazon FSx.
B.
Launch a high performance Lustre file system in Amazon EBS.
C.
Create a high-speed volume cluster in EC2 placement group.
D.
Launch the Lustre file system from AWS Marketplace
Correct Answer – A
The Lustre file system is an open-source, parallel file system that can be used for HPC
applications. Refer tohttp://lustre.org/
for its introduction. In Amazon FSx, users can quickly launch a Lustre file system at a low
cost.
- Option A is CORRECT: Amazon FSx supports Lustre file systems, and users pay for only the resources
they use.
- Option B is incorrect: Although users may be able to configure a Lustre file system through EBS,
it
needs lots of extra configurations. - Option A is more straightforward.
- Option C is incorrect: Because the EC2 placement group does not support a Lustre file
system.
- Option D is incorrect: Because products in AWS Marketplace are not cost-effective. For Amazon FSx,
there are no minimum fees or set-up charges. Check its pricing in
https://aws.amazon.com/fsx/lustre/pricing/.
Question 51
An EC2 instance in the private subnet needs access to the S3 bucket placed in the same region as
that of the EC2 instance. The EC2 instance needs to upload and download bigger files to the S3
bucket frequently.
As an AWS Solutions Architect, what quick and cost-effective solution would you suggest to your
customers? You need to consider that the EC2 instances are present in the private subnet, and the
customers do not want their data to be exposed over the internet.
A.
Place the S3 bucket in another public subnet of the same region and create a VPC peering connection
to this private subnet where the EC2 instance is placed. The traffic to upload and download files
will go through secure Amazon’s private network.
B.
Create an IAM role having access over the S3 service and assign it to the EC2 instance.
C.
Create a VPC endpoint for S3, use your route tables to control which instances can access resources
in Amazon S3 via the endpoint. The traffic to upload and download files will go through the Amazon
private network.
D.
A private subnet can always access S3 bucket/ service through the NAT Gateways or NAT instances, so
there is no need for additional setup.
Correct Answer: C
- Option A is incorrect because the S3 service is region-specific, not AZ’s specific, and the
statement talks about placing the S3 bucket in Public Subnet.
- Option B is incorrect because the VPC endpoint has a policy that controls the use of the endpoint
to
access Amazon S3 resources. The default policy allows access by any user or service within the
VPC,
using credentials from any AWS account to any Amazon S3 resource. (Creating an IAM role) grants
permissions but does not solve the network routing issue for instances in a private subnet. The
IAM
role alone won't enable access to S3 without proper network configuration.
- Option C is correct. It can help to access the S3 services in the same region for the EC2
instance.
You can create a VPC endpoint and update the route entry of the route table associated with the
private subnet. This is a quick solution as well as cost-effective as it will use Amazon's own
private network. Hence, it won’t expose the data over the internet.
- Option D is incorrect as this is certainly not a default setup unless we create a NAT Gateway or
Instance. Even if they are there, it’s an expensive solution and exposes the data over the
internet.
Question 52
An application needs to access resources from another AWS account of another VPC in the same region.
Which of the following ensure that the resources can be accessed as required?
A.
Establish a NAT instance between both accounts.
B.
Use a VPN between both accounts.
C.
Use a NAT Gateway between both accounts.
D.
Use VPC Peering between both accounts.
Correct Answer – D
Options A and C are incorrect because these are used when private resources are required to access
the Internet.
- Option B is incorrect because it's used to create a connection between the On-premises and AWS
resources.
AWS Documentation mentions the following about VPC Peering:
A VPC peering connection is a networking connection between two VPCs that enables you to route
traffic between them privately. Instances in either VPC can communicate with each other as if they
are within the same network. You can create a VPC Peering connection between your own VPCs, with a
VPC in another AWS account, or with a VPC in a different AWS Region.
Question 53
You host a static website in an S3 bucket, and there are global clients from multiple regions. You
want to use an AWS service to store cache for frequently accessed content so that the latency is
reduced and the data transfer rate increases. Which of the following options would you choose?
A.
Use AWS SDKs to horizontally scale parallel requests to the Amazon S3 service endpoints.
B.
Create multiple Amazon S3 buckets and put Amazon EC2 and S3 in the same AWS Region.
C.
