400+ Câu hỏi luyện thi chứng chỉ AWS Certified Solutions Architect Associate (SAA-C03) - Phần 4
aws
aws certification
cloud computing
solutions architect
saa c03
aws exam
practice test
Question 1
A start-up firm has created a cloud storage application that gives users the ability to store any
amount of personal data & share them with their connections. For this, they are using Amazon S3
buckets to store user data. The firm has used Amazon S3 multipart upload to upload large objects in
parts. During the last quarter, the finance team has observed a surge in storage costs for the S3
bucket. On further checking, the firm observed that many 100 GB files are uploaded by users & are in
a partially completed state.
As an AWS consultant, the IT Team requests you prevent this from happening again. Which of the
following actions can be taken to meet this requirement cost-effectively with the least effort?
A.
Create an S3 lifecycle Configuration to abort incomplete multipart uploads.
B.
Manually delete incomplete multipart uploads from the S3 bucket.
C.
Use Cron tool to identify incomplete uploads & delete those files.
D.
No action is required. All Incomplete uploads are automatically deleted every three months by Amazon
S3.
Correct Answer – A
Amazon S3 Lifecycle rules can be configured to abort all multipart uploads which are failing to
complete in a specific time period. For all files from size 5 MB to 5GB, the multipart upload can be
used.
- Option B is incorrect as this will need additional manual efforts.
- Option C is incorrect as this incurs additional cost & admin work to use Cron tools.
- Option D is incorrect as incomplete uploads are not automatically deleted.
Question 2
Your Operations department is using an incident-based application hosted on a set of EC2 Instances.
These instances are placed behind an Auto Scaling Group to ensure that the right number of instances
are in place to support the application. The Operations department has expressed dissatisfaction
concerning poor application performance every day at 9:00 AM. However, it is also noted that the
system performance returns to optimal at 9:45 AM.
What could be done to fix this issue?
A.
Create another Dynamic Scaling Policy to ensure that the scaling happens at 9:00 AM.
B.
Add another Auto Scaling group to support the current one.
C.
Change the Cool Down Timers for the existing Auto Scaling Group.
D.
Add a Scheduled Scaling Policy at 8:30 AM.
Correct Answer - D
Scheduled Scaling can be used to ensure that the capacity is peaked before 9:00 AM every day.
AWS Documentation further mentions the following on Scheduled Scaling:
Scaling based on a schedule allows you to scale your application in response to predictable load
changes. For example, every week the traffic to your web application starts to increase on
Wednesday, remains high on Thursday, and starts to decrease on Friday. You can plan your scaling
activities based on the predictable traffic patterns of your web application.
- Option A is incorrect because a scheduled scaling should be used as per the requirements of the
question instead of dynamic scaling.
- Option B is incorrect because adding another autoscaling group will not solve the problem.
- Option C is incorrect because changing the cooldown timers of the existing autoscaling group will
not meet the requirements of the question.
Question 3
You have created an AWS Lambda function that will write data to a DynamoDB table. Which of the
following must be in place to ensure that the Lambda function can interact with the DynamoDB table?
A.
Ensure an IAM Role is attached to the Lambda function which has the required DynamoDB privileges.
B.
Ensure an IAM User is attached to the Lambda function which has the required DynamoDB privileges.
C.
Ensure the Access keys are embedded in the AWS Lambda function.
D.
Ensure the IAM user password is embedded in the AWS Lambda function
Correct Answer – A
AWS Documentation mentions the following to support this requirement:
Each Lambda function has an IAM role (execution role) associated with it. You specify the IAM role
when you create your Lambda function. Permissions you grant to this role determine what AWS Lambda
can do when it assumes the role. There are two types of permissions that you grant to the IAM
role:
Suppose your Lambda function code accesses other AWS resources, such as reading an object from an S3
bucket or writing logs to CloudWatch Logs. In that case, you need to grant permissions for relevant
Amazon S3 and CloudWatch actions to the role.
If the event source is stream-based (Amazon Kinesis Data Streams and DynamoDB streams), AWS Lambda
polls these streams on your behalf. AWS Lambda needs permissions to poll the stream and read new
records on the stream. So you need to grant the relevant permissions to this role.
- Option B is incorrect. IAM user is an entity that you create in AWS to represent the person or
application. 'IAM users get attached to a Lambda function' is an irrelevant sentence.
- Option C is incorrect. Access keys are used to sign programmatic requests to the AWS CLI or AWS
API.
Access keys consist of two parts: an access key ID and a secret access key like a user name and
password. It is not a secure practice to add keys in the Lambda function.
- Option D is incorrect. IAM user passwords should never be embedded in the Lambda function. Rather
you can use environment variables to store secrets securely for use with Lambda functions.
Question 4
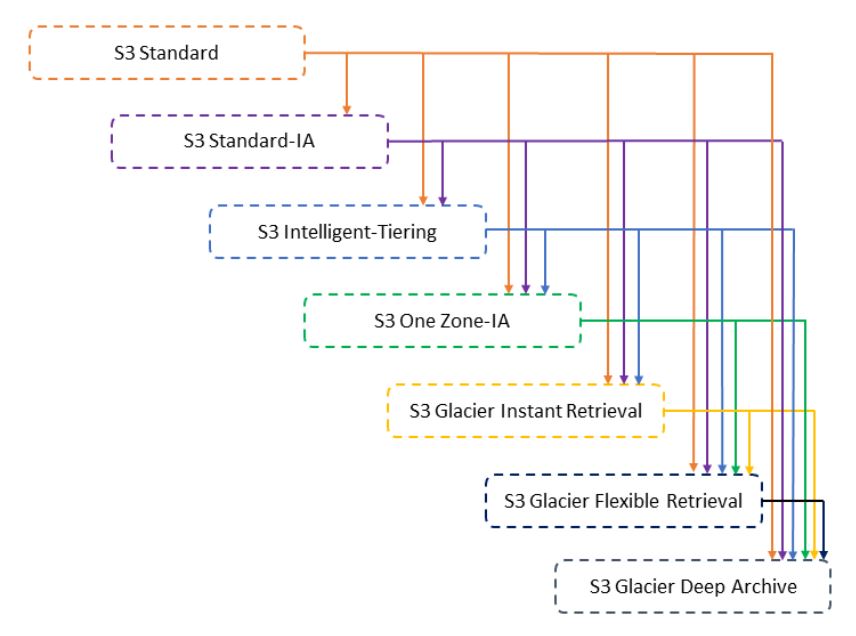
A Media firm is saving all its old videos in S3 Glacier Deep Archive. Due to the shortage of new
video footage, the channel has decided to reuse all these old videos. Since these are old videos,
the channel is not sure of their popularity & response from users. Channel Head wants to make sure
that these huge size files do not shoot up their budget. For this, as an AWS consultant, you advise
them to use the S3 intelligent storage class. The Operations Team is concerned about moving these
files to the S3 Intelligent-Tiering storage class. Which of the following actions can be taken to
move objects in Amazon S3 Glacier Deep Archive to the S3 Intelligent-Tiering storage class?
A.
Use Amazon S3 Console to copy these objects from S3 Glacier Deep Archive to the required S3
Intelligent-Tiering storage class.
B.
Use Amazon S3 Glacier Console to restore objects from S3 Glacier Deep Archive & then copy these
objects to the required S3 Intelligent-Tiering storage class.
C.
Use Amazon S3 console to restore objects from S3 Glacier Deep Archive & then copy these objects to
the required S3 Intelligent-Tiering storage class.
D.
Use the Amazon S3 Glacier console to copy these objects to the required S3 Intelligent-Tiering
storage class.
Correct Answer – C
To move objects from Glacier Deep Archive to different storage classes, first, need to restore them
to original locations using the Amazon S3 console & then use the lifecycle policy to move objects to
the required S3 Intelligent-Tiering storage class.
Options A & D are incorrect as Objects in Glacier Deep Archive cannot be directly moved to another
storage class. These need to be restored first & then copied to the desired storage class.
- Option B is incorrect as the Amazon S3 Glacier console can be used to access the vaults and
objects
in them. But it cannot be used to restore the objects.
For more information on moving objects between S3 storage classes, refer to the following
URL: https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
Question 5
You have a cluster of Windows instances joined to an AWS Managed Active Directory. You want to have
a shared storage for all these instances and control this storage access with the Managed Active
Directory. Which of the following services allows you to achieve this?
A.
Amazon FSx for Lustre
B.
Amazon FSx for Windows File Server
C.
Amazon EFS
D.
Use S3 and AD Connector
Correct Answer: B
- Option A is incorrect. Amazon FSx for Lustre is mainly used to do high-performance compute, read
and
write data into S3, and only works with Linux instances. more details: https://aws.amazon.com/fsx/lustre/faqs/
- Option B is CORRECT. Amazon FSx works with Microsoft Active Directory (AD) to integrate with your
existing Windows environments. Users can use their existing AD-based user identities to
authenticate
themselves and access the Amazon FSx file system. More details: https://aws.amazon.com/fsx/windows/faqs/
- Option C is incorrect. EFS is an NFS storage system to work with Linux instances. More
details: https://aws.amazon.com/efs/
- Option D is incorrect. AD Connector is a directory gateway with which you can redirect directory
requests to your on-premises Microsoft Active Directory without caching any information in the
cloud. Using S3 and AD Connector will not help in the given requirement. https://docs.aws.amazon.com/directoryservice/latest/admin-guide/directory_ad_connector.html
Question 6
You are part of the IT team of an insurance company. You have 4 M5.large EC2 instances used to
compute some data of your core services. The amount of usage of these instances has been very
consistent. So you predict that it will not increase in the next two or three years. However, your
CFO is asking if there is a way to reduce costs in the EC2 instances. What do you suggest to get the
maximum cost reduction?
A.
Use a Compute Savings Plan.
B.
Use an EC2 instance Savings Plan.
C.
Use a Convertible Reserved Instance.
D.
Use a Dedicated Instance.
Answer: B
- Option A is incorrect because Compute Saving plans also offer flexibility, but the maximum cost
reduction is 66%.
- Option B is CORRECT because, with an EC2 saving plan, you can save up to 72% (just like Standard
RIs). This plan applies to all of your EC2 instances using the same instance family.
- Option C is incorrect because Convertible Reserved Instances provide a significant discount of up
to
66% compared to On-Demand Instances and can be purchased for a 1-year or 3-year term.
- Option D is incorrect because Dedicated Instances are Amazon EC2 instances that run in a virtual
private cloud (VPC) on hardware that's dedicated to a single customer. They cannot reduce the
costs.
Question 7
You are building an automated transcription service where Amazon EC2 worker instances process an
uploaded audio file and generate a text file. You must store both of these files in the same durable
storage until the text file is retrieved. Customers fetch the text files frequently. You do not know
about the storage capacity requirements. Which storage option would be both cost-efficient and
highly available in this situation?
A.
Multiple Amazon EBS Volume with snapshots
B.
A single Amazon Glacier Vault
C.
A single Amazon S3 bucket
D.
Multiple instance stores
Correct Answer – C
Amazon S3 is the perfect storage solution for audio and text files. It is a highly available and
durable storage device.
- Option A is incorrect because storing files in EBS is not cost-efficient.
- Option B is incorrect because files need to be retrieved frequently so Glacier is not
suitable.
- Option D is incorrect because instance store is not highly available compared with S3.
Question 8
A customer has an instance hosted in the public subnet of the default VPC. The subnet has the
default settings for the Network Access Control List. An IT Administrator needs to be provided SSH
access to the underlying instance. How could this be accomplished?
A.
Ensure the Network Access Control Lists allow Inbound SSH traffic from the IT Administrator’s
Workstation.
B.
Ensure the Network Access Control Lists allow Outbound SSH traffic from the IT Administrator’s
Workstation.
C.
Ensure that the Security group allows Inbound SSH traffic from the IT Administrator’s Workstation.
D.
Ensure that the Security group allows Outbound SSH traffic from the IT Administrator’s Workstation
Correct Answer - C
Since the IT administrator needs to be provided SSH access to the instance, the traffic would be
inbound to the instance.
Since Security groups are stateful, we do not have to configure outbound traffic. What enters the
inbound traffic is allowed in the outbound traffic too.
Options A and B are incorrect because the default network ACL is configured to allow all traffic to
flow in and out of the subnets to which it is associated.
- Option D is incorrect because Security groups are stateful, we do not have to configure outbound
traffic.
Question 9
Your Organization is planning to move its on-premise databases to the AWS Cloud. You have been
selected to migrate the main production database, and there are some requirements. The production
database should remain active during the migration. You need to monitor the progress of the
migration. The database is an SQL Server Database. You need to find an easy way to convert the
actual schemas to MySQL schemas. What services could help to achieve this? (Select two)
A.
AWS DataSync.
B.
AWS Application Discovery Service
C.
