400+ Câu hỏi luyện thi chứng chỉ AWS Certified Solutions Architect Associate (SAA-C03) - Phần 3
aws
aws certification
cloud computing
solutions architect
saa c03
aws exam
practice test
Question 1
A global beverage company is using AWS cloud infrastructure for hosting its web application. For a
new beverage, the company plans to use a unique voice using Amazon Polly to help market this product
to a wide range of customers.
Which feature can be used with Amazon Polly for this purpose?
A.
Create custom Lexicons with Amazon Polly
B.
Use a custom SSML tag with Amazon Polly
C.
Build a Brand Voice using Amazon Polly
D.
Use a Newscaster Speaking Style with Amazon Polly
Correct Answer: C
Brand Voice is a customer engagement that allows the Amazon Polly team to create a customized NTTS (
Neural Text-to-Speech) voice. This voice can be used within the organization for various use cases
such as unique vocal identifiers for specific products.
- Option A is incorrect as Custom Lexicons with Amazon Polly can be used to modify pronunciations of
certain words in a text, such as company names, acronyms, foreign words, and neologisms.
- Option B is incorrect as custom SSML (Speech Synthesis Markup Language) tags with Amazon Polly
support speech synthesis to allow certain words in a text in different styles.
- Option D is incorrect as Newscaster Speaking Style with Amazon Polly allows the synthesis of the
speech to make it sound as if it’s spoken by a TV or radio newscaster.
Question 2
An airline company needs to analyze customer feedback about services provided. A large number of
files are created which have texts such as Ticket returns and Flight complaints based upon customer
feedback. This text should be categorized, and a label needs to be assigned for further analysis.
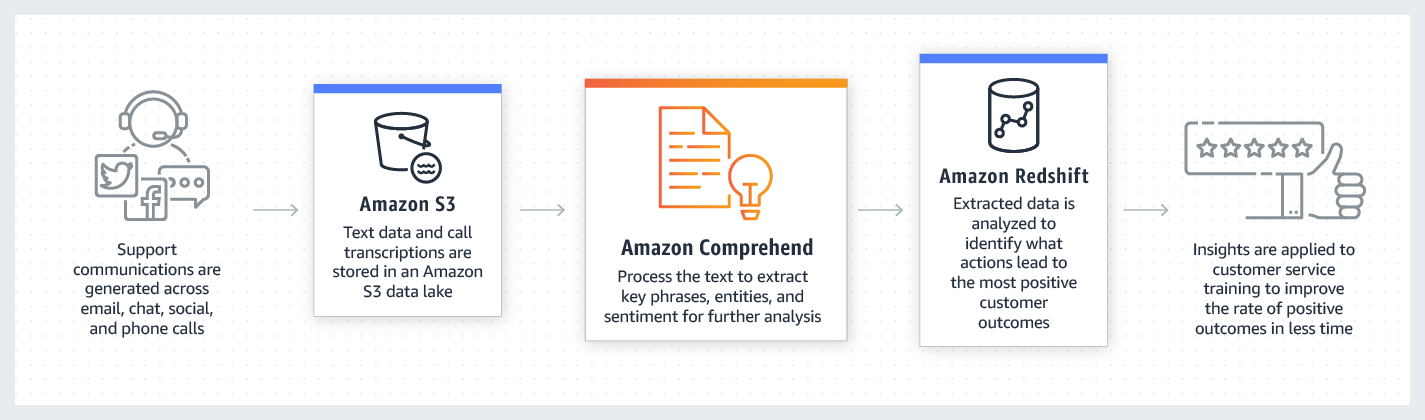
The company is planning to use Amazon Comprehend for this purpose. The project team is looking for
your suggestions for storing files that Amazon Comprehend can use for processing and saving the
results.
How can a solution be implemented for this purpose?
A.
Store the files in Amazon EFS volumes. Use Amazon Comprehend to read the data from the Amazon EFS
volumes and write results to Amazon Redshift
B.
Store the files in Amazon EBS volumes. Use Amazon Comprehend to read the data from the Amazon EBS
volumes and write results to Amazon S3 buckets
C.
Store the files in Amazon Redshift. Use Amazon Comprehend to read the data from the Amazon Redshift
and write results to Amazon S3 buckets
D.
Store the files in Amazon S3 bucket. Use Amazon Comprehend to read the data from the Amazon S3
bucket and write results to Amazon Redshift
Correct Answer: D
Amazon Comprehend is a fully managed NLP (natural language processing) service that uses machine
learning to analyze, understand and interpret meanings from a text document. Amazon Comprehend can
be commonly used for the following cases,
Voice of Customer Analytics
Semantic Search
Knowledge management and discovery
The Amazon Comprehend can read data from the Amazon S3 bucket and write results to any AWS storage,
database, or data warehousing resources.
For the above case, the company can store all the files in an Amazon S3 bucket. The Amazon
Comprehend will read the data from these files and process the text files to extract the keywords
such as Ticket returns and Flight complaints. It will store the output in Amazon Redshift which can
be used to perform further processing of the data based upon labels added by Amazon
Comprehend.
- Option A is incorrect as the Amazon Comprehend does not support reading data from Amazon EFS
volumes.
- Option B is incorrect as the Amazon Comprehend does not support reading data from Amazon EBS
volumes.
- Option C is incorrect as the Amazon Comprehend can read data from Amazon S3 and write data to
Amazon
Redshift, but not vice versa.
Question 3
A stock broking company has deployed a stock trading web application on the Amazon EC2 instance. The
company is looking for virtual agents to be integrated with this application to provide
conversational channels to its premium customers. Real-time personalized stock recommendations
should be provided for premium customers during market hours.
Which service is best suited to integrate with this application?
A.
Amazon Lex
B.
Amazon Translate
C.
Amazon Transcribe
D.
Amazon Personalize
Correct Answer: A
Amazon Lex is a fully managed AI (Artificial Intelligence) service for creating a conversational
interface for applications. With the prebuilt chatbots integrated with the application, customers
can interact with this virtual chat box for queries and personalized recommendations from the
capital market.
- Option B is incorrect as Amazon Translate can be used to translate the web application into a
language preferred by the users. This service cannot be for creating virtual chat agents with the
applications.
- Option C is incorrect as Amazon Transcribe can be used to enhance applications with automated
speech
recognition. This service cannot be used for creating virtual chat agents with the
applications.
- Option D is incorrect as Amazon Personalize can be used to customize applications for each of the
users using machine learning but cannot be used for creating virtual chat agents with the
applications.
Question 4
A Company has provisioned a website in the US West (N. California) region using Amazon EC2 instance
and Amazon CloudFront. The company is using IAM to control access to these resources. The client
plans to use a third-party SSL/TLS certificate to support HTTPS. As an AWS consultant, you have been
engaged to advise importing the certificate and using it along with Amazon CloudFront. Certificates
should be easily imported, and you should monitor the expiration dates of imported certificates.
How can certificates be provisioned to meet this requirement?
A.
Import the third-party certificate in the US East (N. Virginia) region of AWS Certificate Manager
and use it for Amazon CloudFront in the US West (N. California) region
B.
Import the third-party certificate in the US West (N. California) region of AWS Certificate Manager
and use it for Amazon CloudFront in the US West (N. California) region
C.
Import the third-party certificate in the US East (N. Virginia) region of IAM Certificate Manager
and use it for Amazon CloudFront in the US West (N. California) region
D.
Import the third-party certificate in the US West (N. California) region of IAM Certificate Manager
and use it for Amazon CloudFront in the US West (N. California) region
Correct Answer: A
Amazon Certificate Manager supports provisioning and managing SSL/TLS certificates to be used by
Amazon resources. It also supports importing the certificates from third-party vendors. For
certificates imported from third-party vendors, ACM (Amazon Certificate Manager) monitors expiration
dates for these certificates.
For Amazon Certificate Manager with Amazon CloudFront, certificates need to be imported in US East (
N. Virginia) and used for CloudFront in any of the supported regions.
- Option B is incorrect as for using ACM with Amazon CloudFront, third-party certificates must be
imported in the US East (N. Virginia) region and not in US West (N. California).
Options C and D are incorrect as IAM Certificate Manager is recommended to be used only as an
alternative to AWS Certificate Manager for regions in which AWS Certificate manager is not
supported.
Question 5
The Developer Team has deployed a new application using Amazon Aurora DB cluster. This cluster has a
primary instance and five Aurora Replicas. While testing this application, it was observed that the
primary instance is getting overutilized with the read requests. Before going to production, the
Project Manager wants you to analyze the issue and suggest changes.
Which design changes can a solution architect propose to the application?
A.
Point application to the custom endpoint of the Amazon Aurora
B.
Point application to cluster endpoint of the Amazon Aurora
C.
Point read queries to the reader endpoint of the Amazon Aurora
D.
Point application to instance endpoint of the Amazon Aurora
Correct Answer: C
Following are different endpoints supported with Amazon Aurora,
Cluster Endpoint: It connects to the primary DB instance of the DB cluster.
Reader Endpoint: It load balances between all the available Aurora Read Replicas in a DB
cluster.
Custom Endpoint: It connects to the user-defined DB instance of the DB cluster.
Instance Endpoint: It connects to a specific DB instance of the DB cluster.
In the above scenario, the primary instance of the Amazon Aurora DB cluster is getting overutilized
with the read requests. To avoid this issue, applications can point to read replicas for read
queries. When an application is pointed to the reader endpoint, read queries get load-balanced
amongst the available number of read replicas. This primary instance is used only for the write
operations reducing the load on this instance.
- Option A is incorrect as custom endpoints are used to specify particular instances in the DB
cluster. These are useful to handle queries from specific instances in a DB cluster. In the above
scenario, read queries need to be load balanced amongst the read replicas to reduce the load on
primary instances.
- Option B is incorrect as cluster endpoints point to the primary instance of the Aurora DB cluster.
This option doesn’t fulfill the given requirement.
- Option D is incorrect as instance endpoints are used to specify particular instances in the DB
cluster. These are useful to manually load balance queries to distribute the workload amongst the
instances in an Aurora DB cluster.
Question 6
A gaming company stores large size (terabytes to petabytes) of clickstream events data
into their central S3 bucket. The company wants to analyze this clickstream data to generate
business insight. Amazon Redshift, hosted securely in a private subnet of a VPC, is used for all
data warehouse-related and analytical solutions. Using Amazon Redshift, the company wants to explore
some solutions to securely run complex analytical queries on the clickstream data stored in S3
without transforming/copying or loading the data in the Redshift.
As a Solutions Architect, which of the following AWS services would you recommend for this
requirement, knowing that security and cost are two major priorities for the company?
A.
Create a VPC endpoint to establish a secure connection between Amazon Redshift and the S3 central
bucket and use Amazon Athena to run the query
B.
Use NAT Gateway to connect Amazon Redshift to the internet and access the S3 static website. Use
Amazon Redshift Spectrum to run the query
C.
Create a VPC endpoint to establish a secure connection between Amazon Redshift and the S3 central
bucket and use Amazon Redshift Spectrum to run the query
D.
Create Site-to-Site VPN to set up a secure connection between Amazon Redshift and the S3 central
bucket and use Amazon Redshift Spectrum to run the query
Correct Answer: C
- Option A is incorrect because Amazon Athena can directly query data in S3. Hence this will bypass
the use of Redshift, which is not the requirement for the customer. They insisted on Amazon
Redshift
for the query purpose for usage.
- Option B is incorrect. Even though it is possible, NAT Gateway will connect Redshift to the
internet
and make the solution less secure. Plus, this is also not a cost-effective solution. Remember that
security and cost both are important for the company.
- Option C is CORRECT because VPC Endpoint is a secure and cost-effective way to connect a VPC with
Amazon S3 privately, and the traffic does not pass through the internet. Using Amazon Redshift
Spectrum, one can run queries against the data stored in the S3 bucket without needing the data to
be copied to Amazon Redshift. This meets both the requirements of building a secure yet
cost-effective solution.
- Option D is incorrect because Site-to-Site VPN is used to connect an on-premises data center to
AWS
Cloud securely over the internet and is suitable for use cases like Migration, Hybrid Cloud,
etc.
Question 7
The drug research team in a Pharmaceutical company produces highly sensitive data and stores them in
Amazon S3. The team wants to ensure top-notch security for their data while it is stored in Amazon
S3. To have better control of the security, the team wants to use their own encryption key but
doesn’t want to maintain any code to perform data encryption and decryption. Also, the team wants to
be responsible for storing the Secret key.
As a Solutions Architect, which of the following encryption types will suit the above requirement?
A.
Server-side encryption with customer-provided encryption keys (SSE-C)
B.
Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
C.
Server-Side Encryption with KMS keys Stored in AWS Key Management Service (SSE-KMS)
D.
Protect the data using Client-Side Encryption
Correct Answer: A
Data protection refers to the protection of data while in transit (as it travels to and from Amazon
S3) and at rest (while it is stored on disks in Amazon S3 data centers).
While data in transit can be protected using Secure Socket Layer/Transport Layer Security (SSL/TLS)
or client-side encryption, one has the following options for protecting data at rest in Amazon
S3:
Server-Side Encryption – Request Amazon S3 to encrypt your object before saving it on disks in its
data centers and then decrypt it when you download the objects.
There are three types of Server-side encryption:
Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
Server-Side Encryption with KMS keys Stored in AWS Key Management Service (SSE-KMS)
Server-side encryption with customer-provided encryption keys (SSE-C)
Client-Side Encryption – Encrypt data client-side and upload the encrypted data to Amazon S3. In
this case, you manage the encryption process, the encryption keys, and related tools.
In this scenario, the customer is referring to data at rest.
- Option A is CORRECT because data security is the top priority for the team, and they want to use
their own encryption key. In this option, the customer provides the encryption key while S3
manages
encryption - decryption. So there won’t be any operational overhead, yet the customer will have
better control in managing the key.
- Option B is incorrect because each object is encrypted with a unique key when you use Server-Side
Encryption with Amazon S3-Managed Keys (SSE-S3). It also encrypts the key itself with a root key
that rotates regularly.
This encryption type uses one of the strongest block ciphers available, 256-bit Advanced
Encryption
Standard (AES-256) GCM, to encrypt your data, but it does not let customers create or manage the
key. Hence this is not a choice here.
- Option C is incorrect because Server-Side Encryption with AWS KMS keys (SSE-KMS) is similar to
SSE-S3 but with some additional benefits and charges for using this service.
There are separate permissions for the use of a KMS key that provides protection against
unauthorized access to your objects in Amazon S3.
This option is mainly neglected because AWS still manages the storage of the encryption key or
master key (in KMS) while encryption-decryption is managed by the customer. The expectation from the
team in the above scenario is just the opposite.
- Option D is incorrect because, in this case, one has to manage the encryption process, the
encryption keys, and related tools. And it is mentioned clearly above that the team does not want
that.
Question 8
An online retail company stores a large number of customer data (terabytes to petabytes) into Amazon
S3.The company wants to drive some business insight out of this data. They plan to securely run
SQL-based complex analytical queries on the S3 data directly and process it to generate business
insights and build a data visualization dashboard for the business and management review and
decision-making.
You are hired as a Solutions Architect to provide a cost-effective and quick solution to this. Which
of the following AWS services would you recommend?
A.