Enable Cross-Region Replication to several AWS Regions to serve customers from different locations.
D.
Configure CloudFront to deliver the content in the S3 bucket.
Correct Answer – D
CloudFront can store the frequently accessed content as a cache, and the performance is optimized.
Other options may help with the performance. However, they do not store cache for the S3
objects.
- Option A is incorrect: This option may increase the throughput. However, it does not store
cache.
- Option B is incorrect: The given architecture cannot be used to cache the content.
- Option C is incorrect: This option creates multiple S3 buckets in different regions. It does not
improve the performance using cache.
- Option D is CORRECT: CloudFront caches the S3 files in its edge locations. Users are routed to the
edge location that has the lowest latency.
Question 54
An application consists of the following VPC architecture:
a. EC2 Instances in multiple AZ’s behind an ELB
b. EC2 Instances are launched via an Auto Scaling Group.
c. There is one NAT Gateway for all AZ’s instances to download the updates from the Internet.
What is a bottleneck in the architecture based on the availability?
A.
The EC2 Instances
B.
The ELB
C.
The NAT Gateway
D.
The Auto Scaling Group
Correct Answer – C
Since there is only one NAT Gateway, this is a bottleneck in the architecture. For high
availability, launch NAT Gateways in multiple Available Zones.
If you have resources in multiple Availability Zones and they share one NAT gateway, and if the NAT
gateway’s Availability Zone is down, resources in the other Availability Zones lose internet access.
To create an Availability Zone-independent architecture, create a NAT gateway in each Availability
Zone and configure your routing to ensure that resources use the NAT gateway in the same
Availability Zone.
Question 55
You have an application hosted in an Auto Scaling group, and an application load balancer
distributes traffic to the ASG. You want to add a scaling policy that keeps the average aggregate
CPU utilization of the Auto Scaling group to be 60 percent. The capacity of the Auto Scaling group
should increase or decrease based on this target value. Which scaling policy does it belong to?
A.
Target tracking scaling policy.
B.
Step scaling policy.
C.
Simple scaling policy.
D.
Scheduled scaling policy.
Correct Answer – A
In ASG, you can add a target tracking scaling policy based on a target. For different scaling
policies, please check
https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-scale-based-on-demand.html
- Option A is CORRECT: Because a target tracking scaling policy can be applied to check the
ASGAverageCPUUtilization metric according to
https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-scaling-target-tracking.html.
- Option B is incorrect: Because Step scaling adjusts the capacity based on step adjustments instead
of a target.
- Option C is incorrect: Because Simple scaling changes the capacity based on a single
adjustment.
- Option D is incorrect: With Scheduled scaling, the capacity is adjusted based on a schedule rather
than a target.
Question 56
An application hosted on EC2 Instances has its promotional campaign due to start in 2 weeks. The
performance team performs some analysis based on the historical data and informs you the number of
instances that are required for the campaign. You need to make sure that the Auto Scaling group is
properly configured with the provided number of instances. What should be done to fulfill this
requirement?
A.
Migrate the application from the Auto Scaling group to a Lambda function so that the application
scales automatically by AWS.
B.
Configure Scheduled scaling in the Auto Scaling Group.
C.
Configure a Lambda function that scales up the ASG when the activity starts and scales down when the
activity ends.
D.
Configure Static scaling for the Auto Scaling Group.
Correct Answer – B
In the question, the promotional campaign will start in 2 weeks. As you already know how many
instances are required, you can configure a scaling schedule in the Auto Scaling group to plan the
scaling actions.
- Option A is incorrect because it is unsuitable to migrate the application to a Lambda function
since
the campaign will start in 2 weeks. You can configure an Auto Scaling policy for the
campaign.
- Option C is incorrect because it is easier to use an Auto Scaling policy to achieve this
requirement.
- Option D is incorrect because there is no static scaling policy in an Auto Scaling group.
Question 57
Currently, a company uses EBS snapshots to back up their EBS Volumes. As a part of the business
continuity requirement, these snapshots need to be made available in another region. How could this
be achieved?
A.
Directly create the snapshot in another region.
B.
Create a snapshot and copy it to another region.
C.
Copy the snapshot to an S3 bucket and then enable Cross-Region Replication for the bucket.