AWS Database Migration Service.
D.
AWS Migration Hub.
E.
AWS Application Migration Service
Correct Answers: C and D
- Option A is incorrect. DataSync is a service mainly used to migrate NFS servers to S3, EFS, Fsx,
etc. It does not support database migrations. More details
here: https://aws.amazon.com/datasync/faqs/
- Option B is incorrect because AWS Application Discovery Service helps plan cloud migration by
gathering information about the on-premises data centers.
- Option C is CORRECT. AWS Database Migration Service helps you to migrate your On-Premise database
to
AWS, keeping the On-Premise database fully operational during the migration. It also converts
PL/SQL
and SQL Server to MySQL or Postgres schemas with the help of the AWS Schema Conversion Tool
included
in this service. More
details: https://aws.amazon.com/dms/faqs/
- Option D is CORRECT. AWS Migration Hub is used to track the progress of migrations in AWS. More
details
here https://aws.amazon.com/migration-hub/
- Option E is incorrect because AWS Application Migration Service (MGN) is an automated
lift-and-shift
solution that simplifies, expedites, and reduces the cost of migrating to AWS.
Question 10
You are deploying an application to track the GPS coordinates of delivery trucks in the United
States. Coordinates are transmitted from each delivery truck once every three seconds. You need to
design an architecture that will enable real-time processing of these coordinates from multiple
consumers. Which of the following services would you use to implement data ingestion?
A.
Amazon Kinesis
B.
AWS Data Pipeline
C.
Amazon Elastic Transcoder
D.
Amazon Simple Queue Service
Correct Answer - A
With Amazon Kinesis, you can ingest real-time data such as video, audio, application logs, website
clickstreams, and IoT telemetry data for machine learning, analytics, and other applications. Amazon
Kinesis enables you to process and analyze data as it arrives and responds instantly instead of
waiting until all your data is collected before the processing can begin.
- Option B is incorrect because AWS Data Pipeline is a web service that you can use to automate the
movement and transformation of data. There is no such requirement mentioned in the
question.
- Option C is incorrect because Amazon Elastic Transcoder lets you convert media files that you have
stored in Amazon S3 into media files in the formats required by consumer playback devices. For
example, you can convert large, high-quality digital media files into formats that users can play
back on mobile devices, tablets, web browsers, and connected televisions.
It is not suitable for the given requirement.
- Option D is incorrect because Amazon SQS lets you easily move data between distributed application
components and helps to build applications in which messages are processed independently. There is
no SQS-related requirement mentioned in the question.
Question 11
With its own Active Directory, your company authenticates users for different applications. You have
been assigned the task of consolidating and migrating services to the cloud and using the same
credentials if possible. What would you recommend?
A.
Use AWS Directory Service that allows users to sign in with their existing corporate credentials.
B.
Create two Active Directories – one for the cloud and one for on-premises – reducing
username/password combinations to two.
C.
Require users to use third-party identity providers to log-in for all services.
D.
Build out Active Directory on EC2 instances to gain more control over user profiles.
Correct Answer: A
- Option A is correct. AWS Directory Service enables your end-users to use their existing corporate
credentials while accessing AWS applications. Once you’ve been able to consolidate services to
AWS,
you won’t have to create new credentials. Instead, you’ll be able to allow the users to use their
existing username/password.
- Option B is incorrect. One Active Directory can be used for both on-premises and the cloud. This
isn’t the best option provided.
- Option C is incorrect. This won’t always reduce the number of username/password
combinations.
- Option D is incorrect. This requires more effort and additional management than using a managed
service.
Question 12
A company is planning to use the AWS Redshift service. The Redshift service and data on it would be
used continuously for the next 3 years as per the current business plan. What would be the most
cost-effective solution in this scenario?
A.
Consider using On-demand instances for the Redshift Cluster.
B.
Enable Automated backup.
C.
Consider using Reserved Instances for the Redshift Cluster.
D.
Consider not using a cluster for the Redshift nodes.
Correct Answer - C
AWS documentation mentions the following:
If you intend to keep your Amazon Redshift cluster running continuously for a prolonged period, you
should consider purchasing reserved node offerings. These offerings provide significant savings over
on-demand pricing, but they require you to reserve compute nodes and commit to paying for those
nodes for either a one-year or three-year duration.
- Option A is incorrect because When you choose on-demand pricing, you can use the pause and resume
feature to suspend on-demand billing when a cluster is not in use. Based on the requirement, we
need
steady-state workloads for 3 years which can be accomplished by Reserved instances.
- Option B is incorrect because there is no requirement for backup in the question. We can use
automated backup when everything has been set up on the instances (extra requirement).
- Option D is incorrect because a cluster is required. An Amazon Redshift data warehouse is a
collection of computing resources called nodes, which are organized into a group called a
cluster.
Question 13
A company has recently started using AWS Cloud services and needs to transfer a large set of data
online from on-prem Windows servers to AWS Storage Services S3, EFS, and FSx. The data can be
transferred in opposite directions periodically and should be incremental based on schedules.
How would a Solution Architect design this solution?
A.
Use Snowball devices to transfer data to S3, EFS and FSx.
B.
Use AWS DataSync service to transfer data to AWS Services.
C.
AWS Database Migration Service to transfer data to AWS services.
D.
Use AWS S3 Transfer acceleration to transfer a large set of data.
Correct Answer: B
AWS DataSync is an online data transfer service that simplifies, automates, and accelerates moving
data between storage systems and services.
AWS DataSync doesn't support workflows where multiple active applications write to both locations at
the same time. DataSync can transfer files in opposite directions periodically.
If a task is interrupted, for instance, or the network connection goes down or the AWS DataSync
agent is restarted, the next run of the task will transfer missing files. Each time a task is
started it performs an incremental copy, transferring only the changes from the source to the
destination.
- Option A is incorrect because Snowball devices are used to transfer a large set of data
electronically, and do not meet the given requirements.
- Option C is incorrect because AWS Database Migration Service (AWS DMS) is a web service that helps
to migrate data from your database that is on-premises, on an Amazon RDS DB instance, or in a
database on an Amazon EC2 instance to a database on an AWS service.
- Option D is incorrect because S3 Transfer acceleration is used to accelerate data transfer to S3
and
doesn’t meet the given requirement.
Question 14
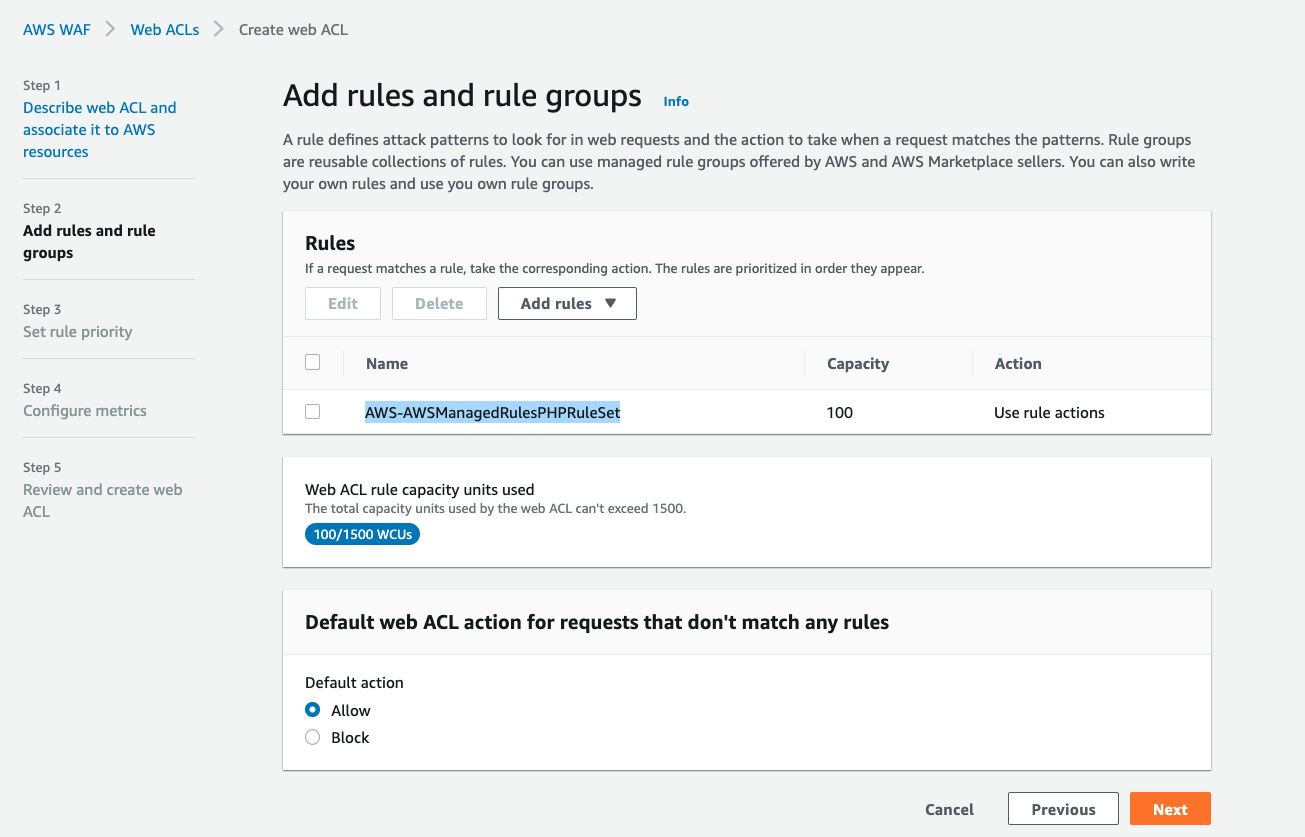
You have a PHP application deployed in an Auto Scaling group. In production, you want to use AWS WAF
to block requests associated with exploiting vulnerabilities specific to the PHP use, including
injection of unsafe PHP functions. Which method is appropriate?
A.
Add the AWS managed PHP application rule to AWS Shield.
B.
Add the AWS managed PHP application rule in the web ACL of AWS WAF.
C.
Add a PHP protection rule from AWS Marketplace to the WAF web ACL.
D.
Override the PHP rule’s actions under the ‘ExcludedRules’ specification inside a rule group of a web
ACL.
Correct Answer – B
- Option A is incorrect because AWS Shield is a service to protect web applications against DDoS
attacks. AWS WAF should be used in this scenario.
- Option B is CORRECT because AWS provides the PHP protection rule in WAF. Users can add the rule in
web ACL.
- Option C is incorrect because, in this scenario, you need to add the AWS managed PHP rule in web
ACL. There is no need to use a rule offered by AWS Marketplace.
- Option D is incorrect because there are no existing PHP-related actions inside the web ACL, so no
rule's action can be overridden. It is suitable to add AWS managed PHP application rule.
Question 15
A large amount of structured data is stored in Amazon S3 using the JSON format. You need to use a
service to analyze the S3 data directly with standard SQL. In the meantime, the data should be
easily visualized through data dashboards. Which of the following services is the most appropriate?
A.
Amazon Athena and Amazon QuickSight.
B.
AWS Glue and Amazon Athena.
C.
AWS Glue and Amazon QuickSight.
D.
Amazon Kinesis Data Stream and Amazon QuickSight.
Correct Answer – A
- Option A is CORRECT because Amazon Athena is the most suitable to run ad-hoc queries to analyze
data
in S3. Amazon Athena is serverless, and you are charged for the amount of scanned data. Besides,
Athena can integrate with Amazon QuickSight that visualizes the data via dashboards.
- Option B is incorrect because AWS Glue is an ETL (extract, transform, and load) service that
organizes, cleanses, validates, and formats data in a data warehouse. This service is not required
in this scenario.
- Option C is incorrect because it is the same as Option B. AWS Glue is not required.
- Option D is incorrect because, with Amazon Kinesis Data Stream, users cannot perform queries for
the
S3 data through standard SQL.
Question 16
An AWS Organization has the below hierarchy of Organizational Units (OUs):
Root -> Project_OU -> Dev_OU
The Root is attached to the default Service Control Policy (SCP).
Project_OU is attached to an SCP that prevents users from deleting VPC Flow Logs.
Dev_OU has an SCP that allows the action of “ec2: DeleteFlowLogs”.
Are the IAM users/roles in Dev_OU AWS accounts allowed to delete VPC Flow Logs?
A.
It is permitted because the SCP in Dev_OU allows it.
B.
It is allowed because the Root has the default SCP that allows all actions.
C.
It is not allowed as the SCP in Project_OU restricts the action.
D.
It is not allowed as the default SCP in Root denies the action.
Correct Answer – C
Check the AWS
documentation https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_about-scps.html
for how SCPs work in an AWS Organization:
- Option A is incorrect: Because if any parent OU has an SCP to deny the action, the final result is
Deny.