Use Amazon Redshift Spectrum to run SQL-based queries on the data stored in Amazon S3 and then
process it to Amazon Kinesis Data Analytics for creating a dashboard
B.
Use Amazon Redshift to run SQL-based queries on the data stored in Amazon S3 and then process it on
a custom web-based dashboard for data visualization
C.
Use Amazon EMR to run SQL-based queries on the data stored in Amazon S3 and then process it to
Amazon Quicksight for data visualization
D.
Use Amazon Athena to run SQL-based queries on the data stored in Amazon S3 and then process it to
Amazon Quicksight for dashboard view
Correct Answer: D
- Option A is incorrect because Amazon Kinesis Data Analytics cannot be used to generate business
insights as mentioned in the requirement. It neither can be used for data visualization.
One must depend on some BI tool after processing data from Amazon Kinesis Data Analytics. It is
not
a cost-optimized solution.
- Option B is incorrect primarily due to the cost factors. Using Amazon Redshift for querying S3
data
requires the transfer and loading of the data to Redshift instances. It also takes time and
additional cost to create a custom web-based dashboard or data visualization tool.
- Option C is incorrect because Amazon EMR is a cloud big data platform for running large-scale
distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications
using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto. It is mainly
used to perform big data analytics, process real-time data streams, accelerate data science and ML
adoption. The requirement here is not to build any of such solutions on a Big Data platform. Hence
this option is not suitable. It is neither quick nor cost-effective compared to option D.
- Option D is CORRECT because Amazon Athena is the most cost-effective solution to run SQL-based
analytical queries on S3 data and then publish it to Amazon QuickSight for dashboard view.
Question 9
An organization has archived all their data to Amazon S3 Glacier for a long term. However, the
organization needs to retrieve some portion of the archived data regularly. This retrieval process
is quite random and incurs a good amount of cost for the organization. As expense is the top
priority, the organization wants to set a data retrieval policy to avoid any data retrieval charges.
Which one of the following retrieval policies suits this in the best way?
A.
No Retrieval Limit
B.
Free Tier Only
C.
Max Retrieval Rate
D.
Standard Retrieval
Correct Answer: B
- Option A is incorrect because No Retrieval Limit, the default data retrieval policy, is used when
you do not want to set any retrieval quota. All valid data retrieval requests are accepted. This
retrieval policy incurs a high cost to your AWS account for each region.
- Option B is CORRECT because using a Free Tier Only policy, you can keep your retrievals within
your
daily AWS Free Tier allowance and not incur any data retrieval costs. And in this policy, S3
Glacier
synchronously rejects retrieval requests that exceed your AWS Free Tier allowance.
- Option C is incorrect because you use Max Retrieval Rate policy when you want to retrieve more
data
than what is in your AWS Free Tier allowance. Max Retrieval Rate policy sets a bytes-per-hour
retrieval-rate quota. The Max Retrieval Rate policy ensures that the peak retrieval rate from all
retrieval jobs across your account in an AWS Region does not exceed the bytes-per-hour quota that
you set. Max Retrieval rate policy is not in the free tier.
- Option D is incorrect because Standard Retrieval is a process of data retrieval from S3 Glacier
that
takes around 12 hours to retrieve data. This retrieval type is chargeable and incurs costs on the
AWS account per region wise.
Question 10
A gaming company planned to launch their new gaming application that will be in both web and mobile
platforms. The company considers using GraphQL API to securely query or update data through a single
endpoint from multiple databases, microservices, and several other API endpoints. They also want
some portions of the data to be updated and accessed in real-time.
The customer prefers to build this new application mostly on serverless components of AWS.
As a Solutions Architect, which of the following AWS services would you recommend the customer to
develop their GraphQL API?
A.
Kinesis Data Firehose
B.
Amazon Neptune
C.
Amazon API Gateway
D.
AWS AppSync
Correct Answer: D
- Option A is incorrect because Amazon Kinesis Data Firehose is a fully managed service for
delivering
real-time streaming data to destinations such as Amazon S3, Amazon Redshift, Amazon OpenSearch,
etc.
It cannot create GraphQL API.
- Option B is incorrect. Amazon Neptune is a fast, reliable, fully managed graph database service
that
makes it easy to build and run applications. It is a database and cannot be used to create GraphQL
API.
- Option C is incorrect because Amazon API Gateway supports RESTful APIs (HTTP and REST API) and
WebSocket APIs. It is not meant for the development of GraphQL API.
- Option D is CORRECT because with AWS AppSync one can create serverless GraphQL APIs that simplify
application development by providing a single endpoint to securely query or update data from
multiple data sources and leverage GraphQL to implement engaging real-time application
experiences.
Question 11
A weather forecasting company comes up with the requirement of building a high-performance, highly
parallel POSIX-compliant file system that stores data across multiple network file systems to serve
thousands of simultaneous clients, driving millions of IOPS (Input/Output Operations per Second)
with sub-millisecond latency. The company needs a cost-optimized file system storage for short-term,
processing-heavy workloads that can provide burst throughput to meet this requirement.
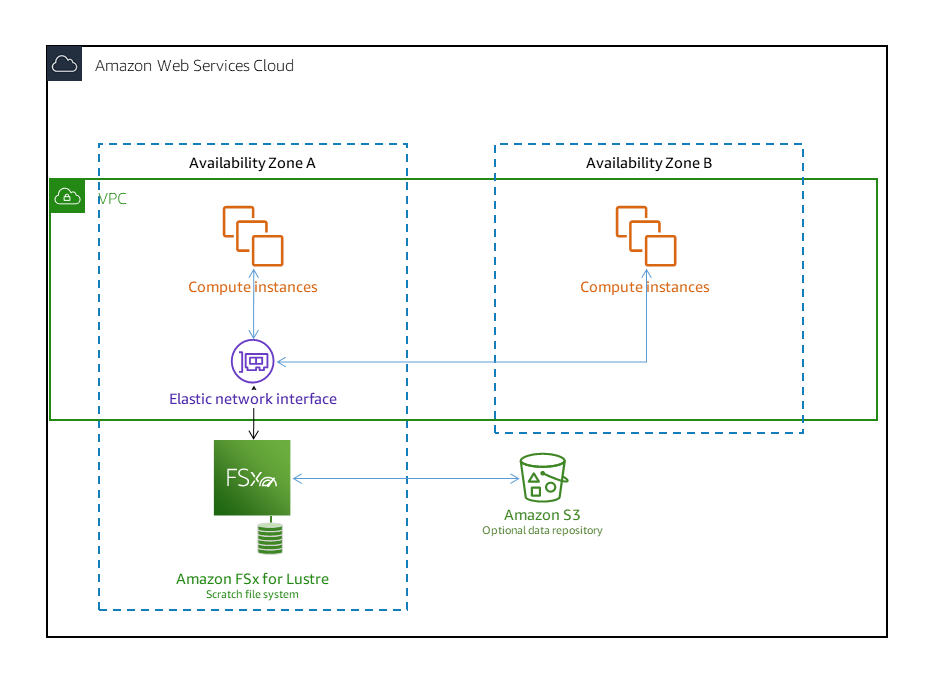
What type of file systems storage will suit the company in the best way?
A.
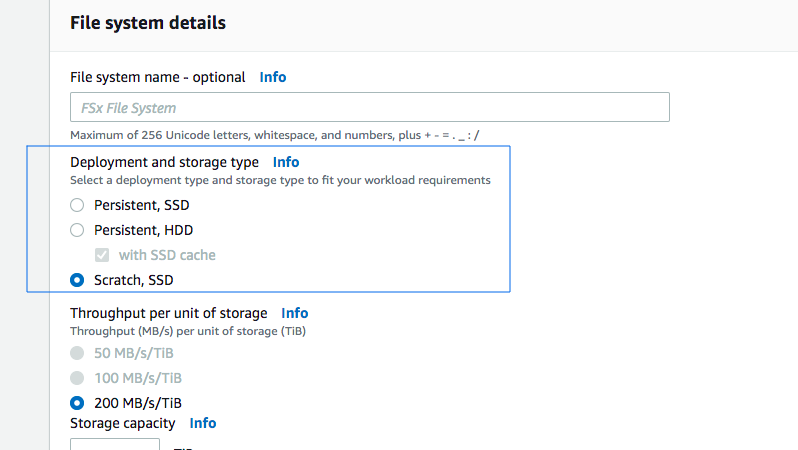
FSx for Lustre with Deployment Type as Scratch File System
B.
FSx for Lustre with Deployment Type as Persistent file systems
C.
Amazon Elastic File System (Amazon EFS)
D.
Amazon FSx for Windows File Server
Correct Answer: A
File system deployment options for FSx for Lustre:
Amazon FSx for Lustre provides two file system deployment options: scratch and persistent.
Both deployment options support solid-state drive (SSD) storage. However, hard disk drive (HDD)
storage is supported only in one of the persistent deployment types.
You choose the file system deployment type when you create a new file system using the AWS
Management Console, the AWS Command Line Interface (AWS CLI), or the Amazon FSx for Lustre
API.
- Option A is CORRECT because FSx for Lustre with Deployment Type as Scratch File System is designed
for temporary storage and shorter-term data processing. Data isn't replicated and doesn't persist
if
a file server fails. Scratch file systems provide high burst throughput of up to six times the
baseline throughput of 200 MBps per TiB storage capacity.
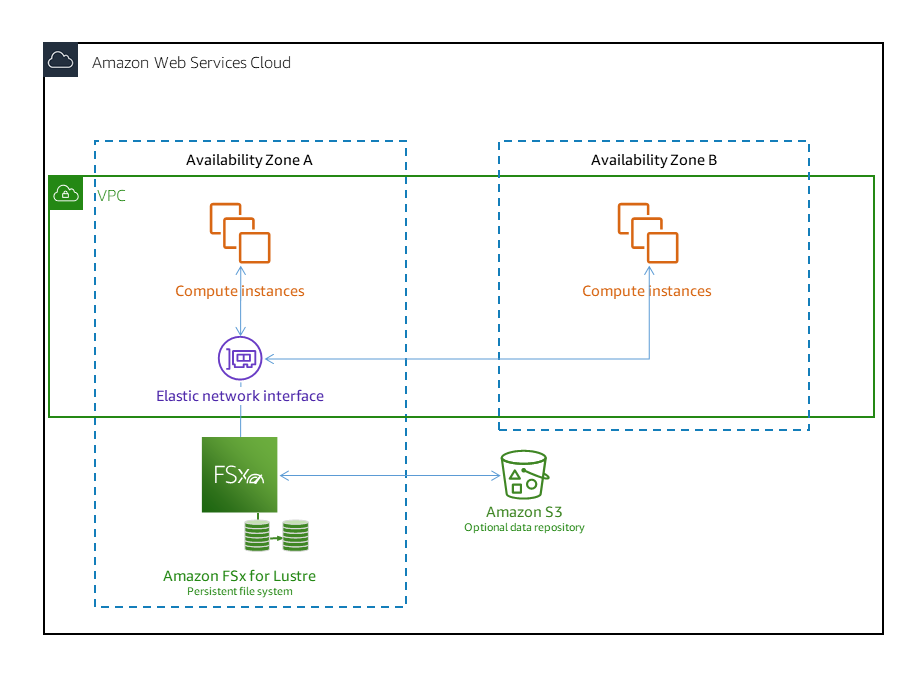
- Option B is incorrect because FSx for Lustre with Deployment Type as Persistent file systems are
designed for longer-term storage and workloads. The file servers are highly available, and data is
automatically replicated within the same Availability Zone in which the file system is located.
The
data volumes attached to the file servers are replicated independently from the file servers to
which they are attached.
- Option C is incorrect because Amazon EFS is not as effective as Amazon FSx for Luster when it
comes
to HPC design to deliver millions of IOPS (Input/Output Operations per Second) with
sub-millisecond
latency.
- Option D is incorrect. The storage requirement here is for POSIX-compliant file systems to support
Linux-based workloads. Hence Amazon FSx for Windows File Server is not suitable here.
Question 12
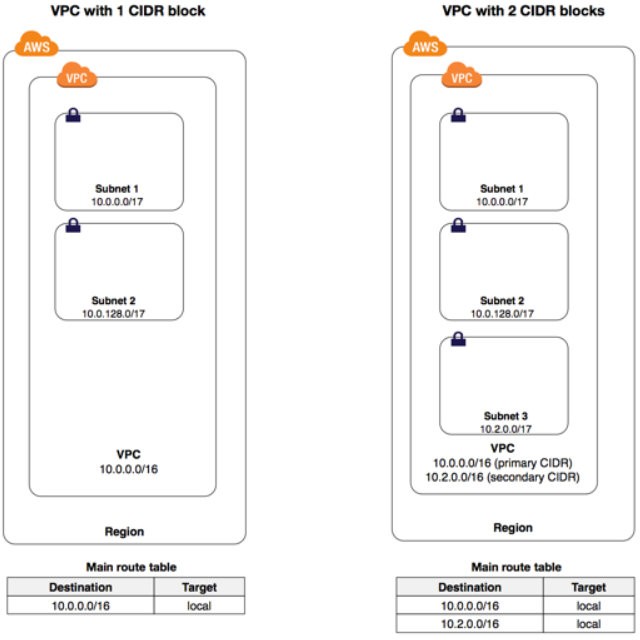
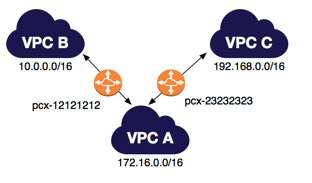
Which of the following statements is correct for the route table of the VPC created with the primary
CIDR of 20.0.0.0/16?
A.
VPC peering connection route for VPC with a 30.0.0.0/20 IP range.
B.
VPN connection route for the remote network with a 30.0.0.0/20 IP range.
C.
Direct Connect connection route for the remote network with a 30.0.0.0/20 IP range.
D.
Secondary IP CIDR range 30.0.0.0/20 for VPC with the local route
Answer: D
You can associate secondary IPv4 CIDR blocks with your VPC. When you associate a CIDR block with
your VPC, a route is automatically added to your VPC route tables to enable routing within the VPC (
the destination is the CIDR block and the target is local).
In the following example, the VPC on the left has a single CIDR block (10.0.0.0/16) and two subnets.
The VPC on the right represents the architecture of the same VPC after you've added a second CIDR
block (10.2.0.0/16) and created a new subnet from the range of the second CIDR. https://aws.amazon.com/about-aws/whats-new/2017/08/amazon-virtual-private-cloud-vpc-now-allows-customers-to-expand-their-existing-vpcs
From the above image, the Main route table shows the routes for primary and secondary IP ranges. So
the correct option is D.
For option A, VPC peering connection route contains Target as pcx-xxxxxx.
For option B, the routing table should contain an entry with 'vgw-xxxxx' for a VPN
connection.
For option C, the Direct Connect connection route should contain the Target as vgw-xxxxxx.
Question 13
To comply with industry regulations, a Healthcare organization wants to keep their large volume of
lab records in some durable, secure, lowest-cost AWS storage for a long period of time (say about
five years). The data will be rarely accessed once per quarter but requires immediate retrieval (in
milliseconds). You are a Solutions Architect in the organization and the organization wants your
suggestion to select a suitable storage class here. Which of the following would you recommend for
the given requirement?
A.