D.
Copy the EBS Snapshot to an EC2 instance in another region
Correct Answer - B
This scenario is not about automation (although it can indeed be automated) but extending resiliency
through a backup strategy. There is no access to the bucket where snapshots are automatically backed
upon and that is why cross-region replication is not an option in this context.
AWS Documentation mentions the following:
With Amazon EBS, you can create point-in-time snapshots of volumes, which we store for you in Amazon
S3. After you create a snapshot and it has finished copying to Amazon S3 (when the snapshot status
is
completed
), you can copy it from one AWS Region to another, or within the same Region.
For more information on EBS Snapshots, please visit the following URL: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-copy-snapshot.html
For more information on Restoring an Amazon EBS Volume from a Snapshot, please visit the following
URL: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-restoring-volume.html
- Option C is incorrect because we can't directly use Cross-region replication. It requires a
replication configuration for the source bucket. EBS snapshots are stored in S3, which is managed
by
AWS. We don't have the option to see the snapshots in S3.
S3 Cross-Region Replication (CRR) is used to copy objects across Amazon S3 buckets in different AWS
Regions.
For CRR, there is a requirement to add replication configuration to your source bucket and nothing
is mentioned about the source or destination bucket in the requirement. https://docs.aws.amazon.com/AmazonS3/latest/userguide/replication.html
- Option D is incorrect because there is no need for an EC2 instance in this scenario. https://docs.aws.amazon.com/AmazonS3/latest/userguide/replication.html
Question 58
A company has an application hosted in AWS. This application consists of EC2 Instances that sit
behind an ELB. The following are the requirements from an administrative perspective:
a) Ensure that notifications are sent when the read requests go beyond 1000 requests per minute.
b) Ensure that notifications are sent when the latency goes beyond 10 seconds.
c) Monitor all AWS API request activities on the AWS resources.
Which of the following can be used to satisfy these requirements? (SELECT TWO)
A.
Use CloudTrail to monitor the API Activity.
B.
Use CloudWatch Logs to monitor the API Activity.
C.
Use CloudWatch Metrics for the metrics that need to be monitored as per the requirement and set up
an alarm activity to send out notifications when the metric reaches the set threshold limit.
D.
Use custom log software to monitor the latency and read requests to the ELB.
Correct Answer – A and C
- Option A is correct. CloudTrail is a web service that records AWS API calls for all the resources
in
your AWS account. It also delivers log files to an Amazon S3 bucket. The recorded information
includes the identity of the user, the start time of the AWS API call, the source IP address, the
request parameters, and the response elements returned by the service. https://docs.aws.amazon.com/awscloudtrail/latest/APIReference/Welcome.html
- Option B is incorrect because CloudWatch Logs can be used to monitor log files from other
services.
CloudWatch Logs and CloudWatch are different.
Amazon CloudWatch Logs are used to monitor, store, and access your log files from Amazon Elastic
Compute Cloud (Amazon EC2) instances, AWS CloudTrail, Route 53, and other sources. CloudWatch Logs
reports the data to a CloudWatch metric.
Rather you can monitor Amazon EC2 API requests using Amazon CloudWatch. https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html
- Option C is correct. Use Cloudwatch Metrics for the metrics that need to be monitored as per the
requirement. Set up an alarm activity to send out notifications when the metric reaches the set
threshold limit. https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-cloudwatch-metrics.html
- Option D is incorrect because there is no need to use custom log software as you can set up
CloudWatch alarms based on CloudWatch Metrics.
Question 59
You are part of the IT sector at the finance department of your company. Your organization has
implemented AWS Organizations for each internal department, and you have access to the Management
account. You need to manage Amazon EC2 Dedicated Hosts centrally, and share the host’s instance
capacity with other AWS accounts in the AWS Organizations. How can you accomplish this in the
easiest way?
A.
Use AWS Resource Access Manager to manage the EC2 Dedicated Hosts centrally and share them with
other member accounts.
B.
Use service control policies to share the EC2 Dedicated Hosts in the member accounts.
C.
Use AWS Control Tower.
D.