- Option B is incorrect: Although the default SCP allows the action, the parent OU (Project_OU)
denies
it.
- Option C is CORRECT: Because an explicit Deny statement in Project_OU overrides any Allow.
- Option D is incorrect: Because the default SCP is FullAWSAccess which allows all actions and all
services
Question 17
One AWS Organization owns several AWS accounts. Recently, due to a change of company organizations,
one member account needs to be moved from this AWS Organization to another one. How can you achieve
this?
A.
In the AWS console, drag and drop this account from one Organization to another.
B.
In the AWS console, select the member account and migrate it to the destination AWS Organization.
C.
Delete the old AWS Organization. Send an invite from the new Organization and accept the invite for
the member account.
D.
Remove the member account from the old Organization. Send an invite from the new Organization to the
member account and accept the invite.
Correct Answer – D
- Option A is incorrect: This operation cannot be performed.
- Option B is incorrect: Because a member account cannot be migrated to another AWS Organization
directly.
- Option C is incorrect: Because there is no need to delete the old Organization.
- Option D is CORRECT: The account needs to be removed from the old Organization and then accept the
invitation from the new Organization. The option describes the correct method.
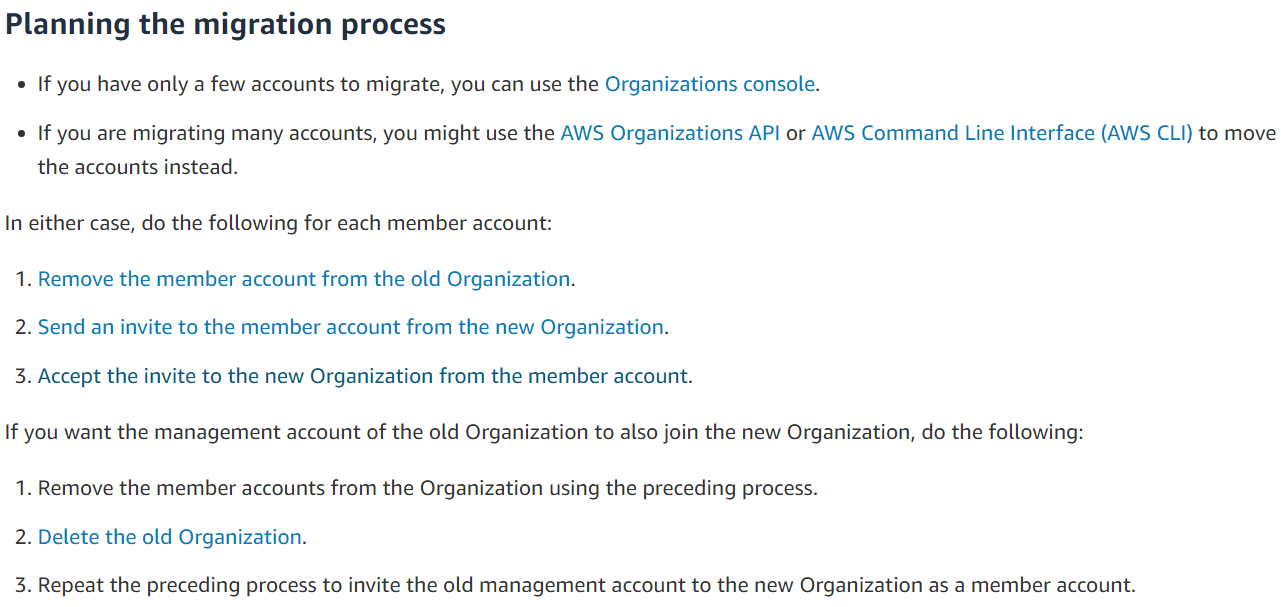
Planning the migration process:
If you have only a few accounts to migrate, you can use the Organizations console.
Remove the member account from the old Organization.
Send an invite to the member account from the new Organization.
Accept the invite to the new Organization from the member account.
Question 18
While managing permissions for the API Gateway, what could be used to ensure that the right level of
permissions is given to Developers, IT Admins, and end-users? The permissions should be easily
managed.
A.
Use the secure token service to manage the permissions for different users.
B.
Use IAM Permissions to create different policies for different types of users.
C.
Use the AWS Config tool to manage the permissions for different users.
D.
Use IAM Access Keys to create sets of keys for different types of users.
Correct Answer – B
AWS Documentation mentions the following:
You control access to Amazon API Gateway
with
IAM permissions by controlling access to the following two API Gateway component
processes.
To create, deploy, and manage an API in API Gateway, you must grant the API developer permissions to
perform the required actions supported by the API management component of API Gateway.
To call a deployed API or to refresh the API caching, you must grant the API caller permissions to
perform required IAM actions supported by the API execution component of API Gateway.
Question 19
You have an Amazon Route 53 alias record that routes the traffic to an Application Load Balancer.
Later on, the availability zones enabled for the load balancer are changed by a team member. When
you check the load balancer using the dig command, you find that the IPs of the ELB have changed.
What kind of change do you need to do for the alias record in Route 53?
A.
Change the record type from A to CNAME.
B.
Modify the destination to the DNS name of the Application Load Balancer.
C.
Add the new IP addresses in the destination of the alias record.
D.
Nothing, as Route 53 automatically recognizes changes in the resource for the alias record.
Correct Answer – D
- Option A is incorrect because there is no need to change the type to CNAME as the alias record
continues to work, although the IP addresses are changed for the ELB.
- Option B is incorrect because Route 53 can find out the new IPs of the ELB. This change is not
required.
- Option C is incorrect because you cannot add any extra IPs to this record after creating the alias
record. Route 53 is responsible for routing the traffic to the correct IP addresses.
- Option D is CORRECT because Route 53 automatically routes the traffic to the new ELB IP addresses.
With alias records, users do not need to change the record sets even if they have some
configuration
changes.
Question 20
There is an urgent requirement to monitor some database metrics for a database hosted on AWS and
send notifications. Which AWS services can accomplish this? (Select TWO)
A.
Amazon Simple Email Service
B.
Amazon CloudWatch
C.
Amazon Simple Queue Service
D.
Amazon Route 53
E.
Amazon Simple Notification Service
Correct Answer – B and E
Amazon CloudWatch will be used to monitor the IOPS metrics from the RDS Instance. Amazon Simple
Notification Service will be used to send the notification if an alarm is triggered.
SES:
It provides an email platform to send and receive emails using your own email addresses and
domains.
It can also be used in place of any third-party email services.
Using SNS with SES, you can segregate your emails based on categories like complaint-related emails,
positive feedback emails, and notifications regarding emails delivered or not. https://docs.aws.amazon.com/ses/latest/dg/tips-and-best-practices.html https://aws.amazon.com//blogs/messaging-and-targeting/
SQS:
SQS is a queuing service, also used to decouple application components. For example, suppose there
is a data management application that receives a high volume of data writes during month-end. They
want to use AWS RDS. So they can use SQS before RDS to process the messages one by one or slow the
messages before sending them to the next AWS services (Lambda or Kinesis family).
SQS will keep the data in the queue and then write the data into the RDS and the processing starts.
So, here the components are decoupled. Now not all the data coming together and reaching the next
services. https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/welcome.html
SNS:
Whenever there is a requirement of notification related to some failures or storage full and issues
like this, SNS can be used. CloudWatch and CloudTrail can handle the above failure and storage
metrics but that can only be visible in their console. So, Cloudwatch and CloudTrail can integrate
with SNS to enable notifications. https://docs.aws.amazon.com/sns/latest/dg/welcome-features.html
- Option D is incorrect because Amazon Route 53 is a highly available and scalable Domain Name
System (DNS) web service. It cannot be used to monitor metrics or send notifications.
Question 21
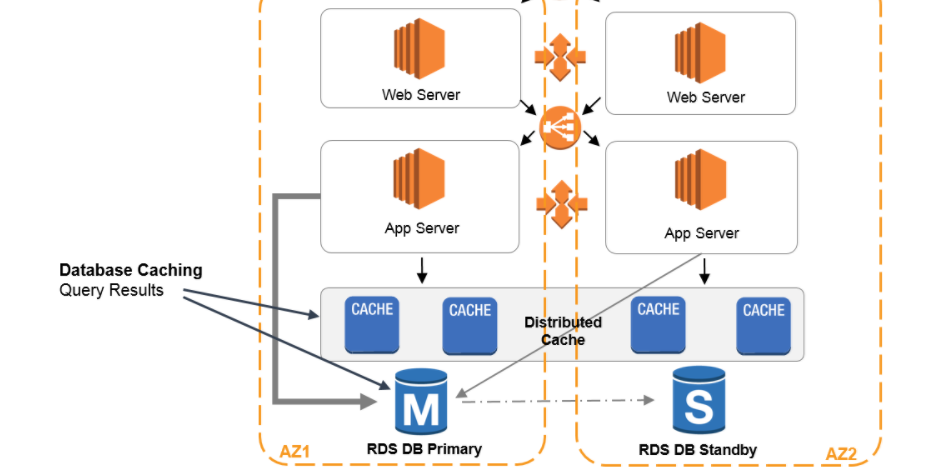
You have the following architecture deployed in AWS:
A set of EC2 instances behind an Elastic Load Balancer (ELB)
A database hosted in Amazon RDS.
Recently, the database performance has been declining due to a high volume of read requests. Which
of the following can be added to the architecture to improve the database’s performance? (Select
TWO)
A.
Add read replica to the primary database to offload read traffic.
B.
Use ElastiCache in front of the database.
C.
Use AWS CloudFront in front of the database.
D.
Use Amazon DynamoDB to offload all the reads. Populate the common read items in a separate table
Correct Answer - A and B
- Option A is correct because AWS says, "Amazon RDS Read Replicas provide enhanced performance and
durability for database (DB) instances. This feature makes it easy to elastically scale out beyond
the capacity constraints of a single DB instance for read-heavy database workloads. You can create
one or more replicas of a given source DB Instance and serve high-volume application read traffic
from multiple copies of your data, thereby increasing aggregate read throughput"
- Option B is correct because Amazon ElastiCache is an in-memory cache that can be used to cache
common read requests.
The below diagram shows how caching can be added to an existing architecture:
- Option C is incorrect because CloudFront is a valuable component of scaling a website, especially
for geo-location workloads and queries. This is more advanced for the given architecture.
- Option D is incorrect because offloading data into DynamoDB is a time-consuming task. There is no
requirement to offload the data into a tabular format. It is already provided to use Amazon
RDS.
Question 22
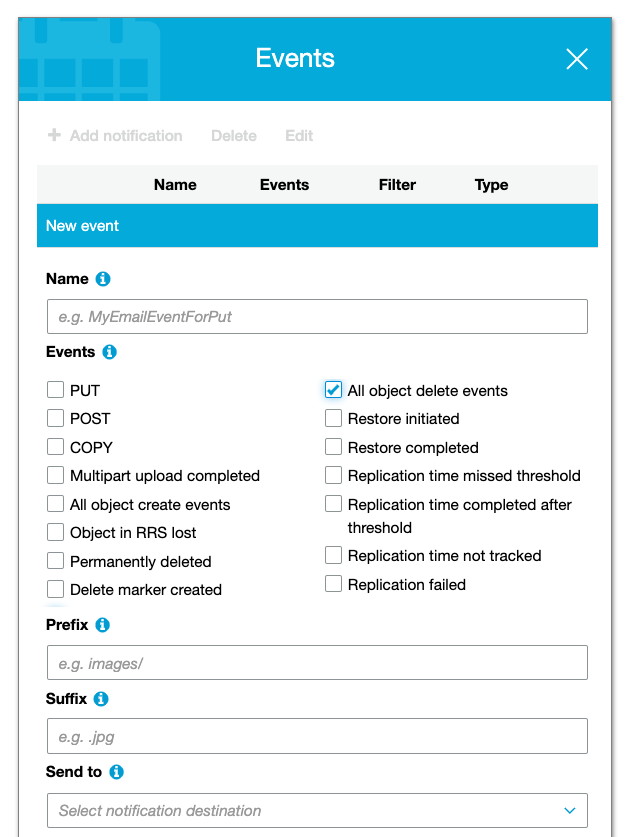
You have an S3 bucket that is used to store important data for a web application. You want to
receive an email notification whenever an object removal event happens in the S3 bucket. How would
you configure the S3 bucket to achieve this requirement?
A.
Configure the object-level logging for the S3 bucket and register an SNS topic to provide
notifications.
B.
Configure the server access logging for the object removal events. Add an SNS topic to notify the
team via emails.
C.
Set up an AWS Config rule to check the object deletion events. Register a Lambda function to send
notifications.
D.
Configure an S3 event notification for the object removal events. Send the events to an SNS topic.
Correct Answer – D
- Option A is incorrect because object-level logging is used to record object-level API activities
in
CloudTrail. Users cannot register an SNS topic for object-level logging.