S3 Glacier Flexible Retrieval
B.
S3 Glacier Deep Archive
C.
S3 Glacier Instant Retrieval
D.
S3 Standard-Infrequent Access
Correct Answer: C
- Option A is incorrect because S3 Glacier Flexible Retrieval (formerly S3 Glacier) is the ideal
storage class to archive data that does not require immediate access but needs the flexibility to
retrieve large sets of data at no cost, such as backup or disaster recovery use cases.
S3 Glacier Flexible Retrieval delivers the most flexible retrieval options that balance cost with
access times ranging from minutes to hours and with free bulk retrievals.
- Option B is incorrect because S3 Glacier Deep Archive delivers the lowest cost storage, up to 75%
lower cost (than S3 Glacier), for long-lived archive data accessed less than once per year. It is
designed for customers — particularly those in the financial services, healthcare, media and
entertainment, and public sectors that retain data sets for 7-10 years or longer to meet customer
needs and regulatory compliance requirements.
- Option C is CORRECT because the Amazon S3 Glacier Instant Retrieval storage class is the
lowest-cost
storage for long-lived data that is rarely accessed but needs instant access in milliseconds to be
used for online file-sharing applications, image hosting, etc.
It can save storage costs up to 68% if the data is retrieved once in a quarter, compared to S3
Infrequent Access (IA).
- Option D is incorrect because S3 Standard-Infrequent Access is not cost-effective storage for
long-lived data. Actually, it is the most expensive among all the options here.
Question 14
An online retail company recently tied up with an external audit firm.
The retail company maintains all logs and saves them to an Amazon S3 bucket and the bucket access is
restricted by Service Control Policy (SCP) for all other accounts of the company except the Admin
account. The audit firm maintains all their audit related application and services in their own AWS
account, and needs immediate access to retail company’s S3 bucket to kick off their audit.
You are a solution architect and part of the admin team of the retail company, how should you enable
the bucket access for the external audit team in the most secure manner, with no operational and
management overload, and easy to deploy?
A.
Create a common IAM user in the retail company’s AWS account and attach it to the IAM Role that has
AmazonS3FullAccess. Share the IAM user details with the audit team
B.
Allow access to the audit firm in IAM Policy, Service Control Policy (SCP), and Amazon S3 Bucket
Policy in the retail company’s AWS account
C.
Allow S3 access to the audit firm in the retail company’s SCP, just like the Admin account
D.
Add a bucket policy on the S3 bucket granting access to the aws account of the audit firm. Add
HTTPS-only calls using “aws:SecureTransport” in the bucket policy
Correct Answer: D
- Option A is incorrect because this does not meet the condition of having secure access, plus this
is
also an overload of the operational and management team to manage external users. Also, you are
not
supposed to share the user details or credentials etc.
- Option B is incorrect. Allowing external users in IAM policy is not a secure solution as explained
above for Option A. Plus SCP does not have any effect outside organizations which is the Audit
firm
in this case. So only bucket policy can resolve this access issue - All three are not needed
here.
Image
Ref: https://docs.aws.amazon.com/organizations/latest/userguide/orgs_reference_available-policies.html
- Option C is incorrect because SCP has no effect on outside organizations which is the Audit firm
in
this case.
- Option D is CORRECT.
Bucket Policy for Account-Level Access:
Adding a bucket policy that allows access to the external audit firm's AWS account ensures secure
and direct access to the required resources without creating or sharing IAM users or roles.
HTTPS-Only Access:
The
1
"aws:SecureTransport"
condition ensures that all access to the bucket happens over a secure HTTPS connection, protecting
data in transit.
Avoids SCP Modifications:
SCPs are used to control access across AWS accounts within an organization. Modifying SCPs to grant
bucket access would complicate management and is unnecessary for this use case.
No IAM User Sharing:
Creating a shared IAM user introduces unnecessary operational and security risks, such as managing
credentials and access permissions.
A customer is looking for file storage in AWS that supports Network File System version 4 (NFSv4.1
and NFSv4.0) protocol. They want a simple, serverless, set-and-forget service that can grow and
shrink automatically as they add and remove files. Accessibility of these files is going to be
random and infrequent. The customer is also looking for an option to save cost by transitioning the
files that have not been accessed for quite some time automatically to a low-cost storage tier. As a
Solution Architect, which storage service will you choose that fits the customer’s requirement
perfectly?
A.
Use Amazon S3 for storage as it is for better cost-saving option
B.
Use Amazon S3 Glacier for the storage
C.
Use Amazon Elastic File System (EFS) with lifecycle policy
D.
Amazon FSx for Lustre
Correct Answer: C
- Option A is incorrect because S3 is indeed low cost, serverless storage, but not suitable for file
storage with the NFSv4 protocol. Also, the auto adjustment of the storage based on the addition or
deletion of files indicates towards Elastic File System (EFS).
- Option B is incorrect because Amazon S3 Glacier is the storage for archived data.
The Amazon S3 Glacier storage classes are purpose-built for data archiving and are the lowest cost
archive storage in the cloud.
Data archival is not a requirement here. Stress is more on elasticity and automatic transition.
Hence EFS with a Lifecycle rule would be the right choice.
- Option C is CORRECT because Amazon EFS fits all the requirements of being an elasticity and
self-managed serverless storage service. In addition, when it enabled EFS Lifecycle Management, it
will automatically handle cost-effective file storage. In this option, you set a period of time in
Transition into IA. Based on that, the lifecycle policy will archive your file to the EFS
Standard–Infrequent Access (Standard-IA) or One Zone–Infrequent Access (One Zone-IA) storage
class,
depending on your file system if the files haven’t been accessed for that defined period of
time.
Amazon EFS supports two lifecycle policies.
Transition into IA instructs lifecycle management on when to transit files into the file systems'
Infrequent Access storage class.
Transition out of IA instructs intelligent tiering when to transit files out of IA storage.
Lifecycle policies apply to the entire Amazon EFS file system.
- Option D is incorrect because Amazon FSX for Luster is a costly storage mainly used for
High-Performance Computing (HPC). It is not a good fit for the given requirement of the
customer.
Question 16
Your organization had setup a VPC with CIDR range 10.10.0.0/16. There are total 100 subnets within
the VPC and are being actively used by multiple application teams. An application team who is using
50 EC2 instances in subnet 10.10.55.0/24 complains there are intermittent outgoing network
connection failures for around 30 random EC2 instances in a given day. How would you troubleshoot
issue with minimal configuration and minimal logs written?
A.
Create a flow log for the VPC and filter the logs in CloudWatch log group.
B.
Create flow log for each EC2 instance network interface one by one and troubleshoot the connection
issue.
C.
Create a flow log for subnet 10.10.55.0/24.
D.
None of the above.
Answer: C
VPC Flow Logs captures IP traffic going to and from network interfaces in your VPC. Flow log data is
stored using Amazon CloudWatch Logs. After you've created a flow log, you can view and retrieve its
data in Amazon CloudWatch Logs.
You can create a flow log for a VPC, a subnet, or a network interface. https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/flow-logs.html#flow-logs-basics
VPC Flow Logs capture following information and logs them to CloudWatch logs,
version account-id interface-id srcaddr dstaddr srcport dstport protocol packets bytes start end
action log-status
Find more information about each record here. https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/flow-logs.html#flow-log-records
For option A, although creating a flow log for entire VPC would work, it captures lot of unrequired
information from rest 99 subnets and finding out the affected EC2 instances from CloudWatch logs
would become really troublesome.
For Option B, creating flow log at each EC2 network interface would work, but it takes log of
configuration and time consuming trial and error troubleshooting.
For Option C, creating a flow log for the subnet would capture just the traffic going in and out of
the subnet. This would help us identify the network trace for the affected EC2 instances and find
out the root cause in timely manner.
Question 17
The CIO of a Start-up company is very much concerned with the performance of their DevOps team as
they take a long time to detect and investigate issues using AWS resources. Sometimes this leads to
a revenue loss for the company. In addition to this, the same team had several compliance issues in
a recent security audit as the audit team found secure information like application configurations,
custom environment variables, product keys, credentials, and sensitive AMI IDs being mentioned
directly in the code.
The company has hired you as a Solution Architect, and the CIO instructed you to resolve all the
challenges faced by the DevOps team on priority and get them back to their efficiency.
He has also emphasized implementing a cost-effective solution for storing secure information that
does not need automated secret rotation.
What would you do to achieve the requirement? (Select TWO)
A.
For quick failure analysis and investigation, use AWS Systems Manager Application Manager
B.
For quick failure analysis and investigation, use AWS AppSync
C.
Resolve the compliance issue by storing all the secrets in AWS Secrets Manager and changing the code
to access the secrets from there
D.
Resolve the compliance issue by storing all the secrets in AWS Systems Manager Parameter Store and
changing the code to access the secrets from there
E.
Resolve the compliance issue by storing all the secrets in a private Amazon S3 bucket. Then create a
Gateway VPN Endpoint to access the secret from the bucket securely
Correct Answers: A and D
- Option A is CORRECT because AWS System Manager Application Manager is the capability of AWS
Systems
Manager which helps DevOps engineers to investigate and remediate issues with their AWS resources
in
the context of their applications and clusters. Application Manager reduces the time taken by the
DevOps engineers to detect and investigate issues with AWS resources. https://docs.aws.amazon.com/systems-manager/latest/userguide/application-manager.html
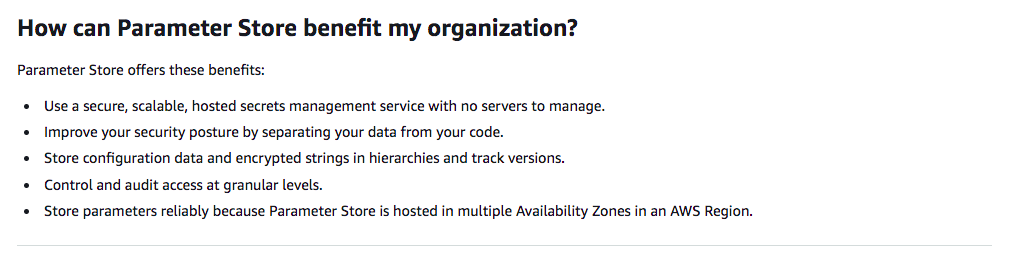
- Option D is CORRECT because AWS System Manager Parameter Store is a capability of AWS System
Manager
that provides secure, hierarchical storage for configuration data management and secrets
management.
You can store data such as passwords, database strings, Amazon Machine Image (AMI) IDs, and
license
codes as parameter values.
AWS Parameter Store is designed not just for secrets or passwords, but also for application
configuration variables like URLs, Custom settings, AMI IDs, License keys, etc. This is low cost
and
does not cause rotation of the secrets like AWS Secret Manager does. https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-parameter-store.html
- Option B is incorrect because AWS AppSync cannot help in failure analysis; it is a serverless
service to create fully managed GraphQL API. It is not suitable for the requirement given. Find
more
about AWS AppSync
here https://aws.amazon.com/appsync/
- Option C is incorrect because AWS Secrets Manager enables you to rotate, manage, and retrieve
database credentials, API keys, and other secrets throughout their lifecycle. It is designed
specifically for RDS confidential information (like database credentials and API keys etc.) that
needs to be encrypted. In the above use case, it was mentioned to have a service that is
cost-effective and does not rotate the secrets. Hence the use of AWS Parameter Store is more
preferable than AWS Secret Manager.
Check the difference between them
below: https://medium.com/awesome-cloud/aws-difference-between-secrets-manager-and-parameter-store-systems-manager-f02686604eae
- Option E is incorrect because using Amazon S3 for storing secrets is not a security best practice.
Technically it could be possible, but if you choose this option, you will put the DevOps team into
another compliance issue.
Question 18
An organization in the banking sector has got their AWS resources distributed in multiple
Availability Zones (AZ) in a region. They share one NAT gateway to connect to all their RDS
instances placed in Private Subnet in different AZs to the internet. While trying to perform some
Database related operations, the employee of the organization reported intermittent connectivity
issues. However, on checking the logs in AWS, they found that the RDS instances were all up and
running during the time when the issue was reported.
You are hired as a Solution Architect to identify the root cause of this connectivity issue and
remediate it without compromising security and resiliency. How would you approach this?
A.
The customer experiences a connectivity issue when the NAT gateway’s Availability Zone goes down. To
remediate this, create a NAT gateway in each Availability Zone and configure your routing to ensure
that resources use the NAT gateway in the same Availability Zone
B.
The customer experiences a connectivity issue due to insufficient IAM Policy and Roles. Resolve this
by adding the required permissions in the IAM Policy and attach them to the role used for the AWS
resources
C.
The customer experiences a connectivity issue due to low bandwidth in their network. Ask the
customer to sign up for a higher bandwidth plan with the network provider/operator
D.
The customer experiences the connectivity issue when the NAT gateway’s Availability Zone goes down.
To remediate this, remove the NAT gateway and use VPC Peering to connect to the Multi-AZ RDS
instances
Correct Answer: A
- Option A is CORRECT because when you have resources in multiple Availability Zones, and they share
one NAT gateway, and if the NAT gateway’s Availability Zone is down, resources in the other
Availability Zones lose internet access. In order to create an Availability Zone-independent
architecture, create a NAT gateway in each Availability Zone and configure your routing to ensure
that resources use the NAT gateway in the same Availability Zone.
- Option B is incorrect because the issue reported above is not caused by IAM Policies or Roles. It
is
mainly because of the fact that the Availability Zone of Nat Gateway goes down.
- Option C is incorrect because the issue reported above is not caused by the network bandwidth or
anything related to network speed etc. It is mainly because of the fact that the Availability Zone
of Nat Gateway goes down.
- Option D is incorrect because even though it reasoned out the right cause, the remediation is not
correct. VPC Pairing is a connection that interconnects multiple VPCs and enables traffic between
them using private IPv4 addresses or IPv6 addresses. VPC Pairing does not let them access the
internet.
Image
Source: https://docs.aws.amazon.com/vpc/latest/peering/vpc-peering-basics.html
Question 19
An online advertising company wants to build a solution in AWS that will understand the interest of
the customer and provide relevant and personalized recommendations of new products to them. The
company is looking for a self-managed, highly durable, and available Database engine that stores
relationships between information such as customer’s interests, community networks, friend circle,
likes, purchase history, etc., and quickly maps them to identify the pattern.
As a Solution Architect in the company, what would be your recommendations for the database here?
A.
Amazon DocumentDB
B.
Amazon DynamoDB
C.
Amazon Aurora
D.
Amazon Neptune
Correct Answer: D
- Option A is incorrect because Amazon DocumentDB is a scalable, highly durable, and fully managed
database service for operating mission-critical MongoDB workloads. Amazon DocumentDB is not
suitable
for the requirement of a relationship mapping database that helps identify patterns.
- Option B is incorrect because Amazon DynamoDB is a fully managed, serverless, key-value NoSQL
database designed to run high performance applications at any scale. DynamoDB offers built-in
security, continuous backups, automated multi-Region replication, in-memory caching, and data
export
tools. Amazon DynamoDB is not suitable for the requirement of a relationship-based or
mapping-based
database.