Create IAM policies with conditions and assign them to users in every member account
Correct Answer: A
- Option A is CORRECT. With AWS Resource manager, you can share resources with other AWS accounts
joined to your AWS Organizations reducing the operational overhead. More details:
https://docs.aws.amazon.com/ram/latest/userguide/shareable.html#shareable-ec2
- Option B is incorrect. SCP is not a service to share resources such as EC2 Dedicated Hosts with
other accounts within the AWS Organizations.
- Option C is incorrect. AWS Control Tower is used to do automated deployments in multi-account
environments.
- Option D is incorrect. Creating IAM policies is not used to manage and share resources within the
AWS Organizations.
Question 60
There is a multi-region website hosted in AWS EC2 under an ELB. Route 53 is used to manage its DNS
record. The website might get a lot of traffic over the next couple of weeks. If the application
experiences a natural disaster in the region during the time, what should be used to reduce
potential disruption to users?
A.
Use an ELB to divert traffic to an Infrastructure hosted in another region.
B.
Use an ELB to divert traffic to an Infrastructure hosted in another AZ.
C.
Use CloudFormation to create backup resources in another AZ.
D.
Use Route53 to route requests to another instance in a different region
Correct Answer – D
In a disaster recovery scenario, the best choice out of all given options is to divert the traffic
to a static website.
- Option A is wrong because ELB can only balance traffic in one region, not across multiple
regions.
Options B and C are incorrect because using backups across AZs is not enough for disaster recovery
purposes.
For more information on disaster recovery in AWS, please visit the following URLs: https://aws.amazon.com/premiumsupport/knowledge-center/fail-over-s3-r53/ https://aws.amazon.com/disaster-recovery/
The wording "to reduce the potential disruption in case of issues" points to a disaster recovery
situation. There is more than one way to manage this situation. However, we need to choose the best
option from the list given here. Out of this, the most suitable one is Option D.
Most organizations try to implement High Availability (HA) instead of DR to guard them against any
downtime of services. In the case of HA, we ensure that there exists a fallback mechanism for our
services. The service that runs in HA is handled by hosts running in different availability zones
but the same geographical region. However, this approach does not guarantee that our business will
be up and running in case the entire region goes down.
DR takes things to a completely new level, wherein you need to recover from a different region that
is separated by over 250 miles. Our DR implementation is an Active/Passive model, meaning that we
always have minimum critical services running in different regions. But a major part of the
infrastructure is launched and restored when required.
For more information on large scale disaster recovery using AWS regions, please visit the following
URL: https://aws.amazon.com/blogs/startups/large-scale-disaster-recovery-using-aws-regions/
Note:
Usually, when we discuss a disaster recovery scenario, we assume that the entire region is affected
due to some disaster. So we need the service to be provided from yet another region. So, setting up
a solution in another AZ will not work as it is in the same region. - Option A is incorrect though
it
mentions yet another region because ELBs cannot span across regions.
So out of the options provided, - Option D is the most suitable solution.
Question 61
A database, hosted using the Amazon RDS service, is getting many database queries. It has now become
a bottleneck for the associating application. Which action would ensure that the database is not a
performance bottleneck?
A.
Setup a CloudFront distribution in front of the database.
B.
Setup an ELB in front of the database.
C.
Setup ElastiCache in front of the database.
D.
Setup SNS in front of the database.
Correct Answer – C
ElastiCache is an in-memory solution that can be used in front of a database to cache the common
queries issued against the database. This can reduce the overall load on the database.
- Option A is incorrect because this is normally used for content distribution.
- Option B is partially correct. But you need to have one more database as an internal load
balancing
solution.
- Option D is incorrect because SNS is a simple notification service.
Question 62
A database is being hosted using the Amazon RDS service. This database will be deployed in
production and needs to be highly available. Which of the following could be used to achieve this
requirement?
A.
Use Multi-AZ for the RDS instance to ensure that a secondary database is created in another region.
B.
Use the Read Replica feature to create another instance of the DB in another region.
C.
Use Multi-AZ for the RDS instance to ensure that a secondary database is created in another
Availability Zone.
D.
Use the Read Replica feature to create another instance of the DB in another Availability Zone.
Correct Answer - C
- Option A is incorrect because the Multi-AZ feature allows high availability across Availability
Zones, not regions.
Options B and D are incorrect because Read Replicas can be used to offload database reads. But if
you want high availability, the Multi-AZ feature is required.