- Option B is incorrect because server access logging does not trigger an SNS topic for the object
removal events.
- Option C is incorrect because you would need to write a custom Lambda function in the AWS Config
rule to check the object removal events. This method is more complicated than option D.
- Option D is CORRECT because with an S3 event notification, you can select which events are enabled
for the notification.
The events can be sent to an SNS topic, an SQS queue, or a Lambda function.
Question 23
To manage a large number of AWS accounts in a better way, you create a new AWS Organization and
invite multiple accounts. You only enable the “Consolidated billing” out of the two feature sets (
All features and Consolidated billing) available in the AWS Organizations. Which of the following is
the primary benefit of using Consolidated billing feature?
A.
Apply SCPs to restrict the services that IAM users can access.
B.
Configure tag policies to maintain consistent tags for resources in the organization’s accounts.
C.
Configure a policy to prevent IAM users in the organization from disabling AWS CloudTrail.
D.
Combine the usage across all accounts to share the volume pricing discounts.
Correct Answer – D
Available feature sets in AWS Organizations:
All features – The default feature set that is available to AWS Organizations. It includes all the
functionality of consolidated billing, plus advanced features that give you more control over
accounts in your organization.
Consolidated billing – This feature set provides shared billing functionality but does not include
the more advanced features of AWS Organizations.
- Option A is incorrect: Because SCP is part of the advanced features which belong to “All
features”.
- Option B is incorrect: Because tag policies can be applied under the feature set of “All
features”.
- Option C is incorrect: This is implemented using SCP which is not supported in “Consolidated
billing”.
- Option D is CORRECT: 'Consolidated billing' feature set provides shared billing
functionality.
Question 24
A new VPC with CIDR range 10.10.0.0/16 has been set up with a public and a private subnet. Internet
Gateway and a custom route table have been created, and a route has been added with the '
Destination’ as ‘0.0.0.0/0’ and the ‘Target’ with Internet Gateway ( igw-id ). A new Linux EC2
instance has been launched on the public subnet with the auto-assign public IP option enabled, but
the connection is getting failed when trying to SSH into the machine. What could be the reason?
A.
Elastic IP is not assigned.
B.
The NACL of the public subnet disallows the SSH traffic.
C.
A public IP address is not assigned.
D.
The Security group of the instance disallows the egress traffic on port 80.
Answer: B
- Option A is incorrect. An Elastic IP address is a public IPv4 address with which you can mask the
failure of an instance or software by rapidly remapping the address to another instance in your
account.
If your instance does not have a public IPv4 address, you can associate an Elastic IP address with
your instance to enable communication with the internet; for example, to connect to your instance
from your local computer.
From our problem statement, EC2 is launched with Auto-assign public IP enabled. So, since public IP
is available, Elastic IP is not necessary to connect from the internet.
- Option C is incorrect because the problem statement clearly states that EC2 is launched with
Auto-assign Public IP enabled, so this option cannot be true.
- Option B is CORRECT as the NCL may not allow the ingress SSH traffic so the connection failed to
connect.
- Option D is incorrect because SSH uses port 22. A security group is stateful and in this scenario,
the security group may disallow the ingress SSH traffic instead of egress.
Question 25
You are working as an AWS Architect for an IT Company. Your Company is using EC2 instances in
multiple VPCs spanning Availability Zones in us-east-1 Region. The Development Team has deployed a
new Intranet application that needs to be accessed via VPC.
You need to make sure that the connectivity to this particular application uses the internal AWS
network between different VPCs, and that the solution is highly scalable and secure. Which of the
following solution would you recommend?
A.
Attach an Internet Gateway to all the VPCs in the us-east-1 region and allow all users to access
this application over the internet.
B.
Deploy Network Load Balancers along with VPC endpoint service (AWS PrivateLink) to establish
connectivity between the VPCs in the us-east-1 region.
C.
Use the VPC Gateway Endpoint service between all the VPCs in the us-east-1 region to provide
connectivity between users & servers.
D.
Create a VPN between instances at the various VPCs in the us-east-1 region to establish
connectivity.
Correct Answer – B
Network Load Balancers and AWS PrivateLink work together to keep traffic within the AWS network,
ensuring it doesn't traverse the public internet. This is ideal for an internal application as it
enhances security.
Network Load Balancers can handle high traffic volumes efficiently, making the solution scalable for
future growth.
AWS PrivateLink creates a private connection between your VPC and the service endpoint, eliminating
exposure to the public internet. This strengthens the overall security posture.
- Option A is incorrect. Using the Internet to establish connectivity between users & servers will
not
be a highly secure solution.
- Option C is incorrect. VPC Gateway Endpoint service is for S3 and DynamoDB, which is unsuitable
for
this scenario.
- Option D is incorrect as VPN connectivity between the instance of various VPCs will not be a
scalable solution.
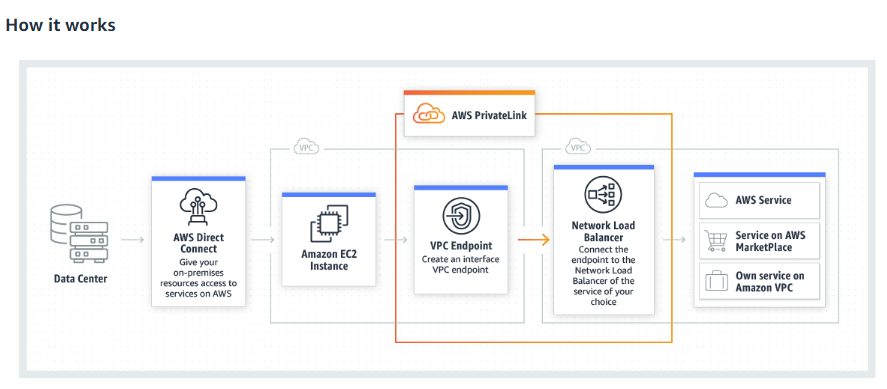
Accessing Services Through AWS Private Links:
AWS PrivateLink is a highly available, scalable technology that enables you to connect your VPC to
supported AWS services privately, services hosted by other AWS accounts (VPC endpoint services), and
supported AWS Marketplace partner services.
You do not require an internet gateway, NAT devices, public IP address, AWS Direct Connect
connection, or AWS Site-to-Site VPN connection to communicate with the service. The traffic between
your VPC and the service does not leave the Amazon network.
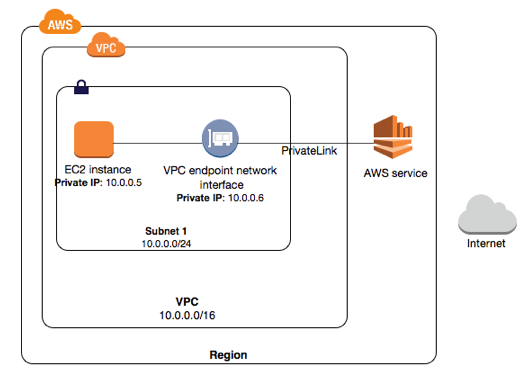
To use AWS PrivateLink, create an interface VPC endpoint for a service in your VPC. This creates an
elastic network interface in your subnet with a private IP address that serves as an entry point for
the traffic, destined for the service. For more information, see VPC Endpoints.
Question 26
You work in a large organization. Your team creates AWS resources such as Amazon EC2 dedicated hosts
and reserved capacities that need to be shared by other AWS accounts. You need an AWS service to
centrally manage these resources so that you can easily specify which accounts or Organizations can
access the resources. Which AWS service would you choose to meet this requirement?
A.
IAM
B.
Resource Access Manager
C.
Service Catalog
D.
AWS Single Sign-On
Correct Answer – B
AWS Resource Access Manager (AWS RAM) helps users to share resources with other AWS accounts or
Organizations. Refer to the reference
in https://docs.aws.amazon.com/ram/latest/userguide/what-is.html.
- Option A is incorrect: Because IAM cannot be used to manage and share these resources.
- Option B is CORRECT: EC2 dedicated hosts and reserved capacities are shareable resources that are
supported by Resource Access Manager. Check the reference
in https://docs.aws.amazon.com/ram/latest/userguide/shareable.html.
- Option C is incorrect: Because Service Catalog is used to manage catalogs and cannot share
resources
with others.
- Option D is incorrect: Because AWS Single Sign-On is used for SSO access and does not share the
mentioned resources.
Question 27
You are tasked with managing licenses for a variety of software applications deployed on AWS. Your
team is considering using AWS License Manager to track and control software usage across the
organization. Which of the following statements accurately describes a feature or capability of AWS
License Manager?
A.
AWS License Manager allows you to track the utilization of both AWS-provided and custom software
licenses, providing visibility into license usage and ensuring compliance
B.
AWS License Manager only supports tracking licenses for AWS-provided software products such as
Amazon RDS, Amazon Redshift, and Amazon EC2 instances
C.
AWS License Manager is primarily designed for managing licenses of third-party software applications
hosted on AWS, offering integration with leading software vendors
D.
AWS License Manager automatically purchases and allocates additional licenses when usage exceeds the
predefined thresholds, ensuring uninterrupted service availability
Correct Answer: A
AWS License Manager indeed enables organizations to track both AWS-provided licenses and custom
licenses procured independently. It provides visibility into license usage, helps in controlling
usage to ensure compliance with licensing terms, and offers features like License Manager rules to
set up licensing rules.
- Option B is incorrect because AWS License Manager supports tracking licenses for both AWS-provided
and third-party software, not just AWS-provided software. While it does support tracking
AWS-provided services like Amazon RDS and Amazon EC2 instances, it's not limited to them.
- Option C is incorrect because AWS License Manager does offer integration with leading software
vendors for managing third-party software licenses, it's not primarily designed for third-party
software. It equally supports AWS-provided licenses and custom licenses.
- Option D is incorrect because AWS License Manager does not automatically purchase or allocate
additional licenses when usage exceeds predefined thresholds. It provides visibility into license
usage and helps enforce compliance
Question 28
A company has a PostgreSQL DB instance in Amazon RDS which is not encrypted. As per security policy,
data in the RDS instances should be encrypted at rest with AWS KMS.
Which option is correct for RDS DB encryption?
A.
Amazon RDS for PostgreSQL DB instance can only be encrypted at creation time and not after its
creation. There is no way to achieve this requirement.
B.
Take a snapshot of the unencrypted DB instance. Copy the snapshot and encrypt the new snapshot with
AWS KMS. Restore the DB instance with the new encrypted snapshot.
C.
Take a snapshot of the unencrypted DB instance. Encryption can be enabled by restoring a DB instance
from the unencrypted snapshot.
D.
Stop the existing RDS instance and encrypt the DB with a KMS CMK.
Answer: B
- Option A is incorrect because there is a way to achieve encryption afterward which is given in
option B.
- Option B is CORRECT. You can enable encryption for an RDS DB instance when you create it, but not
after it's created. However, you can add encryption to an unencrypted DB instance by creating a
snapshot of your DB instance and then creating an encrypted copy of that snapshot. You can then
restore a DB instance from the encrypted snapshot to get an encrypted copy of your original DB
instance.
- Option C is incorrect because we have to copy and encrypt the snapshot first.
- Option D is incorrect because the currently running un-encrypted DB instance cannot be
encrypted.
Question 29
You currently manage a set of web servers hosted on EC2 instances with public IP addresses. These
IPv4 addresses are mapped to domain names. There was an urgent maintenance activity that need to be
carried out on the servers. The servers had to be stopped and restarted. After the maintenance, the
web application hosted on these EC2 Instances is not accessible via the domain names configured
earlier. Which of the following could be a reason for this?
A.
The Route 53 hosted zone needs to be restarted.
B.
The Elastic IP address needs to be initialized again.
C.
The public IP addresses need to be associated with the ENI (Elastic network interfaces) again.
D.
The public IP addresses have changed after the instance was stopped and started again
Correct Answer – D
- Option A is incorrect because if such issues arise we should check whether the DNS records are
configured correctly or not. There is no need to restart the hosted zone. We can update a few DNS
records that will be synced within 60 seconds.
- Option B is incorrect. If you stop and start your instance, the Elastic IP address is still
associated with the instance. To retain a public IPv4 address that never changes, you can
associate
an Elastic IP address with your instance. The issue has happened means there is no Elastic IP
attached.
- Option C is incorrect. If you stop and start your instance, the new public IP address gets
attached
to ENI, no need to manually associate it. Each instance has a default network interface, called
the
primary network interface eth0. You cannot detach a primary network interface from an instance.
You
can create and attach additional network interfaces. But the previous IP is changed due to stop
and
start, hence access issues will occur.
- Option D is correct. By default, the public IP address of an EC2 Instance is released after the
instance is stopped and started. Hence, the earlier IP address which was mapped to the domain
names
would have become invalid now.