- Option C is incorrect because Amazon Aurora is a relational database management system (RDBMS)
built
for the cloud with full MySQL and PostgreSQL compatibility. Aurora gives you the performance and
availability of commercial-grade databases at one-tenth the cost. It is not suitable for the
requirement of a relationship-based or mapping-based database.
- Option D is CORRECT because Amazon Neptune is a fast, reliable, fully managed graph database
service
that makes it easy to build and run applications that work with highly connected datasets. The
core
of Amazon Neptune is a purpose-built, high-performance graph database engine optimized for storing
billions of relationships and querying the graph with milliseconds latency.
Question 20
In response to the high demand and increase in load, a customer plans to migrate his on-premises and
native MongoDB to AWS Cloud. The customer is looking for a compatible Database solution in AWS for
easy and fast migration with minimum operation and management overhead. The new database should also
be compatible with existing MongoDB so that the applications don’t require code changes.
As a Solution Architect in the company, what would be your suggestion for this scenario?
A.
Amazon DocumentDB
B.
Amazon DynamoDB
C.
Amazon Keyspaces
D.
Amazon Neptune
Correct Answer: A
- Option A is CORRECT because Amazon DocumentDB (with MongoDB compatibility) is scalable, highly
durable, and fully managed database service for operating mission-critical MongoDB workloads. As
it
comes with MongoDB compatibility, the migration from MongoDB to DocumentDB gets very easy without
changing the schema. The existing applications remain as they are without changing the
code.
- Option B is incorrect because Amazon DynamoDB is a fully managed, serverless, key-value NoSQL
database designed to run high-performance applications at any scale. DynamoDB offers built-in
security, continuous backups, automated multi-Region replication, in-memory caching, and data
export
tools. Amazon DynamoDB is not suitable for the requirement of a MongoDB compatible
database.
- Option C is incorrect because Amazon Keyspaces is a scalable, highly available, and managed Apache
Cassandra–compatible database service. With Amazon Keyspaces, you can run your Cassandra workloads
on AWS by using the same Cassandra application code and developer tools that you use today. This
option is not suitable for MongoDB migration.
- Option D is incorrect because Amazon Neptune is a fast, reliable, fully managed graph database
service that makes it easy to build and run applications that work with highly connected datasets.
The core of Amazon Neptune is a purpose-built, high-performance graph database engine optimized
for
storing billions of relationships and querying the graph with milliseconds latency, but it is not
suitable for the requirement of a MongoDB compatible database.
Question 21
You are an engineer in charge of the FinOps department of your organization. The multi-account
strategy has been created using AWS Control Tower as part of the best practices and recommendations.
You want to ensure that all accounts under the ‘OU=development’ of the AWS Organizations should not
create resources outside of Ireland (eu-west-1). How can you make sure that the required condition
is applied using the below Policy Statement?
A.
Add the Policy Statement to a Permissions Boundary to the developer IAM role
B.
Add the Policy Statement to the SCP (Service control policy) and attach it to the Organizational
Unit OU=development
C.
Add the Policy Statement to the SCP (Service control policy) and attach it to the Organizational
Unit OU=root
D.
Add the Policy Statement as a managed policy for the role
Correct Answer: B
- Option A is incorrect because the policy is not assigned to an OU, just to a role under
Permissions
Boundary. Other roles could create resources outside eu-west-1. It is also important to remark
that
SCPs are not related to the IAM Permissions Boundary.
- Option B is CORRECT because the policy statement is matching that all the resources being created
outside of eu-west-1 will be denied. The policy is also attached to the OU=development.
- Option C is incorrect because the OU where we want to apply the policy is the OU=development, not
the whole AWS Organization.
- Option D is incorrect because the policy statement is not being applied to an OU.
Question 22
You are working in a multimedia company and want to transfer a massive amount of data to Amazon S3.
You have heard that SnowBall Edge could be the right tool for this purpose. When you are trying to
transfer data using the AWS CLI, one of our biggest files of 12TB, you get an error with the client
validating this transfer. What could be the main cause of the error?
A.
The maximum file size that could be transferred using the AWS CLI is 150GB
B.
The maximum file size that could be transferred using the AWS CLI is 5TB
C.
The role that you are using to transfer files can’t transfer more than 5TB
D.
Amazon S3 support files larger than 10TB
Correct Answer: B
- Option A is incorrect because the maximum size that can be transferred is 5TB. 150GB is
considerable
when using NFS for data transfer.
- Option B is CORRECT because the maximum size that can be transferred is 5TB. The file that we are
trying to upload is higher than 5TB.
- Option C is incorrect because the issue is during the AWS client validation, not a permission
denied
issue caused by the Policy statements. This is also an impossible cause.
- Option D is incorrect because Amazon S3 doesn’t support files larger than 5TB.
Question 23
You are a Research Scientist working on NLP (Natural Language Processing) models. You are planning
to use Amazon Comprehend to do some research about multiple texts that are currently stored in your
email, but you have some ownership concerns about this service. Who would retain the ownership of
the content of the emails that you will analyze using Amazon Comprehend?
A.
Customer
B.
AWS
C.
A third-party company that is in charge of managing the Amazon Comprehend service
D.
Both, AWS and the Customer
Correct Answer: A
Amazon Comprehend is a natural-language processing (NLP) service that uses machine learning to
uncover valuable insights and connections in text.
- Option A is CORRECT because the owner will be the customer. Amazon will use the content with the
consent of the customer.
- Option B is incorrect because AWS does not have the ownership of the analyzed content processed by
Amazon Comprehend.
- Option C is incorrect because there is no third-party company involved in the management of Amazon
Comprehend.
- Option D is incorrect because both cannot share the ownership of the content by Amazon
Comprehend.
Question 24
You are a DevOps Engineer specializing in Containers. You want to run your container workloads
running in a Linux environment in your current Data Center for regulations with easy management of
your Docker tasks using the AWS Console. You have heard about Amazon ECS Anywhere, and you would
like to explore it deeply. What are the main components you should have in your current Linux
Servers in an ECS Cluster?
A.
AWS Systems Manager Agent, Amazon ECS container agent, and Docker must be installed on these Linux
Servers
B.
AWS Systems Manager Agent Docker must be installed as part of the process
C.
Amazon ECS container agent and Docker must be installed on these external instances
D.
The Amazon CloudWatch Agent, Amazon ECS container agent, and Docker must be installed on these
external instances
Correct Answer: A
Amazon Elastic Container Service (ECS) Anywhere is a feature of Amazon ECS that enables you to run
and manage container workloads on customer-managed infrastructure efficiently.
ECS Anywhere builds upon the ease and simplicity of Amazon ECS to provide a consistent tooling and
API experience across your container-based applications.
- Option A is CORRECT because you need AWS Systems Manager to supply a secret activation code that
allows the agent to register itself with AWS Systems Manager as a managed instance, which is
necessary to run your instances on ECS Anywhere.
Also, it is necessary for the Amazon ECS agent to have connectivity with your ECS Cluster.
Docker is used if you want to run container workloads on-prem.
And you can apply the following command on your Linux instance to register to the Amazon
ECS:
curl --proto "https" -o "
/tmp/ecs-anywhere-install.sh" " https://amazon-ecs-agent.s3.amazonaws.com/ecs-anywhere-install-latest.sh &&
bash /tmp/ecs-anywhere-install.sh --region "YourRegion" --cluster "Cluster-name" --activation-id "
xxxxxxx-xxxx-xxxx-xxxx-xxxxxxx" --activation-code "xxxxxxxxx"
- Option B is incorrect because Amazon ECS agents must also be included, if not, the servers can’t
be
registered on the ECS cluster.
- Option C is incorrect because Amazon Systems Manager Agent must also be included, if not, the
servers will not be registered as managed instances and will not complete the registration of the
servers into the ECS Cluster.
- Option D is incorrect as we are missing the Amazon Systems Manager Agent. Amazon CloudWatch agent
would provide the possibility to forward logs to Amazon CloudWatch , but the servers will not be
able to register.
Question 25
You are a DevOps Engineer for a company specializing in Container technology. You are currently
running your container workloads nodes in your bare metal nodes due to regulatory compliance rules.
You would like to continue running your workloads on hardware (bare metal) without any
virtualization, but want to use an AWS-managed service for managing multiple clusters of nodes. What
is the best solution to integrate your container workloads from your data Center using a Kubernetes
ecosystem?
A.
Use Amazon ECS Anywhere
B.
Move all your workloads from your current Data Center to Amazon EKS
C.
Deploy an Amazon EKS Anywhere technology on bare metal nodes
D.
Create a VMware vSphere cluster and integrate it with Amazon EKS Anywhere
Correct Answer: C
Amazon EKS Anywhere is a deployment option for Amazon EKS that allows customers to create and
operate Kubernetes clusters on customer-managed infrastructure, supported by AWS.
- Option A is incorrect because the question clearly mentions there is a need for the Kubernetes
ecosystem, so no need for Amazon ECS or Amazon ECS Anywhere.
- Option B is incorrect because the question mentions that the DevOps engineers of the company are
running their workloads on bare metal servers and would like to continue with that. So there is no
need to move the workloads to Amazon EKS.
- Option C is correct because the engineer wants to run their workloads on hardware only with no
virtualization, so it is good to deploy the Amazon EKS Anywhere technology on bare metal nodes.
Running Kubernetes on bare metal instances will take full advantage of the servers because the
operating system is communicating with the physical hardware.
- Option D is incorrect because the question mentions that the engineer wants to continue with
hardware only without virtualization. If no virtualization then no need for VMware vSphere.
Question 26
A manufacturing company operates a network of factories globally and wants to modernize its
application infrastructure by containerizing its legacy applications. However, due to regulatory
requirements, some of these applications must remain on-premises. Additionally, the company aims to
convert their existing on-premises instances into managed instances to simplify operations. Which
AWS service would be most suitable for deploying and managing containerized applications in both
on-premises and cloud environments?
A.
Use Amazon Elastic Kubernetes Service (Amazon EKS) and deploy AWS Systems Manager agent onto
operating systems managed by the customer, effectively transitioning the operating systems into
managed instances
B.
Use Amazon ECS Anywhere and deploy AWS Systems Manager agent onto operating systems managed by the
customer, effectively transitioning the operating systems into managed instances
C.
Use Amazon Elastic Container Registry and install docker onto operating systems managed by the
customer effectively transitioning the operating systems into managed instances
D.
Use Amazon EKS Distro and install docker onto operating systems managed by the customer effectively
transitioning the operating systems into managed instances
Correct Answer: B
Amazon ECS Anywhere allows the company to deploy and manage containerized applications in both
on-premises and cloud environments. By deploying the AWS Systems Manager agent onto customer-managed
operating systems, the company can centrally manage and automate administrative tasks for these
instances, effectively converting them into managed instances.
- Option A is incorrect because Amazon EKS is a managed Kubernetes service and is suitable for
deploying and managing containerized applications in the cloud, it does not directly address the
requirement for managing on-premises instances and converting them into managed instances.
- Option C is incorrect because Amazon Elastic Container Registry is a fully managed Docker
container
registry that makes it easy for developers to store, manage, and deploy Docker container
images.
- Option D is incorrect because Amazon EKS Distro is a Kubernetes distribution that is compatible
with
Amazon EKS. While it allows for running Kubernetes clusters on-premises, it does not directly
address the requirement for managing on-premises instances and converting them into managed
instances.
Question 27
You are the owner of a Microservices application that has a poor latency when it runs into the ECS
cluster. Which AWS services could help you analyze the root cause by tracing different calls into
the application?
A.
Amazon CloudWatch
B.
AWS X-Ray
C.
Amazon Event Bridge
D.
Amazon CloudTrail
Correct Answer: B
AWS X-Ray is a service that collects data about requests that your application serves and provides
tools that you can use to view, filter, and gain insights into that data to identify issues and
opportunities for optimization.
- Option A is incorrect because Amazon CloudWatch can check your application's logs and monitoring
dashboards, but you can’t trace specific traffic calls.
- Option B is CORRECT because you can analyze different request calls happening in your application
with AWS X-Ray.
- Option C is incorrect because Amazon Event Bridge is for managing Services events, not tracing or
monitoring applications.
- Option D is incorrect because Amazon CloudTrail is an auditing solution. You can check API calls
for
your account, but it can’t provide you with traces from your application
Question 28
A company is exploring options to modernize its infrastructure and manage Kubernetes clusters across
its on-premises data center and AWS cloud environment. The company seeks a solution that provides
consistent operational experience, ease of management, and seamless integration with AWS services.
Which of the following options would best fulfill the company’s requirements?
A.
Leveraging Amazon ECS Anywhere to manage containerized applications across both on-premises and AWS
cloud environments
B.
Utilizing Amazon EKS (Elastic Kubernetes Service) to manage Kubernetes clusters exclusively within
the AWS cloud environment
C.
Adopting Amazon EKS Anywhere to deploy and manage Kubernetes clusters both on-premises and in the
AWS cloud environment
D.
Deploying Kubernetes clusters on-premises using the EKS Distro and managing AWS resources with AWS
CloudFormation
Correct Answer: C
Adopting Amazon EKS Anywhere allows to deploy and manage Kubernetes clusters both on-premises and in
the AWS cloud environment. This option provides a consistent operational experience, ease of
management, and seamless integration with AWS services, fulfilling the requirements
effectively.
- Option A is incorrect because Leveraging ECS Anywhere focuses on managing containerized
applications
and does not provide native support for Kubernetes clusters, thus not aligning with the
requirement
for Kubernetes cluster management.
- Option B is incorrect because Utilizing Amazon EKS to manage Kubernetes clusters exclusively
within
the AWS cloud environment does not address the requirement to manage clusters across on-premises
data centers and AWS cloud environment.
- Option D is incorrect because Deploying Kubernetes clusters on-premises using the EKS Distro and
managing AWS resources with AWS CloudFormation may introduce challenges in achieving consistent
operational experience and seamless integration across environments.
Question 29
You are a Cloud Database Administrator and want to enable IAM authentication on your Aurora
Databases for the user ‘iam_db_user’. Which of the following is the correct method to enable the IAM
authentication in your Aurora MySQL Database using AWSAuthenticationPlugin?
A.
CREATE USER iam_db_user IDENTIFIED WITH AWSAuthenticationPlugin;
B.
CREATE USER iam_db_user_plugin;
C.
Rename IAM iam_db_user as a Database user
D.
CREATE USER iam_db_user IDENTIFIED WITH AWSAuthenticationPlugin AS ‘RDS’;
Correct Answer: D
The IDENTIFIED WITH clause allows MariaDB and MySQL to use the AWSAuthenticationPlugin to
authenticate the database account (iam_db_user). The AS 'RDS' clause refers to the authentication
method.
- Option A is incorrect because the command is missing the clause that refers to the authentication
method “as RDS”.
- Option B is incorrect because the command is missing the clause that refers to the authentication
method and the clause which allows Aurora MySQL to use the AWSAuthenticationPlugin.
- Option C is incorrect because renaming the IAM user is not a valid option to provide
authentication.
You need to create a new user for the Aurora RDS Database.
- Option D is CORRECT because you need to create a USER on your database with the clause referring
to
the authentication method and the clause that allows Aurora MySQL to use the
AWSAuthenticationPlugin.
Question 30
You are using AWS DataSync to migrate more than 8TB from on-prem to Amazon S3. After the first
DataSync task runs, you notice that some files were not copied. After reviewing the CloudWatch logs,
you noticed that the files were skipped. What could be the main cause? (Select TWO)
A.
