400+ Câu hỏi luyện thi chứng chỉ AWS Certified Solutions Architect Associate (SAA-C03) - Phần 2
aws
aws certification
cloud computing
solutions architect
saa c03
aws exam
practice test
Question 1
An online hypermarket company has deployed a web application using a REST API with Amazon API
Gateway. Recently, they upgraded the backend to make the API scalable. After the upgrade, it was
discovered that some consumers using older methods could no longer access the API, as the older
method is not compatible with the responses from the backend.
How should a solutions architect redesign the API Gateway to ensure compatibility with the old
method?
A.
Enable API caching in Amazon API Gateway
B.
Configure Mapping templates with Amazon API Gateway
C.
Set up Gateway Response customization in OpenAPI
D.
Set up a method response model with Amazon API Gateway
Correct Answer: B
Mapping Templates can be used to transform a request from a frontend data format to the backend data
format or transform a response from a backend to the format supported by the frontend. Mapping
Templates are scripted in Velocity Template Language (VTL).
In the above case, since the response from the upgraded backend node is non-compatible with the
older format, a mapping template can be used with API Gateway to transform the response while
sending it to the non-compatible consumers.
- Option A is incorrect as with enabling API Caching, responses sent by the backend nodes will be
cached to reduce calls made to backend nodes. This will not be useful for transforming the
responses.
- Option C is incorrect as this will help set up a Gateway response to customize error responses
sent
by Amazon API Gateway. This will not be useful for transforming the responses.
- Option D is incorrect as the method response model is used to set up a response format. This will
not be useful for transforming the responses.
Question 2
Which of the following statement defines task definition?
A.
JSON template that describes containers which forms your application.
B.
Template for a program that runs inside AWS ECS Cluster.
C.
AWS managed service that launches ECS clusters.
D.
Template that defines actions for each IAM user on the ECS cluster and its containers.
Answer: A
For more information on how to create task definitions, refer to the documentation here.
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task_definitions.html
- Option B is incorrect as a task definition is not a program template; it defines container
configurations.
- Option C is incorrect ECS itself manages clusters, but this is unrelated to task
definitions.
- Option D is incorrect as it doesn't define IAM user actions but rather container behavior.
Question 3
A large engineering company has created multiple accounts for deploying applications in an AWS
Cloud. Production Account is using Amazon Redshift for data warehousing applications. The Quality
Assurance Team having accounts in the same region needs access to the data in this Amazon Redshift.
Data should be securely shared with specific users in this account for further analysis.
What is the cost-effective and efficient method for sharing Amazon Redshift data between AWS
accounts in the same region?
A.
Use a third-party ETL (extract transform load) tool to copy data from the production accounts and
share it with specific users in Quality assurance accounts
B.
Create a Datashare from the Redshift console and authorize specific accounts to access this
datashare
C.
Extract database from Amazon Redshift and store in Amazon S3. Use this S3 bucket to share the
database with other accounts
D.
Extract database from Amazon Redshift and store in Amazon DynamoDB table. Use the Amazon DynamoDB
table to share the database with other accounts
Correct Answer: B
Amazon Redshift cross-account data sharing provides an efficient and secure way of sharing data in
the Redshift with different accounts. A datashare is a unit of sharing data that can be created for
sharing data in Amazon Redshift with the users in the same or different accounts. It integrates with
AWS IAM which provides a controlled way of sharing data with specific users in different accounts.
For sharing Redshift data between cross-accounts, both the source and destination clusters must be
encrypted and in the same region. AWS CloudTrail can be used to monitor these access
permissions.
- Option A is incorrect as using a third-party ETL tool will incur additional tools and may not
necessarily be a secure option for sharing data between two accounts.
- Option C is incorrect as extracting data in Amazon S3 will require additional admin work and would
not be an efficient way of sharing data.
- Option D is incorrect as using Amazon DynamoDB for sharing databases would incur additional costs
and would not be an efficient way of sharing data.
Question 4
A company is using AWS Organizations for managing multiple accounts created in an AWS cloud. During
the annual audit, it was found that accounts use similar resources which increase cost and admin
work. These resources are created for the same requirements in each account. The IT Head is looking
for a cost-optimized solution for managing these resources across multiple accounts.
What solution can be designed for new resources deployment to minimize costs for resources across
accounts in AWS Organizations?
A.
Create resources in a single account and share this resource with member accounts in AWS
Organizations by attaching a resource-based policy
B.
Create resources in a single account and share this resource with management accounts in AWS
Organizations by attaching a resource-based policy that will share resources with all other member
accounts
C.