Question 30
You are responsible for deploying a critical application to AWS. It is required to monitor web
application logs to identify any malicious activity. Also, there is a need to store log data in
highly durable storage. Which of the following services could be used to fulfill this requirement?
A.
Amazon CloudWatch Logs
B.
AWS Personal Health Dashboard
C.
Amazon Trusted Advisor
D.
Amazon CloudTrail
Correct Answers – A
AWS Documentation mentions the following about these services:
- Option A is correct as Amazon CloudWatch Logs is used to monitor, store, and access your log files
from Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS CloudTrail, Amazon Route 53, and
other
sources. You can then retrieve the associated log data from CloudWatch Logs. https://aws.amazon.com/compliance/services-in-scope/
- Option B is incorrect because AWS Personal Health Dashboard provides alerts and guidance for AWS
events that might affect your environment. It will not help to monitor the web application. https://aws.amazon.com/premiumsupport/technology/personal-health-dashboard/
- Option C is incorrect because AWS Trusted Advisor is an online tool that provides you with
real-time
guidance to help you provision your resources following AWS best practices. It is not required as
per the requirement. The question asks for monitoring services, not logging or some visualizing
service.
- Option D is incorrect as AWS CloudTrail is a service that enables governance, compliance,
operational auditing, and risk auditing of your AWS account. CloudTrail logs focus on the AWS
account or API logs which include actions taken through the AWS services, AWS Management Console,
AWS SDKs, and command line tools.
Whereas CloudWatch logs focus on application logs like logging the events for a particular
application. https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-working-with-log-files.html
Question 31
You need to deploy a high performance computing (HPC) and machine learning application in AWS Linux
EC2 instances. The performance of inter-instance communication is very critical for the application.
You want to attach a network device to the instance so that the computing performance can be greatly
improved. Which of the following options can achieve the best performance?
A.
Enable enhanced networking feature in the EC2 instance.
B.
Configure Elastic Fabric Adapter (EFA) in the instance.
C.
Attach high speed Elastic Network Interface (ENI) in the instance.
D.
Create Elastic File System (EFS) and mount the file system in the instance.
Correct Answer – B
An Elastic Fabric Adapter (EFA) is a network device that you can attach to your Amazon EC2 instance
to accelerate High-Performance Computing (HPC) and machine learning applications.
- Option A is incorrect, Enhanced networking provides higher bandwidth, higher packet-per-second (
PPS)
performance, and consistently lower inter-instance latencies. It uses the Elastic Network
Adapter (
ENA) or Intel 82599 Virtual Function (VF) interface, which can significantly improve network
performance. However, while it enhances network performance, it doesn’t match the low-latency,
high-throughput capabilities of Elastic Fabric Adapter (EFA).
- Option C is incorrect, An Elastic Network Interface (ENI) is a logical networking component that
can
be attached to an instance. While it allows for flexible network configurations and can be used to
manage network traffic, it doesn’t inherently provide the same level of performance enhancement as
EFA or even enhanced networking with ENA.
- Option D is incorrect: Amazon EFS provides scalable file storage for Amazon EC2, and cannot be
used
for improving the performance of HPC and machine learning applications.
Question 32
A company is planning on testing a large set of IoT-enabled devices. These devices will generate a
large amount of data every second. You need a scalable and durable real-time data streaming service
to capture the data generated from these devices. Which AWS service would be the most appropriate
for this purpose?
A.
AWS EMR.
B.
AWS Kinesis Data Streams.
C.
AWS SQS.
D.
AWS SNS.
Correct Answer - B
AWS Documentation mentions the following on Amazon Kinesis:
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can
get timely insights and react quickly to new information. Amazon Kinesis offers key capabilities to
cost-effectively process streaming data at any scale, along with the flexibility to choose the tools
that best suit the requirements of your application. With Amazon Kinesis, you can ingest real-time
data such as video, audio, application logs, website clickstreams, and IoT telemetry data for
machine learning, analytics, and other applications.
For more information on Amazon Kinesis, please refer to the below URL: https://aws.amazon.com/kinesis/
- Option A is incorrect. Amazon EMR can be used to process applications with data-intensive
workloads
but is not a data streaming service.
- Option B is correct. Amazon Kinesis can be used to store, process, and analyze real-time streaming
data.
- Option C is incorrect. SQS is a fully managed message queuing service. But it cannot be configured
as a real-time data streaming service.
- Option D is incorrect. SNS is a flexible, fully managed pub/sub messaging and mobile notifications
service instead of a data streaming service.
Question 33
Your company currently has a set of non-production EC2 Instances hosted in AWS. To save costs, you
want to stop the EC2 instance when the average CPU utilization percentage has been lower than 10
percent for 24 hours, signaling that it is idle and no longer in use. Which step could be helpful to
fulfill this requirement?
A.
Use CloudWatch Logs to store the state change of the instances.
B.
Create Amazon CloudWatch alarms that monitor the CPU utilization metric and stop the instances when
the alarms are triggered.
C.
Use SQS to monitor the metric and add the record to a DynamoDB table.
D.
Use AWS Lambda to monitor the metric and store the state in a DynamoDB table.
Correct Answer: B
Create Alarms That Stop, Terminate, Reboot, or Recover an Instance
Using Amazon CloudWatch alarm actions, you can create alarms that automatically stop, terminate,
reboot, or recover your instances. You can use the stop or terminate actions to save money when you
no longer need an instance. You can use the reboot and recover actions to automatically reboot those
instances or recover them onto new hardware if a system impairment occurs.
There are several scenarios in which you might want to stop or terminate your instance
automatically. For example, you might have instances dedicated to batch payroll processing jobs or
scientific computing tasks that run for a period of time and then complete their work. Rather than
letting those instances sit idle (and accrue charges), you can stop or terminate them, helping you
to save money. The main difference between using the stop and the terminate alarm actions is that
you can easily restart a stopped instance if you need to rerun it later, and you can keep the same
instance ID and root volume. However, you cannot restart a terminated instance. Instead, you must
launch a new instance.
You can add the stop, terminate, reboot, or recover actions to any alarm that is set on an Amazon
EC2 per-instance metric, including basic and detailed monitoring metrics provided by Amazon
CloudWatch (in the AWS/EC2 namespace), as well as any custom metrics that include the InstanceId
dimension, as long as its value refers to a valid running Amazon EC2 instance.
For more information on Amazon EC2, please
visit https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/UsingAlarmActions.html#AddingStopActions.
Breakdown
- Option A is incorrect because CloudWatch Logs is not suitable to monitor the CloudWatch
Metrics.
- Option B is correct. CloudWatch alarms are used to trigger notifications for any metric. Alarms
can
trigger auto-scaling, EC2 actions(stop, terminate, recover, or reboot) and SNS
notifications.
- Option C is incorrect because SQS cannot modify the EC2 state when a CloudWatch metric breaches a
threshold value.
- Option D is incorrect because AWS Lambda is not necessary in this scenario. CloudWatch Alarms can
directly monitor the metric and trigger actions when needed.
Question 34
You have instances hosted in a private subnet in a VPC. There is a need for instances to download
updates from the Internet. As an architect, what change would you suggest to the IT Operations team
that would also be the most efficient and secure?
A.
Create a new public subnet and move the instance to that subnet.
B.
Create a new EC2 Instance to download the updates separately and then push them to the required
instance.
C.
Use a NAT Gateway to allow the instances in the private subnet to download the updates.
D.
Create a VPC link to the Internet to allow the instances in the private subnet to download the
updates.
Correct Answer – C
The NAT Gateway is an ideal option to ensure that instances in the private subnet have the ability
to download updates from the Internet.
For more information on the NAT Gateway, please refer to the below URL: https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/vpc-nat-gateway.html
- Option A is incorrect because there may be a security reason for keeping these instances in the
private subnet such as for DB instances.
- Option B is incorrect. The instances in the private subnet may be running various applications and
DB instances. Hence, it is not advisable or practical for an EC2 Instance to download the updates
separately and then push them to the required instance.
- Option D is incorrect because a VPC link is not used to connect to the Internet.
Question 35
You have an S3 bucket that receives photos uploaded by customers. When an object is uploaded, an
event notification is sent to an SQS queue with the object details. You also have an ECS cluster
that gets messages from the queue to do the batch processing. Each of the batch processing job takes
the same amount of time to get executed. The queue size may change greatly depending on the number
of incoming messages and backend processing speed. Which metric would you use to scale up/down the
ECS cluster capacity?
A.
The number of messages in the SQS queue.
B.
Memory usage of the ECS cluster.
C.
Number of objects in the S3 bucket.
D.
Number of containers in the ECS cluster.
Correct Answer – A
In this scenario, the SQS queue is used to store the object details, which is a highly scalable and
reliable service. ECS is ideal for performing batch processing, and it should scale up or down based
on the number of messages in the queue.
If you use a target tracking scaling policy based on a custom Amazon SQS queue metric, dynamic
scaling can adjust to the demand curve of your application more effectively.
- Option A is CORRECT: Users can configure a CloudWatch alarm based on the number of messages in the
SQS queue and notify the ECS cluster to scale up or down using the alarm.
- Option B is incorrect: Because the memory usage may not be able to reflect the workload.
- Option C is incorrect: Because the number of objects in S3 cannot determine if the ECS cluster
should change its capacity.
- Option D is incorrect: Because the number of containers cannot be used as a metric to trigger an
auto-scaling event.
An Auto Scaling group to manage EC2 instances for the purposes of processing messages from an SQS
queue.
A custom metric to send to Amazon CloudWatch that measures the number of messages in the queue per
EC2 instance in the Auto Scaling group.
A target tracking policy that configures your Auto Scaling group to scale based on the custom metric
and a set target value. CloudWatch alarms invoke the scaling policy.
Question 36
You are a solutions architect working for a regional bank that is moving its data center to the AWS
cloud. You need to migrate your data center storage to a new S3 and EFS data store in AWS. Since
your data includes Personally Identifiable Information (PII), you have been asked to transfer data
from your data center to AWS without traveling over the public internet. Which option gives you the
most efficient solution that meets your requirements?
A.
Migrate your on-prem data to AWS using the DataSync agent using NAT Gateway.
B.
Create a private VPC endpoint, and configure the DataSync agent to communicate to the private
DataSync service endpoints via the VPC endpoint using Direct Connect.
C.
Migrate your on-prem data to AWS using the DataSync agent using Internet Gateway.
D.
Create a public VPC endpoint, and configure the DataSync agent to communicate to the DataSync
private service endpoints via your VPC endpoint via your VPN.
Correct Answer: B
AWS documentation mentions the following:
While configuring this setup, you’ll place a private VPC endpoint in your VPC that connects to the
DataSync service. This endpoint will be used for communication between your agent and the DataSync
service.
In addition, for each transfer task, four elastic network interfaces (ENIs) will automatically get
placed in your VPC. DataSync agent will send traffic through these ENIs in order to transfer data
from your on-premises shares into AWS.
"When you use DataSync with a private VPC endpoint, the DataSync agent can communicate directly with
AWS without the need to cross the public internet."
- Option A is incorrect. To ensure your data isn’t sent over the public internet, you need to use a
VPC endpoint to connect the DataSync agent to the DataSync service endpoints.
- Option B is correct. Using a private VPC endpoint and the private DataSync service endpoints keeps
your data from traveling over the public internet.
- Option C is incorrect. Using the Internet Gateway by definition sends your traffic over the public
internet, which is the solution as per the requirement.
- Option D is incorrect. Using a public VPC endpoint and the DataSync service endpoints to
communicate
over your VPN will have the traffic traveling over the internet.
Question 37
You have planned to host a web application on AWS. You create an EC2 Instance in a public subnet
that needs to connect to an EC2 Instance that will host an Oracle database. Which steps would ensure
a secure setup? (SELECT TWO)
A.
Place the EC2 Instance with the Oracle database in the same public subnet as the Webserver for
faster communication.
B.
Place the ec2 instance that will host the Oracle database in a private subnet.
C.
Create a database Security group which allows incoming traffic only from the Web server’s security
group.
D.
Ensure that the database security group allows incoming traffic from 0.0.0.0/0
Correct Answer – B and C
The best and most secure option is to place the database in a private subnet. The below diagram from
AWS Documentation shows this setup. Also, you ensure that access is not allowed from all sources but
only from the web servers.
- Option A is incorrect because DB instances are placed in Private subnets and allowed to
communicate
with web servers in the public subnet as per the best practice guidelines.
- Option D is incorrect because allowing all incoming traffic from the Internet to the DB instance
is
a security risk.
Question 38
You are designing a website for a company that streams anime videos. You serve this content through
CloudFront. The company has implemented a section for premium subscribers. This section contains
more videos than the free section. You want to ensure that only premium subscribers can access this
premium section. How can you achieve this easily?