The source file was locked and couldn’t be opened by AWS DataSync
B.
The source file was opened and modified while it was transferred
C.
The source file’s owner has been changed after it was transferred during the VERIFYING phase
D.
The source file’s permissions are changed after it was transferred and couldn’t be read during the
VERIFYING phase
Correct Answers: A and B
- Option A is CORRECT because AWS Datasync can’t open a file if this file is locked. AWS DataSync
will
skip the file and log the error.
- Option B is CORRECT because DataSync detects the data inconsistency during the VERIFYING phase if
a
file is modified during the transfer. In this phase, DataSync detects whether the file on the
source
differs from the file on the destination.
- Option C is incorrect because modifying the ownership doesn’t affect the file being transferred or
not.
- Option D is incorrect because changing the permissions after the file was transferred doesn’t
affect
the copy phase.
Question 31
A transportation company operates a fleet of delivery trucks equipped with on-board cameras to
monitor road conditions and driver behavior. They need a solution to stream and analyze video data
in real-time to ensure driver safety and optimize route efficiency. Which AWS service would be most
suitable for their use case?
A.
AWS IoT Core
B.
Amazon Kinesis Video Streams
C.
Amazon Kinesis Data Streams
D.
Amazon Elastic Transcoder
Correct Answer: B
Amazon Kinesis Video Streams is specifically designed to securely ingest, process, and analyze video
streams in real-time. It provides the necessary scalability, low latency, and integration with other
AWS services to meet the company's requirements for monitoring road conditions and driver
behavior.
- Option A is incorrect because AWS IoT Core is suitable for connecting IoT devices and managing
device communication, it is not optimized for handling video streams and analyzing video
data.
- Option C is incorrect because Amazon Kinesis Data Streams is a service for ingesting and
processing
real-time data streams, but it is optimized for generic data, such as log data, application
metrics,
or IoT telemetry.
- Option D is incorrect because Amazon Elastic Transcoder is a scalable media transcoding service.
It
allows users to convert media files stored in one format into versions that will play back on
devices like smartphones, tablets, and PCs.
Question 32
You are working in a start-up company, and you need to save the cost of Amazon EC2, AWS Fargate, and
AWS Lambda. You are looking for a flexible pricing model. For example, you will be charged at a
lower rate if you commit to $10/hour of compute usage. Which AWS service can achieve this
requirement?
A.
AWS Savings Plan
B.
AWS Reserved Instance.
C.
AWS Dedicated Host.
D.
AWS Spot Instance
Correct Answer – A
- Option A is CORRECT: Because Savings Plans is a flexible pricing model that provides low prices in
exchange for commitment. For its details, please check the following reference.
- Option B is incorrect: Because AWS Reserved Instance is only for EC2 and does not help to reduce
the
cost of AWS Fargate or AWS Lambda.
- Option C is incorrect: Because AWS Dedicated Host provides dedicated hardware, which does not help
cut the cost.
- Option D is incorrect: Because AWS Spot Instance is only for EC2 and not for AWS Fargate or AWS
Lambda.
Question 33
You are a solutions architect working for a data analytics company that delivers analytics data to
politicians that need the data to manage their campaigns. Political campaigns use your company’s
analytics data to decide on where to spend their campaign money to get the best results for the
efforts. Your political campaign users access your analytics data through an Angular SPA via API
Gateway REST endpoints. You need to manage the access and use of your analytics platform to ensure
that the individual campaign data is separate. Specifically, you need to produce logs of all user
requests and responses to those requests, including request payloads, response payloads, and error
traces. Which type of AWS logging service should you use to achieve your goals?
A.
Use CloudWatch access logging
B.
Use CloudWatch execution logging
C.
Use CloudTrail logging
D.
Use CloudTrail execution logging
Correct Answer: B
- Option A is incorrect. CloudWatch access logging captures which resource accessed an API and the
method used to access the API. It is not used for execution traces, such as capturing request and
response payloads.
- Option B is correct. CloudWatch execution logging allows you to capture user request and response
payloads as well as error traces.
- Option C is incorrect. CloudTrail captures actions by users, roles, and AWS services. CloudTrail
records all AWS account activity. CloudTrail does not capture error traces.
- Option D is incorrect. CloudTrail does not have a feature called execution logging.
Question 34
You are a solutions architect working for a media company that produces stock images and videos for
sale via a mobile app and website. Your app and website allow users to gain access only to stock
content they have purchased. Your content is stored in S3 buckets. You need to restrict access to
multiple files that your users have purchased. Also, due to the nature of the stock content (
purchasable by multiple users), you don’t want to change the URLs of each stock item.
Which access control option best fits your scenario?
A.
Use CloudFront signed URLs
B.
Use S3 Presigned URLs
C.
Use CloudFront Signed Cookies
D.
Use S3 Signed Cookies
Correct Answer: C
- Option A is incorrect. CloudFront signed URLs allow you to restrict access to individual files.
Signed URLs require you to change your content URLs for each customer access.
- Option B is incorrect. S3 Presigned URLs require you to change your content URLs. The presigned
URL
expires after its defined expiration date.
- Option C is correct. CloudFront Signed Cookies allow you to control access to multiple content
files
and you don’t have to change your URL for each customer access.
- Option D is incorrect. There is no S3 Signed Cookies feature.
Question 35
You are a solutions architect working for a financial services firm that operates applications in a
hybrid cloud model. Your applications are running on EC2 instances in your VPC, which communicate
with resources in your on-premises data center. You have a workload on an EC2 network interface in
one subnet and a transit gateway association in a different subnet, and these two subnets are
associated with different Network Access Control Lists (NACLs) rules.
Given this setup, which of the following statements is true regarding the NACL rules for traffic
from your EC2 instances to the transit gateway?
A.
Outbound rules use the source IP address to evaluate traffic from the instances to the transit
gateway
B.
Outbound rules use the destination IP address to evaluate traffic from the instances to the transit
gateway
C.
Outbound rules are not evaluated for the transit gateway subnet
D.
Inbound rules use the destination IP address to evaluate traffic from the transit gateway to the
instances
Correct Answer: B
The question asks for the NACL rule when the instances and transit gateway are in different subnets
and traffic flows from EC2 instance to transit gateway.
- Option A is incorrect. For traffic outbound from your EC2 instance subnet, the source IP address
is
not valid, the destination IP address is used to evaluate the rule.
- Option B is correct. This is the required rule NACLs should follow when the instances and transit
gateway are in different subnets and the traffic flows from instances to the transit
gateway.
Network ACL Outbound rules use the destination IP address to evaluate traffic from the instances
to
the transit gateway.
- Option C is incorrect because when the instances and transit gateway are in different subnets,
outbound rules are evaluated and provide the flow of traffic as required.
- Option D is incorrect. For traffic inbound from your transit gateway, the source IP address is
used
to evaluate the rule.
Question 36
A start-up firm has created account A using the Amazon RDS DB instance as a database for a web
application. The operations team regularly creates manual snapshots for this DB instance in
unencrypted format. The Projects Team plans to create a DB instance in other accounts using these
snapshots. They are looking for your suggestion for sharing this snapshot and restoring it to DB
instances in other accounts. While sharing this snapshot, it must allow only specific accounts
specified by the project teams to restore DB instances from the snapshot.
What actions can be initiated for this purpose?
A.
From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as private.
In other Accounts, directly restore to DB instances from the snapshot
B.
From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as public.
In other Accounts, directly restore to DB instances from the snapshot
C.
From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as private.
In other Accounts, create a copy from the snapshot and then restore it to the DB instance from that
copy
D.
From Account A, share the manual snapshot by setting the ‘DB snapshot’ visibility option as public.
In other Accounts, create a copy from the snapshot and then restore it to the DB instance from that
copy
Correct Answer: A
DB snapshot can be shared with other authorized AWS accounts which can be up to 20 accounts. These
snapshots can be either in encrypted or unencrypted format.
For manual snapshots in an unencrypted format, accounts can directly restore a DB instance from the
snapshot.
For manual snapshots in an encrypted format, accounts first need to copy the snapshot and then
restore it to a DB instance.
While sharing a manual unencrypted snapshot, all accounts can use this snapshot to restore to the DB
instance when DB snapshot visibility is set to public.
While sharing a manual unencrypted snapshot, only specified accounts can restore a DB instance when
DB snapshot visibility is set to private.
In the case of manual encrypted snapshots, the only available option for DB snapshot visibility is
private, as encrypted snapshots cannot be made public.
- Option B is incorrect as marking DB snapshot visibility as the public is not an ideal option since
snapshots need to share only with specific accounts. Marking DB snapshot visibility as public will
provide all Amazon accounts access to the manual snapshot and will be able to restore DB instances
using this snapshot.
- Option C is incorrect as DB instances can be directly restored from the snapshot for a manual
unencrypted snapshot. There is no need to create a copy of the snapshot to restore a DB
instance.
- Option D is incorrect as already discussed, marking DB snapshot visibility as the public is not an
ideal option. For a manual unencrypted snapshot, DB instances can be directly restored from the
snapshot.
Question 37
An electronic manufacturing company plans to deploy a web application using the Amazon Aurora
database. The Management is concerned about the disk failures with DB instances and needs your
advice for increasing reliability using Amazon Aurora automatic features. In the event of disk
failures, data loss should be avoided, reducing additional work to perform from the point-in-time
restoration.
What design suggestions can be provided to increase reliability?
A.
Add Aurora Replicas to primary DB instances by placing them in different regions. Aurora’s crash
recovery feature will avoid data loss post disk failure
B.
Add Aurora Replicas to primary DB instances by placing them in different availability zones. Aurora
storage auto-repair feature will avoid data loss post disk failure
C.
Add Aurora Replicas to the primary DB instance by placing them in different regions. Aurora
Survivable page cache feature will avoid data loss post disk failure
D.
Add Aurora Replicas to the primary DB instance by placing them in different availability zones.
Aurora’s crash recovery feature will avoid data loss post disk failure
Correct Answer: B
Amazon Aurora Database reliability can be increased by adding Aurora Replicas to the primary DB
instance and placing them in different Availability zones. Each of the DB clusters can have a
primary DB instance and up to 15 Aurora Replicas. In case of primary DB instance failure, Aurora
automatically fails over to replicas. Amazon Aurora also uses the following automatic features to
enhance reliability,
Storage auto-repair: Aurora maintains multiple copies of the data in three different Availability
zones. This helps in avoiding data loss post disk failure. If any segment of the disk fails, Aurora
automatically recovers data on the segment by using data stored in other cluster volumes. This
reduces additional work to perform point-in-time restoration post disk failure.
Survivable page cache: Manage page cache in a separate process than the database. In the event of
database failure, the page cache is stored in the memory. Post restarting the database, applications
continue to read data from the page cache providing performance gain.
Crash recovery: Crash recovery can be used for faster recovery post any crash in the database. With
the crash recovery feature, Amazon Aurora performs recovery asynchronously on parallel threads
enabling applications to read data from the database without binary logs.
- Option A is incorrect. Aurora Replicas should be created in different Availability zones and not
in
different regions for better availability. The crash recovery does not minimize data loss post
disk
failures.
- Option C is incorrect. The Survivable page cache feature provides performance gains but does not
minimize data loss post disk failures. Aurora Replicas should be created in different Availability
zones and not in different regions.
- Option D is incorrect as the crash recovery feature does not minimize data loss post disk
failures.
Question 38
A financial institute has deployed a critical web application in the AWS cloud. The management team
is looking for a resilient solution with RTO/RPO in 20 minutes during a disaster. They have budget
concerns, and the cost of provisioning the backup infrastructure should not be very high. As a
solution architect, you have been assigned to work on setting a resilient solution meeting the
RTO/RPO requirements within the cost constraints.
Which strategy is suited perfectly?
A.
Multi-Site Active/Active
B.
Warm Standby
C.
Backup & Restore
D.
Pilot Light
Correct Answer: D
RTO (Recovery Time Objective) is a period for which downtime is observed post-disaster. It’s the
time between the disaster and application recovery to serve full workloads. RPO (Recovery Point
Objective) defines the amount of data loss during a disaster. It measures the time window when the
last backup was performed, and the time when the disaster happened. Various Disaster recovery
solutions can be deployed based on RTO/RPO and budget requirements for critical applications.
The following are options available with Disaster recovery,
Backup and Restore: Least expensive among all the options but RTO/RPO will be very high in hours.
All backup resources will be initiated only after a disaster at the primary location.
Pilot Light: Less expensive than warm standby and multi-site active/active. RTO/RPO happens in tens
of minutes.
In this strategy, a minimum number of active resources are deployed at the backup locations.
Resources required for data synchronization between primary and backup locations are only
provisioned and are active. Other components such as application servers are switched off and are
provisioned post a disaster at the primary location. In the above scenario, Pilot Light is the most
suitable option to meet RTO/RPO requirements on a low budget.
Warm Standby: Expensive Than Pilot Light. RPO/RTO happens in minutes. The application is running at
the backup location on scaled-down resource capacity. Once a disaster occurs at the primary
location, all the resources are scaled up to meet the desired workload.
Multi-site active/active: Most expensive. No downtime or data loss is incurred as applications are
active from multiple regions.
The following diagram shows the difference between each strategy with respect to RTO/RPO and
cost.
- Option A is incorrect as with a multi-site active/active approach, RPO/RTO will be the least, but
it
will incur considerable cost.
- Option B is incorrect as, with a Warm Standby approach, RPO/RTO will be in minutes, but it will
incur additional costs.
- Option C is incorrect as with the Backup & Restore approach, RPO/RTO will be in hours, not in
minutes.
Question 39
A critical application deployed in AWS Cloud requires maximum availability to avoid any outages. The
project team has already deployed all resources in multiple regions with redundancy at all levels.
They are concerned about the configuration of Amazon Route 53 for this application which should
complement higher availability and reliability. Route 53 should be configured to use failover
resources during a disaster.
What solution can be implemented with Amazon Route 53 for maximum availability and increased
reliability?
A.
Associate multiple IP endpoints in different regions to Route 53 hostname. Use a weighted route
policy to change the weights of the primary and failover resources. So, all traffic is diverted to
failover resources during a disaster
B.
Create two sets of public-hosted zones for resources in multiple regions. During a disaster, update
Route 53 public-hosted zone records to point to a healthy endpoint
C.
Create two sets of private hosted zones for resources in multiple regions. During a disaster, update
Route 53 private hosted zone records to point to a healthy endpoint
D.
Associate multiple IP endpoints in different regions to Route 53 hostname. Using health checks,
configure Route 53 to automatically failover to healthy endpoints during a disaster
Correct Answer: D
Amazon Route 53 uses control planes to perform management-related activities such as creating,
updating, and deleting resources.
The Data plane is used for performing core services of Amazon Route 53 such as authoritative DNS
service, health checks, and responding to DNS queries in an Amazon VPC.
The Data plane is globally distributed, offering 100% availability SLA. Control plane traffic is
optimized for data consistency and may be impacted during disruptive events in the
infrastructure.
While configuring failover between multiple sites, data plane functions such as health checks should
be preferred instead of control plane functions. In the above case, multiple endpoints in different
regions can be associated with Route 53. Route 53 can be configured to failover to a healthy
endpoint based upon the health checks which is a data plane function and always available.