AWS Documentation mentions the following:
Amazon RDS Multi-AZ deployments provide enhanced availability and durability for Database (DB)
Instances. When you provision a Multi-AZ DB Instance, Amazon RDS automatically creates a primary DB
Instance and synchronously replicates the data to a standby instance in a different Availability
Zone (AZ).
Question 63
You need to launch several EC2 instances to run Cassandra. There are large distributed and
replicated workloads in Cassandra and you plan to launch instances using EC2 placement groups. The
traffic should be distributed evenly across several partitions and each partition should contain
multiple instances. Which of the following placement groups would you use to achieve the
requirement?
A.
Cluster placement group
B.
Spread placement group
C.
Partition placement group
D.
Network placement group
Correct Answer – C
Placement groups have the placement strategies of Cluster, Partition, and Spread. With the Partition
placement strategy, instances in one partition do not share the underlying hardware with other
partitions. This strategy is suitable for distributed and replicated workloads such as
Cassandra.
- Option A is incorrect. Cluster placement group puts instances together in an availability zone.
This
does not resolve the problem mentioned in the question.
- Option B is incorrect because Spread placement group puts instances across different racks. It
does
not group instances in a partition.
- Option C is CORRECT: With the Partition placement group, instances in a partition have their own
set
of racks.
- Option D is incorrect: Because there is no Network placement group.
Question 64
You are creating several EC2 instances for a new application. The instances need to communicate with
each other. For a better performance of the application, both low network latency and high network
throughput are required for the EC2 instances. All instances should be launched in a single
availability zone. How would you configure this?
A.
Launch all EC2 instances in a placement group using a Cluster placement strategy.
B.
Auto assign a public IP when launching the EC2 instances.
C.
Launch EC2 instances in an EC2 placement group and select the Spread placement strategy.
D.
When launching the EC2 instances, select an instance type that supports enhanced networking
Correct Answer – A
The Cluster placement strategy helps to achieve a low-latency and high throughput network. The
reference is in
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html#placement-groups-limitations-partition
- Option A is CORRECT: The Cluster placement strategy can improve the network performance among EC2
instances. The strategy can be selected when creating a placement group.
- Option B (Auto assign a public IP) does not affect network performance within an Availability
Zone.
Public IPs are primarily used for communication over the internet and are irrelevant for
optimizing
internal communication between EC2 instances.
- Option C (Spread placement strategy) is designed to maximize instance resilience by spreading
instances across multiple hardware to reduce the risk of simultaneous failure. While it improves
fault tolerance, it does not enhance network performance between instances like a Cluster
placement
strategy does.
- Option D Enhanced networking improves network performance by providing higher bandwidth and lower
latency. However, it is not as effective as a Cluster placement strategy for achieving the highest
performance in inter-instance communication.
Question 65
A company hosts 5 web servers in AWS. They want to ensure that multiple values for a DNS query
should be returned and traffic routed to multiple IP addresses. In addition, you want to associate
your routing records with a Route 53 health check. Which routing policy should be used to fulfill
this requirement?
A.
Simple
B.
Weighted
C.
Multivalue Answer
D.
Latency
Correct Answer - C
The AWS Documentation mentions the following to support this:
If you want to route traffic randomly to multiple resources such as web servers, you can create one
multivalue answer record for each resource and, optionally, associate an Amazon Route 53 health
check with each record.
For example, suppose you manage an HTTP web service with a dozen web servers where each has its own
IP address. No web server could handle all the traffic. But if you create a dozen multivalue answer
records, Amazon Route 53 responds to DNS queries with up to eight healthy records in response to
each DNS query. Amazon Route53 gives different answers to different DNS resolvers. If a web server
becomes unavailable after a resolver cache a response, client software can try another IP address in
the response.
Simple routing policy – Use a single resource that performs a given function for your domain, such
as a web server that serves the example.com website.
Latency routing policy – Use when you have resources in multiple locations, and you want to route
traffic to the resource that provides the best latency.
Weighted routing policy – Use to route traffic to multiple resources in proportions that you
specify.
Multivalue answer routing policy – Use when you want Route53 to respond to DNS queries with up to
eight healthy records selected randomly.