A.
Using bucket policies.
B.
Requiring HTTPS for communication between users and CloudFront.
A company has set up an application in AWS that interacts with DynamoDB. It is required that when an
item is modified in a DynamoDB table, an immediate entry has to be made to the associating
application. How can this be accomplished? (SELECT TWO)
A.
Set up CloudWatch to monitor the DynamoDB table for changes. Then trigger a Lambda function to send
the changes to the application.
B.
Set up CloudWatch logs to monitor the DynamoDB table for changes. Then trigger AWS SQS to send the
changes to the application.
C.
Use DynamoDB streams to monitor the changes to the DynamoDB table.
D.
Trigger a lambda function to make an associated entry in the application as soon as the DynamoDB
streams are modified.
Correct Answer – C and D
When you enable DynamoDB Streams on a table, you can associate the stream ARN with a Lambda function
that you write. Immediately after an item in the table is modified, a new record appears in the
table's stream. AWS Lambda polls the stream and invokes your Lambda function synchronously when it
detects new stream records. Since we require an immediate entry made to an application in case an
item in the DynamoDB table is modified, a lambda function is also required.
Consider a mobile gaming app that writes to a GamesScores table. Whenever the top score of the Game
Scores table is updated, a corresponding stream record is written to the table's stream. This event
could trigger a Lambda function that posts a Congratulatory message on a Social media network
handle.
DynamoDB streams can be used to monitor the changes to a DynamoDB table.
A DynamoDB stream is an ordered flow of information about changes to items in an Amazon DynamoDB
table. When you enable a stream on a table, DynamoDB captures information about every modification
to data items in the table.
Note:
DynamoDB is integrated with Lambda so that you can create triggers for events in DynamoDB
Streams.
If you enable DynamoDB Streams on a table, you can associate the stream ARN with a Lambda function
that you write. Immediately after an item in the table is modified, a new record appears in the
table's stream.
AWS Lambda polls the stream and invokes your Lambda function synchronously when it detects new
stream records. Since our requirement states that an item modified in a DynamoDB table causes an
immediate entry to an associating application, a lambda function is also required.
Options A and B are incorrect because CloudWatch or CloudWatch logs cannot be used to monitor any
item changes in a DynamoDB table.
Question 40
You are working as an AWS consultant in an E-Commerce organization. Your organization is planning to
migrate its database from on-premises data centers to Amazon RDS. The automated backup helps to
restore the Database to any specific time during the backup retention period in Amazon RDS. Which of
the following actions are performed as a part of the Amazon RDS automated backup process?
A.
AWS creates a storage volume snapshot of the database instance during the backup window once a day.
AWS RDS also captures transactions logs and uploads them to S3 buckets every 5 minutes.
B.
AWS creates a full snapshot of the database every 12 hours during the backup window, captures
transactions logs throughout the day, and stores them in S3 buckets.
C.
AWS creates a full daily snapshot during the backup window. With the snapshot, the RDS instance can
be restored at any time.
D.
AWS creates a storage volume snapshot of the database instance every 12 hours during the backup
window, captures transactions logs throughout the day, and stores them in S3 buckets.
Correct Answer – A
During automated backup, Amazon RDS creates a storage volume snapshot of the entire Database
Instance. RDS uploads transaction logs for DB instances to Amazon S3 every 5 minutes. To restore a
DB instance at a specific point in time, a new DB instance is created using the DB snapshot.
You can also use AWS Backup to manage backups of Amazon RDS DB instances. If your DB instance is
associated with a backup plan in AWS Backup, that backup plan is used for point-in-time
recovery.
- Option B is incorrect as RDS automated backup does not take a full snapshot every 12 hours.
- Option C is incorrect as this option does not mention the transaction logs captured in the
automated
backup process. - Option A is more accurate.
- Option D is incorrect as AWS performs storage volume snapshots daily, not every 12 hours.
Question 41
Your organization already had a VPC(10.10.0.0/16) setup with one public(10.10.1.0/24) and two
private subnets – private subnet 1 (10.10.2.0/24) and private subnet 2 (10.10.3.0/24). The public
subnet has the main route table, and two private subnets have two different route tables
respectively. AWS sysops team reports a problem starting the EC2 instance in private subnet 1 cannot
communicate to the RDS MySQL database on private subnet 2. What are the possible reasons? (choose 2
options)
A.
One of the private subnet route table’s local route has been changed to restrict access only within
the subnet IP range.
B.
RDS security group inbound rule is incorrectly configured with 10.10.1.0/24 instead of 10.10.2.0/24.
C.
10.10.3.0/24 subnet’s NACL denies inbound on port 3306 from subnet 10.10.2.0/24
D.
RDS Security group outbound does not contain a rule for ALL traffic or port 3306 for 10.10.2.0/24 IP
range
Correct Answer: B, C
For Option A, for any route table, the local route cannot be edited or deleted.
AWS Docs says:
"Every route table contains a local route for communication within the VPC over IPv4. If your VPC
has more than one IPv4 CIDR block, your route tables contain a local route for each IPv4 CIDR block.
If you've associated an IPv6 CIDR block with your VPC, your route tables contain a local route for
the IPv6 CIDR block. You cannot modify or delete these routes." https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_Route_Tables.html#RouteTables
For Option B, possible because the security group is configured with a public subnet IP range
instead of a private subnet 1 IP range, and EC2 is in private subnet 1. So EC2 will not be able to
communicate with RDS in private subnet 2.
- Option C is correct. https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_ACLs.html#default-network-acl
- Option D is not correct because Security Groups are stateful. If you send a request from your
instance, the response traffic for that request is allowed to flow in regardless of inbound
security
group rules. Responses to allowed inbound traffic are allowed to flow out, regardless of outbound
rules. https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_SecurityGroups.html#VPCSecurityGroups
Question 42
As a Solutions Architect for a multinational organization with more than 150000 employees,
management has decided to implement a real-time analysis for their employees’ time spent in offices
worldwide. You are tasked to design an architecture that will receive the inputs from 10000+ sensors
with swipe machine sending in and out data across the globe, each sending 20KB data every 5 Seconds
in JSON format. The application will process and analyze the data and upload the results to
dashboards in real-time.
Other application requirements will include the ability to apply real-time analytics on the captured
data. Processing of captured data will be parallel and durable. The application must be scalable as
per the requirement as the load varies and new sensors are added or removed at various facilities.
The analytic processing results are stored in a persistent data storage for data mining.
What combination of AWS services would be used for the above scenario?
A.
Use EMR to copy the data coming from Swipe machines into DynamoDB and make it available for
analytics.
B.
Use Amazon Kinesis Data Streams to ingest the Swipe data coming from sensors, Use custom Kinesis
Data Streams Applications to analyze the data and then move analytics outcomes to RedShift using AWS
EMR.
C.
Use SQS to receive the data coming from sensors, Kinesis Firehose to analyze the data from SQS, then
save the results to a Multi-AZ RDS instance.
D.
Use Amazon Kinesis Data Streams to ingest the sensors’ data, Use custom Kinesis Streams applications
to analyze the data, and move analytics outcomes to RDS using AWS EMR.
Correct Answer - B
- Option A is incorrect. EMR is not for receiving real-time data from thousands of sources. EMR is
mainly used for Hadoop ecosystem-based data used for Big data analysis.
- Option B is correct as the Amazon Kinesis Data Streams are used to read the data from thousands of
sources like social media, survey-based data, etc. The Kinesis Data Streams can be used to analyze
the data and feed it using AWS EMR to the analytics-based database like RedShift which works on
OLAP.
- Option C is incorrect. SQS cannot be used to read real-time data from thousands of sources. The
Kinesis Firehose is used to ship the data to other AWS services, not for analysis. And finally,
RDS
is again an OLTP based database.
- Option D is incorrect as the AWS EMR can read large amounts of data. However, RDS is a
transactional
database that works based on the OLTP. Thus, it cannot store the analytical data.
Question 43
You have designed an application that uses AWS resources, such as S3, to operate and store users’
documents. You currently use Cognito identity pools and user pools. To increase usage and ease of
signing up, you decide that adding social identity federation is the best path forward.
How would you differentiate the Cognito identity pool and the federated identity providers (e.g.,
Google)?
A.
They are the same and just called different things.
B.
First, you sign-in via Cognito then through a federated site, like Google.
C.
Federated identity providers and identity pools are used to authenticate services.
D.
You can choose a federated identity provider to authenticate users and associate a Cognito identity
pool to authorize the users.
Correct Answer - D
- Option D is correct. Federated identity providers are used to authenticate users. Then the Cognito
identity pool provides the temporary token that authorizes users to access AWS resources.
- Option A is incorrect. Cognito identity pool and the federated identity providers are separate,
independent authentication methods.
- Option B is incorrect. Only one log-in event is needed, not two.
- Option C is incorrect. Identity providers authenticate users, not authenticate services.
Question 44
You currently have your EC2 instances running in multiple availability zones in an AWS region. You
need to create NAT gateways for your private instances to access internet. How would you set up the
NAT gateways so that they are highly available?
A.
Create two NAT Gateways and place them behind an ELB.
B.
Create a NAT Gateway in each Availability Zone.
C.
Create a NAT Gateway in another region.
D.
Use Auto Scaling groups to scale the NAT Gateways
Correct Answer - B
- Option A is incorrect because you cannot create such configurations.
- Option B is CORRECT because this is recommended by AWS. With this option, if a NAT gateway’s
Availability Zone is down, resources in other Availability Zones can still access internet.
- Option C is incorrect because the EC2 instances are in one AWS region so there is no need to
create
a NAT Gateway in another region.
- Option D is incorrect because you cannot create an Auto Scaling group for NAT Gateways.
Question 45
A network administrator is tasked with setting up a Client VPN endpoint in an AWS environment to
facilitate secure remote access for employees. As part of the setup process, the administrator has
installed both a server certificate and a client certificate on the VPN server and the user’s
device, respectively. However, upon attempting to create the Client VPN endpoint, the administrator
encounters an issue where the certificate cannot be imported successfully.
Which of the following options accurately addresses this issue?
A.
Configure the VPN endpoint to accept self-signed certificates, bypassing the need for certificates
issued by a trusted CA, and proceed with the import process
B.
Adjust the encryption settings of the server certificate and client certificate to match the
requirements specified by AWS for Client VPN endpoints, and then re-import them into the VPN
configuration
C.
Ensure that the server certificate and client certificate are issued by a trusted Certificate
Authority (CA), and re-import them into the AWS Certificate Manager (ACM) for use with the Client
VPN endpoint
D.
Disable the certificate validation process on the VPN server, allowing the import process to proceed
without verifying the authenticity of the certificates
Correct Answer: C
This option addresses the issue by ensuring that the server certificate and client certificate are
issued by a trusted CA, which is a requirement for certificates used with AWS Client VPN endpoints.
Re-importing them into ACM ensures proper validation and trust.
- Option A is incorrect because Configuring the VPN endpoint to accept self-signed certificates
bypasses security best practices and introduces potential security risks.
- Option B is incorrect because While adjusting encryption settings might be necessary for
compatibility, it does not directly address the issue of certificate import failure.
- Option D is incorrect because Disabling certificate validation compromises the security of the VPN
connection and does not address the underlying issue of certificate import failure
Question 46
Your organization is considering using Amazon Managed Grafana to visualize and monitor metrics from
various AWS services and applications. As a Solutions Architect, you’re evaluating its features and
capabilities. Which of the following statements accurately describes a feature or capability of
Amazon Managed Grafana?
A.
Amazon Managed Grafana is only compatible with AWS CloudWatch metrics and does not support
integration with other monitoring systems or data sources
B.
Amazon Managed Grafana allows you to install custom plugins and extensions to extend its
functionality, providing flexibility in visualization and monitoring options
C.
Amazon Managed Grafana offers built-in alerting capabilities, allowing you to set up alarms and
notifications based on predefined thresholds for metric values
D.
Amazon Managed Grafana is a fully-managed service provided by AWS that enables you to create,
explore, and share dashboards for visualizing metrics from AWS services and third-party applications
Correct Answer: D
Amazon Managed Grafana is indeed a fully-managed service, allowing users to create, explore, and
share dashboards for visualizing metrics from various sources, including AWS services and
third-party applications. It simplifies the deployment and management of Grafana while integrating
seamlessly with AWS services like CloudWatch, AWS X-Ray, and Amazon Timestream.
- Option A is incorrect because Amazon Managed Grafana supports integration with various data
sources,
including AWS CloudWatch metrics, Amazon Managed Service for Prometheus, and other data sources
through custom plugins. It is not limited to CloudWatch metrics alone.
- Option B is incorrect because Amazon Managed Grafana simplifies the management and deployment of
Grafana instances, it does not currently support the installation of custom plugins or
extensions.