- Option A is incorrect as updating weights in a weighted routing policy is a control plane
function.
For additional resiliency during a disaster, use data plane functions instead of control plane
functions.
Options B and C are incorrect as creating, updating, and deleting private or public hosted zone
records are part of control plane actions. In case of a disaster, control planes might get
affected.
Data plane functions such as health checks should be used for resources that are always
available.
Question 40
An IT company is using EBS volumes for storing projects related work. Some of these projects are
already closed. The data for these projects should be stored long-term as per regulatory guidelines
and will be rarely accessed. The operations team is looking for options to store the snapshots
created from EBS volumes. The solution should be cost-effective and incur the least admin work.
What solution can be designed for storing data from EBS volumes?
A.
Create EBS Snapshots from the volumes and store them in the EBS Snapshots Archive
B.
Use Lambda functions to store incremental EBS snapshots to AWS S3 Glacier
C.
Create EBS Snapshots from the volumes and store them in a third-party low-cost, long-term storage
D.
Create EBS Snapshots from the volumes and store them in the EBS standard tier
Correct Answer: A
Amazon EBS has a new storage tier named Amazon EBS Snapshots Archive for storing snapshots that are
accessed rarely and stored for long periods.
By default, snapshots created from Amazon EBS volumes are stored in Amazon EBS Snapshot standard
tier. These are incremental snapshots. When EBS snapshots are archived, incremental snapshots are
converted to full snapshots.
These snapshots are stored in the EBS Snapshots Archive instead of the standard tier. Storing
snapshots in the EBS Snapshots archive costs much less than storing snapshots in the standard tier.
EBS snapshot archive helps store snapshots for long durations for governance or compliance
requirements, which will be rarely accessed.
- Option B is incorrect as it will require additional work for creating an AWS Lambda function. EBS
Snapshots archive is a more efficient way of storing snapshots for the long term.
- Option C is incorrect as using third-party storage will incur additional costs.
- Option D is incorrect as all EBS snapshots are stored in a standard tier by default. Storing
snapshots that will be rarely accessed in the standard tier will be costlier than storing in the
EBS
snapshots archive.
Question 41
A company is sharing geospatial data with users in different AWS accounts for commercial purposes.
Users from these accounts access a large amount of data stored in the Amazon S3 bucket in the
us-east-1 region from different AWS regions. The company has incurred high charges for this data
sharing belonging to transfer charges. The Finance Team is looking for an option to minimize these
charges.
What solution can be designed to minimize this cost?
A.
Configure Amazon CloudFront in front of the Amazon S3 bucket to share data from the nearest edge
locations
B.
Configure the Requester Pays option on the Amazon S3 bucket
C.
Share pre-signed URLs with the users to access data from the Amazon S3 bucket
D.
Replicate data to Amazon S3 buckets in all the regions to enable users to download data from local
Amazon S3 buckets
Correct Answer: B
Configure the Requester Pays: This option shifts the data transfer costs to the users who are
accessing the data. This way, the company can avoid incurring high data transfer charges, as the
users will be responsible for these costs.
A. Configure Amazon CloudFront: While CloudFront can reduce latency by caching content at edge
locations, it doesn't necessarily minimize data transfer costs for cross-region access. It might
even add additional costs for CloudFront usage
C. Pre-signed URLs: Pre-signed URLs can be used to grant temporary access to specific objects in S3,
but they don't directly reduce transfer charges.
D. Replicating Data: Replicating data to multiple S3 buckets can be expensive and complex to manage.
It also doesn't guarantee that users will always access data from the closest region.
Question 42
You are tasked with designing a solution for a media company that requires live streaming and
real-time analysis of video content for audience engagement and quality monitoring. Which AWS
service would you recommend for securely ingest, process, and analyze video streams from various
sources, including mobile devices and webcams?
A.
Deploy Amazon Kinesis Video Streams for securely ingesting, processing, and analyzing live video
streams at scale
B.
Use Amazon Kinesis Firehose to load streaming data into AWS for near real-time analytics and
securely deliver it to various destinations, suitable for video streams
C.
Utilize AWS IoT Greengrass to securely ingest video streams from various sources at the edge of the
network with reduced latency
D.
Implement Amazon Kinesis Data Streams for a scalable and durable platform of streaming video streams
Correct Answer: A
In this scenario, where the requirement involves securely ingesting, processing, and analyzing live
video streams from various sources for audience engagement and quality monitoring, Amazon Kinesis
Video Streams is the most appropriate AWS service. It is specifically designed for handling live
video streams at scale, providing features like automatic scaling, data retention policies, and
integration with other AWS services for real-time analytics and processing. Therefore, - Option A is
the correct choice.
- Option B is incorrect because Amazon Kinesis Firehose is designed for streaming data delivery to
various destinations, making it less suitable for real-time analysis and processing of video
streams.
- Option C is incorrect because AWS IoT Greengrass extends IoT functionality to edge devices,
allowing
them to securely interact with cloud services, run local computations, and operate even when
they're
not connected to the internet. It is not optimized for handling video streams and performing
real-time analysis of video content.
- Option D is incorrect because Amazon Kinesis Data Streams is a general-purpose data streaming
service, not specialized for video stream processing and analysis
Question 43
An IT firm is planning to store all its critical project-related documents in an Amazon S3 bucket.
All these files should be encrypted at rest. As per security guidelines, firms need to manage the
encryption process internally, but keys used for the encryption should not be stored locally.
How can encryption solutions be designed to meet the data encryption guidelines?
A.
Use a key stored within the application for client-side encryption while uploading/downloading data
from the Amazon S3 bucket
B.
Use an AWS KMS key for client-side encryption while uploading/downloading data from the Amazon S3
bucket
C.
Use a customer-provided key for client-side encryption while uploading/downloading data from the
Amazon S3 bucket
D.
Use an Amazon S3 bucket key for client-side encryption while uploading/downloading data from the
Amazon S3 bucket
Correct Answer: B
Client-side encryption is selected when customers need to manage the encryption process, keys, and
tools themselves. With client-side encryption, Amazon S3 is not involved in the encryption process.
Data is encrypted locally before it’s saved to the Amazon S3 bucket and decrypted after it's
downloaded from the S3 bucket.
There are the following two options with client-side encryption,
Using AWS KMS: For encryption of data locally, AWS KMS keys are used by the customers. In this
option, an encryption key is stored in AWS KMS.
Using keys stored within the application: In this case, data is encrypted locally before saving to
the Amazon S3 bucket using the root key in the application. In this case, encryption keys need to be
managed by the customers. If keys are lost, decryption of data downloaded from the Amazon S3 bucket
is impossible.
- Option A is incorrect. While using keys stored within the application, encryption keys need to be
managed by the client. These keys need to be managed locally by the customer. If these keys are
lost, decryption of data downloaded from the Amazon S3 bucket is impossible.
- Option C is incorrect as customer-provided keys are used with server-side encryption, not for
client-side encryption.
- Option D is incorrect as the Amazon S3 bucket key is used while configuring server-side encryption
using SSE-KMS. Bucket keys reduce request traffic from the S3 bucket to Amazon KMS and in turn,
minimize the cost of using SSE-KMS. This cannot be used along with client-side encryption.
Question 44
A company has recently installed multiple software applications on an Amazon EC2 instance for its
new web application. Recently, an incident caused a major outage for this web application, and the
root cause was identified as network ports being unintentionally open and subsequently exploited.
The Security Team is seeking a detailed report on the Amazon EC2 instance that gathers information
on all network ports that are open unintentionally and not in use for any service. The solution
should provide a list to help remediate these findings based on their criticality.
Which of the following approaches can be initiated to obtain the required reports?
A.
Implement Amazon Inspector on the Amazon EC2 instance
B.
Implement Amazon GuardDuty on the Amazon EC2 instance
C.
Implement Amazon Detective on Amazon EC2 instance
D.
Implement AWS Artifact on Amazon EC2 instance
Correct Answer: A
Amazon Inspector is a vulnerability management service that can identify software vulnerabilities
and network exposure. It can be initiated on the Amazon EC2 instance and Amazon ECR (Elastic
Container Registry). For each of the findings, Amazon Inspector calculates a risk score by
correlating CVE (common vulnerability and exposures) along with network access and exploitability.
This score can help prioritize remediations on each of the instances.
In the above case, Amazon Inspector can be enabled on the Amazon EC2 instance which will find
network ports opened unintentionally. Amazon Inspector will assign a risk score for each finding
which will help remediate critical findings first.
- Option B is incorrect as Amazon GuardDuty is a threat detection service that can be used to
monitor
AWS accounts and workloads by analyzing AWS data sources, including AWS CloudTrail event logs,
Amazon VPC flow Logs, and DNS query logs. It is not an ideal tool for vulnerability management on
Amazon EC2 instances.
- Option C is incorrect as Amazon Detective investigates data from various Amazon security services
such as Amazon GuardDuty, Amazon Macie, and AWS Security Hub along with partner security tools to
identify the root cause of the security issues and findings.
- Option D is incorrect as AWS Artifact can be used to get compliance reports for AWS resources from
a
single portal. It is not an ideal tool for vulnerability management on Amazon EC2
instances.
Question 45
In your AWS account, you have configured three Application Load Balancers to route the traffic, and
each ALB has its own target group. As the traffic keeps growing, the cost of the Elastic Load
Balancers increases as well. Which method would you take to reduce the load balancer cost?
A.
Configure the Application Load Balancers as the spot ones.
B.
Use one ALB instead of three. Attach all three target groups in the ALB.
C.
Move the Application Load Balancers to the US East (N.Virginia) region.
D.
Install an ACM certificate in each Application Load Balancer.
Correct Answer – B
- Option A is incorrect: Because Application Load Balancers do not have the spot type.
- Option B is CORRECT: Because users are charged for the time, the Application Load Balancers are
running. The cost will be reduced if only one ALB is used.
- Option C is incorrect: Because this method is not applicable if the application cannot be moved to
another region. ALB may not be cheaper in the US East (N.Virginia) region too.
- Option D is incorrect: Because installing a certificate does not help to reduce the cost.
Question 46
An engineering firm uses Amazon CloudTrail to record user activities across multiple accounts. Log
files for this CloudTrail are stored in the Amazon S3 bucket in the us-east-1 region. Keys used for
encrypting these logs should be managed by the Security team in this firm. Only specific users in
the team should have permission to use this key for encrypting and decrypting log files. You have
been assigned to work on this solution to suggest an efficient solution for additional security to
log files from multiple accounts.
Which of the following solutions can you propose?
A.
Use Server-side encryption with Amazon S3-managed encryption keys (SSE-S3) for CloudTrail log files.
Use different keys for encrypting and decrypting log files for multiple accounts across different
regions
B.
Use Server-side encryption with AWS KMS-managed keys (SSE-KMS) for CloudTrail log files. Create a
KMS key in the same region as the S3 bucket storing the log files. Use the same key for encrypting
and decrypting log files for multiple accounts across different regions
C.
Use Server-side encryption with Amazon S3-managed encryption keys (SSE-S3) for CloudTrail log files.
Use the same keys for encrypting and decrypting log files for multiple accounts across different
regions
D.
Use Server-side encryption with AWS KMS-managed keys (SSE-KMS) for CloudTrail log files. Create a
KMS key in a different region than the S3 bucket storing the log files. Use the different keys for
encrypting and decrypting log files for multiple accounts across different regions
Correct Answer: B
Amazon CloudTrail Log files can be encrypted in any of the two ways,
SSE-KMS allows you to manage encryption keys with AWS Key Management Service (KMS) for added
security.
The KMS key should be created in the same region as the Amazon S3 bucket storing the CloudTrail logs
for encryption and decryption.
Using the same key for multiple accounts simplifies key management and secures the logs consistently
across accounts, which aligns with the requirements of the Security team to manage keys and control
access.
A single key can be used for encrypting and decrypting log files for multiple accounts. With Amazon
KMS-managed encryption keys (SSE-KMS), the KMS key should be created in the same region as that of
the Amazon S3 bucket which is used to store Amazon CloudTrail logs.
Options A and C are incorrect as AWS manages keys, and customers do not manage these keys with
Amazon S3-managed encryption keys. Also, customers cannot control permissions for using these
keys.
- Option D is incorrect as the KMS key should be created in the same region as the Amazon S3 bucket
to
provide encryption or decryption.
Question 47
An online educational platform is developing a web application that will serve millions of students
accessing educational content. The platform plans to use Amazon EC2 instances for compute services
and requires a high-performance shared storage solution that can handle parallel access. The storage
system should support a high throughput of up to 21 GB/s for each user session accessing the file
system.
Which file system can be selected to meet performance requirements?
A.
FSx for NetApp ONTAP
B.
FSx for Lustre
C.
FSx for Windows File Server
D.
FSx for OpenZFS
Correct Answer: B
Option A: FSx for NetApp ONTAP offers a maximum throughput of 3 GB/s per client, which does not meet
the requirement.
Option B: FSx for Lustre provides a maximum throughput of up to 21 GB/s per client, making it
suitable for the requirement of up to 21 GB/s for each user session.
Option C: FSx for Windows File Server has a maximum throughput of 3 GB/s per client, which is
insufficient.
Option D: FSx for OpenZFS offers a maximum throughput of 12.5 GB/s per client, also not meeting the
requirements.
Given the performance requirements, FSx for Lustre is the most suitable file system for this
scenario.
Question 48
A web application is hosted in AWS EC2 and serves global customers. As the application is getting
more and more popular, the data transfer cost keeps increasing. You plan to use AWS CloudFront to
improve the latency and reduce the cost. Which of the following services is free for CloudFront?
A.
Data transfer out to the Internet from edge locations.
B.
Data transfer out of Amazon CloudFront to the origin server.
C.
Data transfer from origin to CloudFront edge locations (Amazon CloudFront “origin fetches”).
D.
Custom SSL certificate associated with the CloudFront distribution using the Dedicated IP version of
custom SSL certificate support.
Correct Answer – C
CloudFront is a content delivery network (CDN) service that offers a simple, pay-as-you-go pricing
model. For the Amazon CloudFront pricing details, please check the below reference.
Options A and B are incorrect: Because the data transfer out to the internet or origin is not free.
A different rate is charged depending on the region.
- Option C is CORRECT: If the CloudFront origin is hosted in AWS like EC2, the origin fetches are
free.
- Option D is incorrect: Because for each custom SSL certificate associated with one or more
CloudFront distributions using the Dedicated IP version of custom SSL certificate support, you are
charged at $600 per month.
Question 49
A large manufacturing company is looking to track IoT sensor data collected from thousands of
equipment across multiple factory units. This is extremely high-volume traffic that needs to be
collected in real time and should be efficiently visualized. The company is looking for a suitable
database in the AWS cloud for storing these sensor data.
Which of the following cost-effective databases can be selected for this purpose?
A.
Send sensor data to Amazon RDS (Relational Database Service) using Amazon Kinesis and visualize data
using Amazon QuickSight
B.
Send sensor data to Amazon Neptune using Amazon Kinesis and visualize data using Amazon QuickSight
C.
Send sensor data to Amazon DynamoDB using Amazon Kinesis and visualize data using Amazon QuickSight
D.