- Option C is incorrect because Amazon Managed Grafana does not offer built-in alerting
capabilities.
Users need to use Amazon CloudWatch alarms for setting up alerts and notifications based on metric
thresholds.
Question 47
It is expected that only certain specified customers can upload images to the S3 bucket for a
certain period of time. What would you suggest as an architect to fulfill this requirement?
A.
Create a secondary S3 bucket. Then, use an AWS Lambda to sync the contents to the primary bucket.
B.
Use pre-signed URLs for uploading the images.
C.
Use ECS Containers to upload the images.
D.
Upload the images to SQS and then push them to the S3 bucket.
Correct Answer – B
The S3 bucket owner can create Pre-Signed URLs to upload the images to S3.
For more information on Pre-Signed URLs, please refer to the URL below. https://docs.aws.amazon.com/AmazonS3/latest/dev/PresignedUrlUploadObject.html
- Option A is incorrect. Amazon has provided us with an inbuilt function for this requirement. This
option is expensive and time-consuming. As a Solution Architect, you are supposed to pick the best
and cost-effective solution.
- Option C is incorrect. ECS is a highly scalable, fast container management service that makes it
easy to run, stop, and manage Docker containers on a cluster.
- Option D is incorrect. SQS is a message queue service used by distributed applications to exchange
messages through a polling model and not through a push mechanism.
Note:
This question is based on the scenario where we can use the pre-signed URL.
You need to understand about pre-signed URL - which contains the user login credentials particular
resources, such as S3 in this scenario. And user must have the permission enabled that other
applications can use the credential to upload the data (images) in S3 buckets.
AWS Definition:
"A pre-signed URL gives you access to the object identified in the URL, provided that the creator of
the pre-signed URL has permissions to access that object. That is, if you receive a pre-signed URL
to upload an object, you can upload the object only if the creator of the pre-signed URL has the
necessary permissions to upload that object.
All objects and buckets by default are private. The pre-signed URLs are useful if you want your
user/customer to upload a specific object to your bucket, but you don't require them to have AWS
security credentials or permissions. When you create a pre-signed URL, you must provide your
security credentials and then specify a bucket name, an object key, an HTTP method (PUT for
uploading objects), and an expiration date and time. The pre-signed URLs are valid only for the
specified duration."
Question 48
Your company manages an application that currently allows users to upload images to an S3 bucket.
These images are picked up by EC2 Instances for processing and then placed in another S3 bucket. You
need an area where the metadata for these images can be stored. What would be an ideal data store
for this?
A.
AWS Redshift
B.
AWS Glacier
C.
AWS DynamoDB
D.
AWS SQS
Correct Answer - C
- Option A is incorrect because this is normally used for petabyte based storage.
- Option B is incorrect because this is used for archive storage.
- Option C is correct. AWS DynamoDB is the best, light-weight and durable storage option for
metadata.
- Option D is incorrect because this is used for messaging purposes.
Question 49
An application team needs to quickly provision a development environment consisting of a web and
database layer. What would be the quickest and most ideal way to get this set up in place?
A.
Create Spot Instances and install the web and database components.
B.
Create Reserved Instances and install the web and database components.
C.
Use AWS Lambda to create the web components and AWS RDS for the database layer.
D.
Use Elastic Beanstalk to quickly provision the environment.
Correct Answer – D
AWS Documentation mentions the following:
With Elastic Beanstalk, you can quickly deploy and manage applications in the AWS Cloud without
worrying about the infrastructure that runs those applications. AWS Elastic Beanstalk reduces
management complexity without restricting choice or control. You simply upload your application, and
Elastic Beanstalk automatically handles the details of capacity provisioning, load balancing,
scaling, and application health monitoring.
For more information on AWS Elastic Beanstalk, please refer to the URL below. https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/Welcome.html
- Option A is incorrect. Amazon EC2 Spot instances are spare compute capacity in the AWS cloud
available to you at steep discounts compared to On-Demand prices.
- Option B is incorrect. A Reserved Instance is a reservation of resources and capacity for either
one
or three years for a particular Availability Zone within a region.
- Option C is incorrect. AWS Lambda is a compute service that makes it easy for you to build
applications that respond quickly to new information and not for provisioning a new
environment.
Currently, the Elastic Beanstalk environment supports the following configurations:
It supports RDS.
Database Configuration Setting
AWS Elastic Beanstalk provides connection information to your instances by setting environment
properties for the database hostname, username, password, table name, and port. When you add a
database to your environment, its lifecycle is tied to your environments.
Question 50
Third-party sign-in (Federation) has been implemented in your web application to allow users who
need access to AWS resources. Users have been successfully logging in using Google, Facebook, and
other third-party credentials. Suddenly, their access to some AWS resources has been restricted.
What is the most likely cause of the restricted use of AWS resources?
A.
IAM policies for resources were changed, thereby restricting access to AWS resources.
B.
Federation protocols are used to authorize services and need to be updated.
C.
IAM groups for accessing the AWS resources were changed, thereby restricting their access via
federated login.
D.
The identity providers no longer allow access to AWS services.
Correct Answer: A
Users of your app can sign in using a well-known external identity provider (IdP), such as Login
with Amazon, Facebook, Google, or any other OpenID Connect (OIDC)-compatible IdP. They can receive
an authentication token, and then exchange that token for temporary security credentials in AWS that
map to an IAM role with permissions to use the resources in your AWS account.
- Option A is correct. When IAM policies are changed, they can impact the user experience and
services
they can connect to.
- Option B is incorrect. Federation is used to authenticate users, not to authorize services.
- Option C is incorrect. "IAM groups for accessing the AWS resources" is NOT the correct usage, as
IAM
role(s) must be attached.
- Option D is incorrect. The identity providers don’t have the capability to authorize services;
they
authenticate users.
Question 51
A security audit discovers that one of your RDS MySQL instances is not encrypted. The instance has a
Read Replica in the same AWS region which is also not encrypted. You need to fix this issue as soon
as possible. What is the proper way to add encryption to the instance and its replica?
A.
Create a DB snapshot from the instance. Copy the DB snapshot with encryption enabled. Restore a new
DB instance from the new encrypted snapshot and configure a Read Replica in the new DB instance.
B.
Encrypt the DB instance. Launch a new Read Replica and the replica is encrypted automatically.
C.
Create a DB snapshot from the RDS instance and encrypt the newly-created snapshot. Launch a new
instance and its Read Replica from the snapshot.
D.
Promote the Read Replica to be a standalone instance and encrypt it. Add a new Read Replica to the
standalone instance.
Correct Answer – A
Existing unencrypted RDS instances and their snapshots cannot be encrypted. Users can only enable
encryption for an RDS DB instance when they create it. The limitations can be found in the AWS
documentation
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.Encryption.html
- Option A is CORRECT: Because you can encrypt a copy of an unencrypted DB snapshot. Then the new
RDS
instance launched from the snapshot and the Read Replica of the new DB instance are
encrypted.
- Option B is incorrect: Because you cannot encrypt an unencrypted RDS instance directly.
- Option C is incorrect: Because you cannot encrypt an unencrypted DB snapshot directly according to
the above reference. You should create a copy of an unencrypted DB snapshot and then encrypt the
new
snapshot.
- Option D is incorrect: Because an unencrypted DB Read Replica cannot be encrypted. The correct
method is to launch a new instance from an encrypted DB snapshot.
Question 52
A Media firm Firm_A uses AWS infrastructure and has a global presence for its sports programming &
broadcasting network. It uses AWS Organization to manage multiple AWS accounts.
Recently it was acquired by Firm_B which also uses AWS Infrastructure. Firm_B also has its own sets
of AWS accounts.
After the merger, AWS Accounts of both organizations need to merge to create & manage policies more
effectively.
As an AWS Consultant, which of the following steps would you suggest to the client to move the
management account of the Firm_A to the organization used by the merged entity? (Select THREE)
A.
Remove all member accounts from the organization in Firm_A.
B.
Configure another member account as the management account in the Firm_A organization.
C.
Delete the organization in Firm_A.
D.
Invite the Firm_A management account to join the new organization (Firm_B) as a member account.
E.
Invite the Firm_A management account to join the new organization (Firm_B) as a management account.
Correct Answer – A, C, and D
To move the management account from one organization to another organization, the following steps
need to be implemented:
· Remove all member accounts from the old organization.
· Delete the old organization.
· Invite the management account of the old organization to be a member account of the new
organization.
- Option B is incorrect as the management account of an AWS organization cannot be replaced by
another
member account.
- Option E is incorrect as a management account will be joining as a member account of the new
organization, not as a management account.
Question 53
Your company has designed an app and requires it to store data in DynamoDB. The company has
registered the app with identity providers for users to sign-in using third-parties like Google and
Facebook. What must be in place such that the app can obtain temporary credentials to access
DynamoDB?
A.
Multi-factor authentication must be used to access DynamoDB.
B.
AWS CloudTrail needs to be enabled to audit usage.
C.
An IAM role allowing the app to have access to DynamoDB.
D.
The user must additionally log into the AWS console to gain database access
Correct Answer: C
- Option C is correct. The user will have to assume a role that has the permissions to interact with
DynamoDB.
- Option A is incorrect. Multi-factor authentication is available but not required.
- Option B is incorrect. CloudTrail is recommended for auditing but is not required.
- Option D is incorrect. A second log-in event to the management console is not required.
Question 54
A company has an entire infrastructure hosted on AWS. It requires to create code templates used to
provide the same set of resources in another region in case of a disaster in the primary region.
Which AWS service can be helpful in this regard?
A.
AWS Beanstalk
B.
AWS CloudFormation
C.
AWS CodeBuild
D.
AWS CodeDeploy
Correct Answer – B
AWS Documentation provides the following information to support this requirement:
AWS CloudFormation provisions your resources in a safe and repeatable manner, allowing you to build
and rebuild your infrastructure and applications, without having to perform manual actions or write
custom scripts. CloudFormation takes care of determining the right operations to perform while
managing your stack and rolls back changes automatically if errors are detected.
For more information on AWS CloudFormation, please visit the following URL: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/Welcome.html
AWS Beanstalk is an orchestration service for deploying applications that orchestrate various AWS
Services, including EC2, S3, SNS, CloudWatch, AutoScaling, and ELB. https://aws.amazon.com/elasticbeanstalk/
AWS CodeBuild is a fully managed continuous integration(CI) service that compiles source code, run
tests, and produces software packages that are ready to deploy. Using it, you don't need to
provision, manage, and scale your own build servers. https://aws.amazon.com/codebuild/
AWS CodeDeploy is a service that automates application deployments to various computing services,
including EC2, Fargate, Lambda, and on-premises instances. It protects your application from
downtime during deployments through rolling updates and deployment health tracking. https://aws.amazon.com/codedeploy/
Question 55
Your recent security reviews revealed a large spike in logins attempted to your AWS account. With
respect to sensitive data stored in encryption enabled S3, the data has not been encrypted and is
susceptible to fraud if it was to be stolen. You’ve recommended AWS Key Management Service as a
solution. Which of the following is true regarding the operations of KMS?
A.
Only KMS generated keys can be used to encrypt or decrypt data.
B.
Data is encrypted at rest with KMS.
C.
KMS allows all users and roles to use the keys by default.
D.
Data is encrypted in transit with the KMS key.
Correct Answer: B
- Option B is correct. Data is encrypted at rest once uploaded to S3.
- Option A is incorrect. Data can be encrypted/decrypted using AWS keys or keys provided by your
company.
- Option C is incorrect. Users are granted permissions explicitly, not by default by KMS.
- Option D is incorrect. KMS is used for the encryption at rest instead of in transit.
Question 56
Your company has a set of EC2 Instances hosted in AWS. It is required to prepare for regional
disasters and come up with the necessary disaster recovery procedures. Which of the following steps
would help to mitigate the effects of disaster in the future on EC2 Instances?
A.
Place an ELB in front of the EC2 Instances.
B.
Use Auto Scaling to ensure that the minimum number of instances are always running.
C.
Use CloudFront in front of the EC2 Instances.
D.
Create AMIs from the EC2 Instances. Use them to recreate the EC2 Instances in another region.
Correct Answer – D
You can create an AMI from the EC2 Instances and then copy them to another region. In case of a
disaster, an EC2 Instance can be created from the AMI.
Options A and B are good for fault tolerance. But they cannot help completely in disaster recovery
for the EC2 Instances.
- Option C is incorrect because we cannot determine if CloudFront would be helpful in this scenario
or
not without knowing what is hosted on the EC2 Instance.
For disaster recovery, we have to make sure that we can launch instances in another region when
required.
Question 57
Your company currently has setup their data store on AWS DynamoDB. One of your main revenue
generating applications uses the tables in this service. Your application is now expanding to 2
different other locations and you want to ensure that the latency for data retrieval is the least
from the new regions. Which of the following can help accomplish this?