Send sensor data to Amazon Timestream using Amazon Kinesis and visualize data using Amazon
QuickSight
Correct Answer: D
Amazon Timestream is the most suitable serverless time series database for IoT and operational
services. It can store trillions of events from these sources. Storing this time series data in
Amazon Timestream ensures faster processing and is more cost-effective than storing such data in a
regular relational database.
Amazon Timestream is integrated with data collection services in AWS such as Amazon Kinesis, and
Amazon MSK, and open-source tools such as Telegraf. Data stored in Amazon Timestream can be further
visualized using Amazon QuickSight. It can also be integrated with Amazon Sagemaker for machine
learning.
- Option A is incorrect as Amazon RDS (Relational Database Service) is best suited for traditional
applications such as CRM (customer relationship management) and ERP (Enterprise resource
planning).
Using Amazon RDS for storing IoT sensor data will be costly and slow as compared to the Amazon
Timestream.
- Option B is incorrect as Amazon Neptune is suitable for creating graph databases querying large
amounts of data. Amazon Neptune is not a suitable option for storing IoT sensor data.
- Option C is incorrect as Amazon DynamoDB is suitable for web applications supporting key-value
NoSQL
databases. Using Amazon DynamoDB for storing IoT sensor data will be costly.
Question 50
A start-up firm is using a JSON-based database for content management. They are planning to rehost
this database to AWS Cloud from on-premises. For this, they are looking for a suitable option to
deploy this database, which can handle millions of requests per second with low latency. Databases
should have a flexible schema that can store any type of user data from multiple sources and should
effectively process similar data stored in different formats.
Which of the following databases can be selected to meet the requirements?
A.
Use Amazon DocumentDB (with MongoDB compatibility) in the AWS cloud to rehost the database from an
on-premises location
B.
Use Amazon Neptune in the AWS cloud to rehost the database from an on-premises location
C.
Use Amazon Timestream in AWS cloud to rehost database from an on-premises location
D.
Use Amazon Keyspaces in AWS cloud to rehost database from an on-premises location
Correct Answer: A
Amazon DocumentDB is a fully managed database that supports JSON workloads for content management in
the AWS cloud. Amazon DocumentDB supports millions of requests per second with low latency. Amazon
DocumentDB has a flexible schema that can store data in different attributes and data values. Due to
the flexible schema, it's best suited for content management which allows users to store different
data types such as images, videos, and comments.
With relational databases, for storing different documents, separate tables are required to store
different types of documents or need a single table with unused fields as null values. Amazon
DocumentDB is a semi-structured database that supports different formats of the documents in the
same document without null values.
- Option B is incorrect as Amazon Neptune is suitable for creating graph databases querying large
amounts of data. It is not a suitable option for content management with different data
formats.
- Option C is incorrect as Amazon Timestream is suitable for time series databases such as IoT base
sensor data, DevOps, or clickstream data. It is not a suitable option for content management with
different data formats.
- Option D is incorrect as Amazon Keyspaces is a highly available and scalable database supporting
Apache Cassandra. It is not a suitable option for content management with different data
formats.
Question 51
James attempts to launch a t2.micro EC2 instance using the AmazonEC2FullAccess policy. He selects
the Amazon Linux 2 AMI and chooses not to associate a key pair. For the root volume, he configures
an 8 GB General Purpose (gp2) EBS volume and manually encrypts it using a specific KMS key. After
reviewing the configurations, he proceeds to launch the instance.
However, the instance transitions from “Pending” to “Shutting Down” and then to “Terminated” without
reaching the “Running” state. The error message indicates: Client.InternalError: Client error on
launch.
What is the most likely cause of this issue, and how can it be resolved?
A.
The EBS Volume is encrypted with a KMS key which James has no permission for decryption. The admin
should give him permission to access KMS Key
B.
The mentioned policy applies to only certain instance types. James should try launching the EC2
instance with another type than t2.micro
C.
James has created the instance without a key pair. He should launch the instance again by using a
key pair
D.
The EBS Volume limits in his account have been exceeded. He needs to submit a request to AWS to
increase the limit
Correct Answer: A
- Option A is CORRECT. The error Client.InternalError: Client error on launch indicates various
issues
with the EBS Volumes. In this case, it is due to the lack of permissions to access KMS Keys to
encrypt or decrypt the EBS Volumes. Since James has only the AmazonEC2FullAccess policy, it
doesn’t
include the required permissions for AWS KMS. That’s why James needs to have the permissions
required to access the AWS KMS keys used to decrypt and encrypt volumes in order to resolve the
issue of instance terminating immediately.
- Option B is incorrect because the AmazonEC2FullAccess policy provides full access to Amazon EC2.
This policy is NOT limited to certain instance types. A user with this policy permissions can
launch
an EC2 instance of any type. So this is not a valid reason for the error mentioned in the
question.
- Option C is incorrect because there is no problem in proceeding without a key pair. It totally
depends on a user’s requirement if he needs the key pair or not. You need to use a key pair when
you
want to connect it to your EC2 instance using SSH. When you are planning to connect to your
instance
using the console through the Instance Connect option, then you can proceed without a key pair
also.
- Option D is incorrect. Although exceeding the EBS volume limit is one of the valid reasons for the
instance to go into a terminated state immediately, the error Client.InternalError: Client error
on
launch indicates various issues with the EBS Volumes. In this case, it is due to the lack of
permissions to access KMS Keys to encrypt or decrypt the EBS Volumes.
Question 52
You are designing an architecture for one of your client’s applications. You created a VPC within
the us-east-1 region consisting of two public subnets and a private subnet. The first public subnet
contains a web server. All the other VPC Networking components are also set including Internet
gateway, route tables, security groups, etc. Your team lead reviewed the architecture and informed
you about the client’s requirement to make the current architecture highly available with MINIMAL
COST. He also specified that the client could accept a minor downtime, but the cost is the priority
here.
Which options can make your current architecture highly available with minimum effort and costs?
A.
Span the architecture components to a second Availability zone by creating similar resources in it
as AZ-1 and then distributing the traffic using an application load balancer
B.
Create a standby instance in the second public subnet. Attach a secondary ENI to the instance in the
first public subnet. In case of a failure, detach this ENI and attach it to the standby instance
C.
Span the architecture components to a second region by creating similar resources in it as available
in US-East-1 and then distributing the traffic using an application load balancer
D.
Implement dynamic scaling in this architecture by using Cloudwatch, Elastic Load Balancing, and Auto
Scaling together. This solution will bring automated scaling and high availability with zero
downtime
Correct Answer: B
- Option A is incorrect because having the resources in the second Availability zone and then using
load balancers will almost double the overall cost. It is mentioned that cost should be kept to a
minimum, and the efforts also should be minimal. Due to these reasons, this option can be
eliminated.
- Option B is CORRECT. Creating a secondary ENI, and using it in case of instance failure by
attaching
it with a standby instance is the most cost-effective solution out of the four given options.
Also,
this solution doesn’t require much effort to set up. Thus, it can satisfy the requirement of
building high availability in the architecture with a low cost and less effort.
- Option C is incorrect because having the same resources in the second region will almost double
the
overall cost. Also, you can’t use an application load balancer to distribute the traffic across
regions. It can distribute the traffic across Availability zones only. Since it is mentioned that
cost should be kept to a minimum and the efforts also should be minimal, this option can be
eliminated.
- Option D is incorrect. Although implementing dynamic scaling using the mentioned services will
achieve high availability with zero downtime, it will increase the cost. And it is explicitly
mentioned that the client can accept some downtime, but the cost should be minimal. That’s why
this
option can be eliminated.
Question 53
You have launched an EC2 instance with a General Purpose EBS Volume of 16384 GB as its root volume (
/dev/xvda). After working on it for some time, you observed the need to have more storage with this
instance. You found a volume (/dev/xvdf1) available in your account. Therefore this volume is
attached as an additional volume with your EC2 instance.
One of your teammates informed you that this volume (/dev/xvdf1) was created from the snapshot of
the root volume of another instance. Later on, upon rebooting the instance, you connect to it and
observe that the instance has booted from /dev/xvdf1, whereas it was supposed to boot from
/dev/xvda (original root volume). What should you do now to resolve the problem and let the instance
boot from the correct volume?
A.
Keep the additional volume in an Availability zone other than the one where the EC2 instance and its
root volume reside, then attach it to the EC2 instance
B.
Change the label of the additional volume using the e2label command
C.
Unmount the additional volume and add more storage capacity to the existing General Purpose volume
only
D.
Change the label of the additional volume using the e2changelabel command
Correct Answer: B
- Option A is incorrect. This is not a valid solution because an EBS Volume needs to be present in
the
same Availability zone as the EC2 Instance with which you want to attach the volume. That’s why
this
option can be eliminated.
- Option B is CORRECT. The instance is booting from the wrong volume because the additional volume
that you have used with your instance was created from the root volume of another volume. This can
lead to the wrong selection of volume during the instance boot. To solve this issue, you can use
the
e2label command to change the label of the attached volume that you do not want to boot
from.
- Option C is incorrect. The maximum storage capacity of a General Purpose EBS Volume is 16384 GB (
16
TB). The questions specify that you have already provisioned this capacity to your volume during
the
instance creation. This means you can’t provision any more capacity to the volume. You need to
attach an additional volume with your EC2 instance for more storage.
- Option D is incorrect. Although changing the label of the additional volume is the correct
solution,
the command mentioned in this option is incorrect. You will be able to change the label using the
e2label command only.
Question 54
You are working as a solutions architect in an E-Commerce based company with users from around the
globe. There was feedback coming from various users of different countries to have the website
content in their local languages. So, the company has now translated the website into multiple
languages and is rolling out the feature soon for its users.
Now you need to send the traffic based on the location of the user. For example, if a request comes
from Japan, it should be routed to the server in the ap-northeast-1 (Tokyo) region where the
application is in the Japanese language. You can do so by specifying the IP address of that
particular server while configuring the records in Route 53. Which one of the following routing
policies should you use in Amazon Route 53 that will fulfill the given requirement?
A.
Weighted Routing Policy
B.
Geoproximity Routing Policy
C.
Geolocation Routing Policy
D.
Multivalue Answer Routing Policy
Correct Answer: C
- Option A is incorrect. A Weighted Routing Policy is used when you have a requirement to specify
the
percentages of traffic to be routed to the underlying servers. For example, 10% traffic to Test
Server A, 10% Traffic to Test Server B, and 80% Traffic to the Production server.
- Option B is incorrect. If the requirement was to route the user request based on the location of
the
users as well as the servers, then you could use the Geoproximity routing policy. For example, you
may want the user’s request should be routed to the resources present at the least distance from
the
user. Also, in this policy, You can optionally choose to route more traffic or less to a given
resource by specifying a value, known as a bias. A bias will let you shrink or expand the size of
a
geographic region from which traffic is routed to a resource. So let’s say there are 4 or 5 cities
whose traffic you want to route to resources in 1 region and then another few cities whose
requests
you want to be routed to the resources in 2nd region.
- Option C is CORRECT. In the Geolocation policy, though the resources might be present close to the
user, the request wants to go to another resource which is quite far. This happens because we want
the user’s request from a location to be routed to a specific server or set of servers only where
the correctly translated website was hosted.
- Option D is incorrect. Multivalue answer routing is used when you want to route the DNS queries
randomly to the underlying servers. It will consider up to 8 healthy servers, and the request will
be routed to any of them randomly. In this question, the requirement is for routing the DNS
queries
to a specific server which is why this option can be eliminated.
Question 55
You are working as a solutions architect in a team who is handling the infrastructure provisioning,
scaling, load balancing and monitoring, etc for a workload. This workload is hosted on a fleet of
Linux servers on-premises. You have been assigned a task to capture the application logs, percentage
of total disk space that is used, the amount of memory currently in use, and the percentage of time
that the CPU is idle from the Linux servers.
Using this data, your team is going to build an operational dashboard. This dashboard will help set
high-resolution alarms to alert and take automated actions and understand the service and
application health easily. Which one of the following options is the best solution to satisfy this
requirement?
A.
Use Amazon Cloudtrail standard metrics and logs to collect the required metrics and application logs
B.
Use Amazon Cloudtrail unified agent to collect the required metrics and application logs
C.
Use Amazon Cloudwatch Standard metrics and logs to collect the required metrics and application logs
D.
Use Amazon Cloudwatch unified agent to collect the required metrics and application logs
Correct Answer: D
Options A and B are incorrect because both of them mention the use of AWS Cloudtrail. We can use
Cloudtrail mostly when we want to record the API calls happening in our AWS Account. To monitor the
performance and utilization of resources and applications, Amazon Cloudwatch is used.
- Option C is incorrect. Although using Amazon Cloudwatch is the right choice, the standard metrics
in
Cloudwatch cannot collect the ones mentioned in the question. To monitor the application logs and
metrics like the percentage of total disk space that is used, the amount of memory currently in
use,
the percentage of time that the CPU is idle, etc. you need to capture Custom Metrics. This can be
done using Cloudwatch Unified Agent.
- Option D is CORRECT. The metrics mentioned in the question are not readily available in
Cloudwatch.
Using Cloudwatch unified agent on your on-premises servers, you can monitor the required Custom
metrics and the application logs. You will need to capture disk_used_percent, mem_used_percent,
and
cpu_usage_idle metrics using Cloudwatch Unified Agent.
Question 56
You are an IAM User in Account A and have created a Lambda function. One of the members of the
Testing team, who is an IAM User in Account B, needs to perform some test cases and keep the code in
his local system for record purposes. For the same, he needs to invoke your Lambda function in his
account and should be able to download the code as well. Also, you need to make sure that the User
of Account B can still perform his normal operations along with this lambda invocation requirement.
Which options will allow User B to perform the required actions in his account with minimal effort?
A.
Use a Resource-based policy with your lambda function and grant permissions using lambda:*
B.
Create an IAM Role in Account A so that User B can assume this role and perform the required actions
C.
Use a Resource-based policy with your lambda function and grant permissions using lambda:
InvokeFunction and lambda:GetFunction
D.
Create an IAM User for User B in Account A so that he can log in and perform the required actions
Correct Answer: C
You can use resource-based policies with Lambda functions to grant access to other AWS Accounts to
perform actions on a Lambda function in your account.
- Option A is incorrect. Although assigning a resource policy on your Lambda Function will give User
B
the required permissions, as per the Least Privilege Principle, we have always to assign only the
least required permissions. lambda:* will give the permission to perform all the actions, whereas
User B just needs permission for two actions. That’s why this option can be eliminated.
- Option B is incorrect. Although this is also a possible solution, it doesn’t fully satisfy the
requirement mentioned in the question. When User B will assume a role in your account, he will be
able to access the lambda function. But his normal permissions will be forgotten as long as he has
assumed the role. It is explicitly mentioned in the question that User B should be able to perform
his normal operations as well along with the required actions on Lambda. Also, this method will
require more effort as compared to resource-based policies.
- Option C is CORRECT. Using a resource-based policy with the appropriate permissions for only
required actions is the best choice here. Also, this method doesn’t need much effort as compared
to
granting access through the IAM role. lambda:InvokeFunction will let user B invoke the Lambda
Function and lambda:GetFunction will let user B download the function code.