A.
Place a cloudfront distribution in front of the database
B.
Enable Multi-AZ for DynamoDB
C.
Place an ElastiCache in front of DynamoDB
D.
Enable global tables for DynamoDB
Correct Answer: D
Amazon DynamoDB global tables provide a fully managed solution for deploying a multi-Region,
multi-active database, without having to build and maintain your own replication solution.
Global tables provide automatic multi-active replication to AWS Regions worldwide. They enable you
to deliver low-latency data access to your users no matter where they are located.
- Option A is incorrect since CloudFront should ideally be used in front of web distributions.
DynamoDB already has a feature to provide low latency.
- Option B is incorrect since there is no such feature of Multi-AZ in DynamoDB.
- Option C is incorrect since ElastiCache would not be effective for multiple regions
Question 58
A start-up firm is using an AWS Organization for managing policies across its Development and
Production accounts. The development account needs an EC2 dedicated host. The Production account has
subscribed to an EC2 dedicated host for its application but is not currently using it. Sharing has
NOT been enabled with the AWS Organization in AWS RAM.
Which of the following can be done to share the Amazon EC2 dedicated host from the Production
account to the Development account?
A.
Remove both Development & Production Accounts from Organization & then share resources between them.
B.
Resources in the same organization are automatically shared without the need to accept the
invitation of sharing resources.
C.
Create a resource share in the production account and accept the invitation in the development
account.
D.
Remove the destination Development account from an Organization & then share resources with it.
Correct Answer – C
With AWS Resource Access Manager, you can share resources that you own with other individual AWS
accounts. If your account is managed by AWS Organizations, you can also share resources with the
other accounts in your organization. You can also use resources that were shared with you by other
AWS accounts.
If you don't enable sharing within AWS Organizations, you can't share resources with your
organization or with the organizational units (OU) in your organization. However, you can still
share resources with individual AWS accounts in your organization.
- Option A is incorrect as removing both accounts from AWS Organization for Resource sharing is not
a
valid option.
- Option B is incorrect because when sharing is not enabled in the Organization, resources are not
automatically shared.
- Option D is incorrect as removing a destination account from AWS Organization is not required for
resource sharing.
Question 59
A company has a lot of data hosted on their On-premises infrastructure. Running out of storage
space, the company wants a quick win solution using AWS. There should be low latency for the
frequently accessed data. Which of the following would allow the easy extension of their data
infrastructure to AWS?
A.
The company could start using Gateway Cached Volumes.
B.
The company could start using Gateway Stored Volumes.
C.
The company could start using the Amazon S3 Glacier Deep Archive storage class.
D.
The company could start using Amazon S3 Glacier
Correct Answer - A
Volume Gateways and Cached Volumes can be used to start storing data in S3.
AWS Documentation mentions the following:
You store your data in Amazon Simple Storage Service (Amazon S3) and retain a copy of frequently
accessed data subsets locally. Cached volumes offer substantial cost savings on primary storage and
minimize the need to scale your storage on-premises. You also retain low-latency access to your
frequently accessed data.
This is the difference between Cached and stored volumes:
Cached volumes – You store your data in S3 and retain a copy of frequently accessed data subsets
locally. Cached volumes offer substantial cost savings on primary storage and "minimize the need to
scale your storage on-premises. You also retain low-latency access to your frequently accessed
data."
Stored volumes – If you need low-latency access to your entire data set, first configure your
on-premises gateway to store all your data locally. Then asynchronously back up point-in-time
snapshots of this data to Amazon S3. "This configuration provides durable and inexpensive off-site
backups that you can recover to your local data center or Amazon EC2." For example, if you need
replacement capacity for disaster recovery, you can recover the backups to Amazon EC2.
As described in the answer: The company wants a quick win solution to store data with AWS, avoiding
scaling the on-premise setup rather than backing up the data.
In the question, they mentioned that "A company has a lot of data hosted on their On-premises
infrastructure." From On-premises to cloud infrastructure, you can use AWS storage gateways.
Options C and D are incorrect as they are talking about the S3 storage classes, but the requirement
is (How) to transfer or migrate your data from On-premises to Cloud infrastructure.
Question 60
A Large Medical Institute is using a legacy database for saving all its patient details. Due to
compatibility issues with the latest software, they plan to migrate this database to AWS cloud
infrastructure. This large size database will be using a NoSQL database Amazon DynamoDB in AWS. As
an AWS consultant, you need to ensure that all the current legacy database tables are migrated
without a glitch to Amazon DynamoDB. Which of the following is the most cost-effective way of
transferring legacy databases to Amazon DynamoDB?
A.
Use AWS DMS with AWS Schema Conversion Tool to save data to Amazon S3 bucket & then upload all data
to Amazon DynamoDB.
B.
Use AWS DMS with engine conversion tool to save data to Amazon S3 bucket & then upload all data to
Amazon DynamoDB.
C.
Use AWS DMS with engine conversion tool to save data to Amazon EC2 & then upload all data to Amazon
DynamoDB.
D.
Use AWS DMS with AWS Schema Conversion Tool to save data to Amazon EC2 instance & then upload all
data to Amazon DynamoDB.
Correct Answer – A
Legacy database refers to a database that has been in use for many years and is unsuitable for
modern apps and environments.
In this case, the Legacy Database will be converted to Amazon DynamoDB, which will be a heterogenous
conversion. Using AWS Schema Conversion Tool is best suited for such conversion along with AWS DMS
to transfer data from on-premise to AWS.
Using the Amazon S3 bucket will help to save any amount of data most cost-effectively before
uploading the data to Amazon DynamoDB.
- Option B is incorrect as the engine conversion tool is best suited for homogeneous database
migration. In this case, it's a heterogeneous database. So using AWS SCT along with AWS DMS is the
best option.
Options C and D are incorrect as using the Amazon S3 bucket is a more cost-effective option than
using the Amazon EC2 instance.
Question 61
A Financial firm is planning to build a highly resilient application with primary database servers
located at on-premises data centers while maintaining its DB snapshots in an S3 bucket. The IT Team
is looking for a cost-effective and secure way of transferring the large customer financial
databases from on-premises servers to the Amazon S3 bucket with no impact on the client usage of
these applications. Also, post this data transfer, the on-premises application will be fetching data
from the Amazon S3 bucket in case of a primary database failure.
So, your solution should ensure that the Amazon S3 data is fully synced with the on-premises
database. Which of the following can be used to meet this requirement?
A.
Use Amazon S3 Transfer Acceleration for transferring data between the on-premises & Amazon S3 bucket
while using AWS Data Sync for accessing these S3 bucket data from the on-premises application.
B.
Use AWS Data Sync for transferring data between the on-premises & Amazon S3 bucket while using AWS
Storage Gateway for accessing these S3 bucket data from the on-premises application.
C.
Use AWS Snowball Edge for transferring data between the on-premises & Amazon S3 bucket while using
AWS Storage Gateway for accessing these S3 bucket data from the on-premises application.
D.
Use AWS Transfer for transferring data between the on-premises & Amazon S3 bucket while using AWS
Data Sync for accessing these S3 bucket data from the on-premises application
Correct Answer – B
AWS DataSync can be used for huge amounts of data transfer between on-premises & AWS. AWS Data Sync
is a secure way of online data transfer. Once data is transferred to the AWS S3 bucket, AWS Storage
Gateway can have data synced between on-premises servers & AWS S3 buckets.
- Option A is incorrect as Amazon S3 Transfer Acceleration can be used for applications that have
already integrated with Amazon S3 API.
- Option C is incorrect as AWS Snowball Edge can be used for offline data transfer between
on-premises & AWS S3 bucket.
- Option D is incorrect as AWS Transfer is a better choice for transferring SFTP data between
on-premises & Amazon S3.
Question 62
A company has an application that delivers objects from S3 to global users. Of late, some users have
been complaining of slow response times. Which additional step would help to build a cost-effective
solution and ensure that the users get an optimal response to objects from S3?
A.
Use S3 Replication to replicate the objects to regions closest to the users.
B.
Ensure S3 Transfer Acceleration is enabled to ensure that all users get the desired response times.
C.
Place an ELB in front of S3 to distribute the load across S3.
D.
Place the S3 bucket behind a CloudFront distribution
Correct Answer - D
AWS Documentation mentions the following:
If your workload is mainly sending GET requests, in addition to the preceding guidelines, you should
consider using Amazon CloudFront for performance optimization.
Integrating Amazon CloudFront with Amazon S3, you can distribute content to your users with low
latency and a high data transfer rate. You will also send fewer direct requests to Amazon S3, which
will reduce your costs.
For example, suppose that you have a few very popular objects. Amazon CloudFront fetches those
objects from Amazon S3 and caches them. Amazon CloudFront can then serve future requests for the
objects from its cache, reducing the number of GET requests it sends to Amazon S3.
For more information on performance considerations in S3, please visit the following URL: https://docs.aws.amazon.com/AmazonS3/latest/dev/request-rate-perf-considerations.html
- Option A is incorrect. S3 Cross-Region Replication is not the correct answer for this business
scenario. You are asked how to provide easier & faster access to data in the S3 bucket, and this
option is used to replicate S3 bucket data across regions.
- Option B is incorrect. S3 TA is used for fast, easy, and secure file transfer over long distances
between your client and your Amazon S3 bucket. S3 Transfer Acceleration does leverage Amazon
CloudFront’s globally distributed AWS Edge Locations. But it would be too costly for this
situation.
- Option C is incorrect. ELB is used to distribute traffic on to EC2 Instances.
Question 63
You are a Solutions Architect in a startup company that is releasing the first iteration of its app.
Your company doesn’t have a directory service for its intended users but wants the users to sign in
and use the app. Which of the following solutions is the most cost-efficient?
A.
Create an IAM role for each end user and the user will assume the IAM role when he signs in the APP.
B.
Create an AWS user account for each customer.
C.
Invest heavily in Microsoft Active Directory as it’s the industry standard.
D.
Use Cognito Identity along with a User Pool to securely save users’ profile attributes.
Correct Answer: D
- Option A is incorrect. It is improper to assign an IAM role for each end-user. IAM role is not a
directory service.
- Option B is incorrect. AWS account cannot be configured as a directory service.
- Option C is incorrect. This isn’t the most efficient means to authenticate and save user
information.
- Option D is correct. Cognito is a managed service that can be used for this app and scale quickly
as
usage grows.
Question 64
A start-up firm has a corporate office in New York & a regional office in Washington & Chicago.
These offices are interconnected over Internet links. Recently they have migrated a few application
servers to EC2 instance launched in the AWS US-east-1 region. The Developer Team located at the
corporate office requires secure access to these servers for initial testing & performance checks
before go-live of the new application. Since the go-live date is approaching soon, the IT team is
looking for quick connectivity to be established. As an AWS consultant, which link option will you
suggest as a cost-effective & quick way to establish secure connectivity from on-premise to servers
launched in AWS?
A.
Use AWS Direct Connect to establish IPSEC connectivity from On-premise to VGW.
B.
Install a third party software VPN appliance from AWS Marketplace in the EC2 instance to create a
VPN connection to the on-premises network.
C.
Use Hardware VPN over AWS Direct Connect to establish IPSEC connectivity from On-premise to VGW.
D.
Use AWS Site-to-Site VPN to establish IPSEC VPN connectivity between VPC and the on-premises
network.
Correct Answer – D
Using AWS VPN is the fastest & cost-effective way of establishing IPSEC connectivity from on-premise
to AWS. IT teams can quickly set up a VPN connection with VGW in the US-east-1 region so that
internal users can seamlessly connect to resources hosted on AWS.
- Option A is incorrect as AWS Direct Connect does not provide IPSEC connectivity. It is not a quick
way to establish connectivity.
- Option B is incorrect as you need to look for a third party solution from AWS Marketplace. And it
may not be as cost-efficient as option D.
- Option C is incorrect as although this will provide a high performance secure IPSEC connectivity
from On-premise to AWS, it is not a quick way to establish connectivity. It may take weeks or
months
to configure the AWS Direct Connect connection. AWS Direct Connect is also not
cost-effective.
Question 65
Your organization has set up an S3 bucket to host a static website and configured it with the S3
website endpoint
). This is the appropriate choice for routing traffic to an S3 website endpoint when using a custom
domain.
- Option A is incorrect An A record maps a domain to an IPv4 address, but S3 website endpoints do
not
have static IP addresses. They are accessed through DNS names, making this option unsuitable for
routing traffic to an S3 website endpoint.
- Option B is incorrect While an A record with an alias can route traffic to AWS resources like S3
buckets, alias records cannot be used with S3 website endpoints. They are only applicable for S3
buckets configured as static website hosting without a custom domain.
- Option D is incorrect Route 53 does not support an alias for CNAME records. Alias records are only
available for A and AAAA record types, not for CNAME.