- Option D is incorrect because creating an IAM User is unnecessary here. It is mentioned in the
question that User B needs to run the function in his Account B. If you create one more IAM user
in
Account B, that user will have to login into Account A and perform the required actions there.
This
is opposite to what’s mentioned in the requirement. That’s why this option can be
eliminated.
Question 57
You have designed an architecture for a highly available web application with a dynamic workload.
This architecture consists of a set of EC2 instances managed by an Auto Scaling Group and a load
balancer for the even distribution of traffic. Your manager has reviewed the functioning of this
architecture and is concerned about the latency of the scaling out process. Whenever there is a need
to scale out, it takes a few seconds to a few minutes for Auto Scaling to launch the instance,
register it with the load balancer, and start serving the requests. The Manager has asked you to
look for a way to reduce this latency so that instances can start serving the requests as quickly as
possible. Which of the following options can satisfy the given requirement?
A.
Use Warm Pool with Auto Scaling
B.
Use the Desired capacity parameter to scale out quickly
C.
Use Lifecycle hooks with Auto Scaling
D.
Use the Scheduled scaling type to scale out quickly
Correct Answer: A
- Option A is CORRECT. Auto Scaling Warm Pool is a collection of pre-initialized EC2 Instances
sitting
along with your Auto Scaling Group. So, when there’s a need to Scale Out, Auto Scaling will pick
one
of the instances from the Warm Pool, and that instance will immediately start serving the
requests.
This will eventually reduce the latency involved because of the time taken by a new instance to
launch.
- Option B is incorrect. Desired Capacity is just a way to scale out or scale in manually. You
specify
a number in the desired capacity, and that number of EC2 instances will start to launch in your
Auto
Scaling Group immediately. This will have the latency for the time when the instance is launching.
That’s why this option can be eliminated.
- Option C is incorrect. Lifecycle hooks are used when you want your newly launched instances to
wait
and perform some custom actions on them before they start serving the requests. This won’t satisfy
the given requirement of reducing latency and letting the instances serve the requests
quickly.
- Option D is incorrect. Setting up Scheduled Scaling is not a good choice for the given scenario.
It
is mentioned in the question that the workload is dynamic which means there can be the need to
scale
out or scale in at any time. You can use Scheduled Scaling for the cases of predictable workloads
where you know exactly when there is a need to scale out or scale in.
Question 58
Your application is deployed in EC2 instances and uses CloudFront to deliver the content. In order
to reduce the cost of requests to the origin, you plan to increase the cache duration in CloudFront
for certain dynamic contents. Which of the following options is the most appropriate to achieve the
requirement?
A.
Modify the application to add a Cache-Control header to control how long the objects stay in the
CloudFront cache.
B.
In the CloudFront distribution, enlarge the default TTL in the object caching setting
C.
Specify the minimum TTL to be 0 in the CloudFront object caching setting.
D.
Add a Cache-Control header by configuring the metadata of the S3 objects
Correct Answer – A
- Option A is CORRECT: Because the Cache-Control header added by the origin server can be used to
control the caching behavior in CloudFront. The application is responsible for adding the header
for
individual objects.
- Option B is incorrect: Because the default TTL impacts all objects if the origin does not add the
cache header. However, in the question, only certain dynamic contents need to be modified.
- Option C is incorrect: Because the cache duration is not increased by setting the value of Minimum
TTL to be 0. Please check the below reference on how to determine the amount of time that
CloudFront
keeps an object in the cache.
- Option D is incorrect: The question mentions that the cache duration of dynamic contents needs to
be
increased. However, S3 objects belong to static contents.
Question 59
You use CloudFormation to create an Auto Scaling group for a web application. The application needs
to be deployed in both non-production and production AWS accounts. You want to use Spot Instances in
the non-production environment to save costs. Which of the following methods would you choose?
A.
In the CloudFormation template, use a variable to set the OnDemandPercentageAboveBaseCapacity
property. Set the variable to be 100 in non-production and 0 in production.
B.
In the CloudFormation template, use a parameter to set the OnDemandPercentageAboveBaseCapacity
property. Set the parameter to be 0 in non-production and 100 in production.
C.
In the CloudFormation template, use a parameter for the SpotMaxPrice property. Set the parameter to
be 100 in non-production and 0 in production.
D.
. In the CloudFormation template, use a parameter for the SpotMaxPrice property. Set the parameter
to be 0.5 in non-production and the On-Demand price in production.
Correct Answer – B
- Option A is incorrect: Because OnDemandPercentageAboveBaseCapacity determines the percentages of
On-Demand Instances and Spot Instances beyond OnDemandBaseCapacity. The value should be 100 in
production as no Spot Instances should be used in production.
- Option B is CORRECT: As the value of OnDemandPercentageAboveBaseCapacity is 0 in non-production,
Spot Instances will be used. For the production environment, On-Demand Instances are launched as
OnDemandPercentageAboveBaseCapacity is 100.
- Option C is incorrect: SpotMaxPrice determines the maximum price that you are willing to pay for
Spot Instances. It does not decide the percentage between Spot and On-Demand instances.
- Option D is incorrect: In this scenario, OnDemandPercentageAboveBaseCapacity should be configured
to
launch Spot Instances in non-production and On-Demand Instances in production.
Question 60
You have built a serverless architecture composed of Lambda Functions exposed through API Gateway
for one of your client’s applications. For the database layer, you have used DynamoDB. Your team
lead has reviewed the architecture and is concerned about the cost of numerous API Calls being made
to the backend (Lambda Functions) for so many similar requests. Also, the client is concerned about
providing as low latency as possible for the application users’ requests. You have to look for a
solution where the latency and overall cost can be reduced for the current architecture without much
effort.
A.
Cache the computed request’s responses using the CloudFront CDN caching
B.
Use the API Gateway QuickResponse feature to reduce the latency and number of calls to the backend
C.
Enable API Gateway Caching to cache the computed request’s responses
D.
Adjust API Gateway Throttling settings to reduce the latency and number of calls to the backend
Correct Answer: C
- Option A is incorrect. Cloudfront CDN caching is mainly used for caching the responses to limited
HTTP requests. API Gateway can cache the responses to requests of any type. Also, configuring
Cloudfront CDN would be an added effort. You have to select a solution with minimal effort.
Therefore, this option can be eliminated.
- Option B is incorrect because there is no feature like API Gateway QuickResponse. This option is
just a distractor and thus, can be eliminated.
- Option C is CORRECT. When you enable caching on API Gateway, it caches the responses of the
requests
processed by the backend. When a similar request comes, it will serve it quickly from the API
Gateway Cache itself instead of passing the call to the backend. This will reduce the number of
calls made to the backend, eventually reducing the overall cost. Also, this will help in reducing
the latency of the responses sent to the user.
- Option D is incorrect. Throttling is used to limit the number of requests that can pass through
API
Gateway at a time. It is configured in API Gateway to protect your APIs from being overwhelmed by
many requests at a time. This won’t satisfy the requirement of reducing the latency. Hence, this
option can be eliminated.
Question 61
You have designed a gaming application with game servers hosted on EC2 Instances. For the
leaderboards, you have used a DynamoDB table named Scores. Your manager has instructed you to build
a feature to publish a Congratulations and Rewards Message with the winner’s name on the app’s
Social Media network. This message should be posted each time the HighestScore Attribute is updated
in the Scores DynamoDB table. Which of the following options can satisfy the requirement in the BEST
way?
A.
DynamoDB Streams with AWS Lambda
B.
DynamoDB Global Tables with AWS Lambda
C.
DynamoDB Accelerator with AWS Lambda
D.
DynamoDB Transactions with AWS Lambda
Correct Answer: A
- Option A is CORRECT. In the question, it is mentioned that a feature is needed where an action
will
be performed automatically in response to an event (HighestScore Update) in the Scores DynamoDB
Table. DynamoDB Streams capture the changes happening in your DynamoDB Table. You just have to
create a lambda function that will capture the updates from DynamoDB Streams and invoke the code
to
post the winner-related message on social media. This will satisfy the given requirement.
- Option B is incorrect. DynamoDB Global tables are useful when you want to have a multi-master,
multi-region database without building a replication solution manually. In the current scenario,
we
need a solution to automate action in response to an event in the DynamoDB table. So, this option
can be eliminated.
- Option C is incorrect. DynamoDB Accelerator (DAX) is useful when you need an in-memory caching
solution with your DynamoDB Table. It will provide the response time in microseconds. It can’t
satisfy the given requirement. Hence it can be eliminated.
- Option D is incorrect. DynamoDB Transaction is a feature used primarily when you want to
accomplish
ACID Properties in your DynamoDB Table to maintain the correctness of data in your applications.
This feature can’t satisfy the given requirement and hence can be eliminated.
Question 62
You are working in an organization who is using a Multi-Cloud environment. They have workloads
deployed and data stored in Google cloud, Microsoft Azure, and AWS Cloud as well. Your manager has
informed you about the decision to migrate one of the workloads from Google Cloud to AWS. For the
same, he has asked you to migrate all the data stored in Google cloud storage buckets to Amazon S3
buckets without much effort. Which of the following services can help in accomplishing this task?
A.
AWS Migration Hub
B.
Amazon Storage Gateway
C.
AWS DataSync
D.
S3 Transfer Acceleration
Correct Answer: C
- Option A is incorrect because AWS Migration Hub comes into the picture when you are planning to
migrate your application workloads from on-premises to AWS. In the question, we need a solution to
migrate the object storage data from Google Cloud to Amazon S3 Bucket, which can't be satisfied
using AWS Migration Hub. That's why we can eliminate this option.
- Option B is incorrect. Amazon Storage Gateway is used for hybrid storage requirements. This
service
is used when you want on-premises access to the storage on AWS. It is not useful for transferring
the data from one cloud provider to another cloud provider.
- Option C is CORRECT. As per the documentation, “AWS DataSync is an online data transfer service
that
simplifies, automates, and accelerates moving data between storage systems and services.” All you
need to do is create a DataSync agent, which is required to initiate the data transfer. DataSync
agent is nothing but a Virtual Machine that will facilitate the data migration process. Then you
can
use the DataSync agent to migrate the data from Google cloud storage to Amazon S3 Bucket without
writing any code or much effort.
- Option D is incorrect. S3 Transfer Acceleration is used when you have large data to be sent to
Amazon S3 buckets globally at a faster speed. It will integrate with Amazon CloudFront to speed up
the data transfer. But AWS DataSync is a perfect choice for the given requirement.
Question 63
Jackson handles the capacity provisioning for an E-Commerce application’s workload. A sale is
starting in the coming week, and the team has predicted a huge traffic spike during the sale days.
Jackson has provisioned 5 t2.large Reserved Instances for the consistent portion of the workload. As
per the predictions, there will be huge spikes in traffic which will be temporary.
Jackson is looking for a way to serve this portion of the workload in the MOST cost-effective way
without much effort. Note that the application is already designed to recover from any instance
failures. Which of the following options satisfies the given requirement in the best way?
A.
Use Savings Plans for the spiky traffic
B.
Use Spot Instances for the spiky traffic
C.
Use On-Demand Instances for the spiky traffic
D.
Use Dedicated Hosts for the spiky traffic
Correct Answer: B
- Option A is incorrect. Savings plans are used for workloads with a steady or predictable usage.
You
can commit $/h usage of compute. Accordingly, you will get discounts on your compute prices. They
are not suitable for spiky traffic.
- Option B is CORRECT. Spot Instances in AWS are the unused EC2 instances capacity that AWS provides
you at up to a 90% discounted rate as compared to the on-demand instances.
As per the information in the snippet, you can provision spot instances without much effort which
was another requirement in the question because now you don’t have to bid for the spot instance
prices. When AWS needs the capacity, they take it back from you with a 2-minute prior notice.
However, in this case, it is mentioned that the application is designed to recover from instance
failures. So interruption is not an issue. That’s why Spot instance would be the perfect choice in
this case because it is the cheapest option out of all others.
- Option C is incorrect. On-Demand instances can be useful for spiky traffic, but it is mentioned in
the question that the most cost-effective solution is needed. On-Demand instances are not
cost-effective as compared to the other options mentioned here. Also, since it is mentioned that
the
application can recover from any failures, it means spot instance is the best choice here.
- Option D is incorrect because Dedicated Hosts are used when you need the EC2 instance capacity on
a
physical server dedicated just for your use. There is no such requirement, and moreover, dedicated
hosts are a costly option. You have to select something cost-effective, and hence this option can
be
eliminated.
Question 64
An IT Company is working on the disaster recovery strategy for one of their workloads deployed on
AWS. They have begun with the recovery planning of the storage components. As of now, they have an
EFS File System deployed in us-east-1 being used by hundreds of instances in this region. As a part
of their recovery strategy, they also want the file system to be available in ap-south-1. For the
same, they are looking for a way to bring a copy of this file system to ap-south-1 in the easiest
way possible. Which of the following options can provide the BEST solution in this case?
A.
Use Amazon EFS Replication to accomplish the cross-region replication
B.
Bring the data in an S3 Bucket in us-east-1 and enable cross-region replication to copy the data to
a bucket in ap-south-1
C.
Use AWS DataSync to accomplish the cross-region replication
D.
Use AWS Direct Connect to accomplish the cross-region replication
Correct Answer: A
- Option A is CORRECT. You can use Amazon EFS replication to replicate your EFS file system within
the
same or a different region. This option doesn’t require much effort and can be configured easily
with a few steps. It starts replication within minutes.
- Option B is incorrect because there is no need to copy the EFS data to Amazon S3 for replicating
it
in another region. The required replication can be done very easily using Amazon EFS
Replication.
- Option C is incorrect. While it can transfer data between EFS file systems across regions, it
requires more manual effort and is not as seamless as EFS Replication.
- Option D is incorrect. AWS Direct Connect is used in the cases when you are working on a hybrid
environment with on-premises and cloud included. You want them to be connected through a dedicated
connection. Here we just have the requirement of replicating an EFS File system from one region to
another. Hence this option can be eliminated.
Question 65
Your organization is looking for a standalone Active Directory solution on AWS with certain features
and budget constraints. The first requirement is that the users in this directory should be able to
use their directory credentials to log in to AWS Management Console and manage AWS resources. Also,
there’s a requirement to have daily automated snapshots. The number of users will not exceed 450.
Which one of the following options can provide the required features at the lowest possible cost?
A.
AWS Directory Service for Microsoft AD
B.
Active Directory Connector
C.
Simple Active Directory
D.
Amazon Cognito
Correct Answer: C
- Option A is incorrect. Although AWS Directory Service for Microsoft AD provides all the high-level
features, it is still a costly option as compared to the others mentioned in the options. In this
question, it is mentioned that cost is the utmost priority. So, we can eliminate this option as
this
one would be expensive. It would be preferable when you need actual Microsoft AD on AWS.
- Option B is incorrect. Active Directory Connector is used when you want your on-premises users to
use their existing active directory credentials to use AWS services. However, it is not required
here. That’s why this option can be eliminated.
- Option C is CORRECT. Simple Active Directory will satisfy all the requirements mentioned in the
question. This is a low-cost option as compared to all others mentioned here.
- Option D is incorrect. Amazon Cognito is used when there’s a requirement to build a sign-up or
sign-in facility for your web or mobile applications. It can scale up to millions of users when
needed. However, we have a different requirement that can be satisfied using Simple AD in the
question.