Create resources in a single account and use AWS Resource Access Manager to share resources across
member accounts in AWS Organizations
D.
Create resources in a single account and use AWS Resource Access Manager to share resources with
management accounts in AWS Organizations. Management Account will further share resources with all
other member accounts
Correct Answer: C
Resource Access Manager (RAM) can be used to share resources with other accounts. With RAM,
resources created in one account can be shared with other accounts eliminating admin overhead for
managing these resources.
It leads to cost-saving as resources are created in one account and shared with all other accounts.
In AWS Organizations, resources created in a member account or management account can be directly
shared with other member accounts in the Organizations. The following diagram shows the AWS Resource
Access Manager flow for sharing resources,
- Option A is incorrect as Resource-based policies are used to specify users who can access
resources
and what actions they can perform on the specified resources. These policies cannot be used to
share
resources with AWS Organizations.
- Option B is incorrect as Resource-based policies are used to specify users who can access
resources
and what actions they can perform on the specified resources. These policies cannot be used to
share
resources with AWS Organizations. These policies are attached to the resources irrespective of the
member or management accounts.
- Option D is incorrect as the Resource Access Manager can be used to share resources with the
member
accounts, and there is no need to share with the management account.
Question 5
An IT company uses Scaling policies to maintain an exact number of Amazon EC2 instances in different
Availability zones as per application workloads. The developer team has developed a new version of
the application for which a new AMI needs to be updated to all the instances. For this, you have
been asked to ensure that instances with previous AMI are phased out quickly.
Which termination criteria best suits the requirement?
A.
Specify termination criteria using “ClosestToNextInstanceHour” predefined termination policy
B.
Specify termination criteria using “OldestInstance” predefined termination policy
C.
Specify termination criteria using “AllocationStrategy” predefined termination policy
D.
Specify termination criteria using “OldestLaunchTemplate” predefined termination policy
Correct Answer: D
Amazon EC2 Auto Scaling uses termination policies that determine which Amazon EC2 instance to be
terminated first. Based upon different criteria, it terminates instances. Following are some of the
pre-defined termination policies.
Default
AllocationStrategy
OldestLaunchTemplate
OldestLaunchConfiguration
ClosestToNextInstanceHour
NewestInstance
OldestInstance
In the above case, the company needs to phase out instances with older versions of AMI. For this, a
predefined termination policy with a terminate instance based on OldestLaunchTemplate can be
used.
- Option A is incorrect as this policy will terminate the instance closest to the billing cycle.
This
policy ensures maximizing the use of the instance with an hourly billing cycle.
- Option B is incorrect as this policy will terminate the oldest instance in a group. This policy
will
be useful for replacing older instances with new instances.
- Option C is incorrect as “AllocationStrategy” termination is useful while rebalancing the number
of
EC2 instances in an Auto scaling policy to align to the allocation strategy for the terminating
instance.
Question 6
A large engineering company plans to deploy a distributed application with Amazon Aurora as a
database. The database should be restored with a Recovery Time objective (RTO) of one minute when
there is a service degradation in the primary region. The service restoration should incur the least
admin work.
What approach can be initiated to design an Aurora database to meet cross-region disaster recovery
requirements?
A.
Use Amazon Aurora Global Database and use the secondary region as a failover for service degradation
in the primary region
B.
Use Multi-AZ deployments with Aurora Replicas which will go into failover to one of the Replicas for
service degradation in the primary region
C.
Create DB Snapshots from the existing Amazon Aurora database and save them in the Amazon S3 bucket.
Create a new database instance in a new region using these snapshots when service degradation occurs
in the primary region
D.
Use Amazon Aurora point-in-time recovery to automatically store backups in the Amazon S3 bucket.
Restore a new database instance in a new region when service degradation occurs in the primary
region using these backups
Correct Answer: A
For distributed applications, Global databases can be used. With this, Amazon Aurora spans a single
database across multiple regions. This enables fast reads from each region and helps quick
cross-region disaster recovery. With the Global database, failover to the secondary region can be
completed with an RTO of one minute from the degradation or complete failures in the primary
region.
- Option B is incorrect as this will work only in case of service impact with one of the
Availability
Zones. It won’t work for regional outages.
- Option C is incorrect as creating a new DB instance with snapshots will involve manual work in
provisioning the instance which will delay service restoration.
- Option D is incorrect as although these backups are automated using Amazon Aurora point-in-time
recovery, restoration to another region will result in delay in service restoration.
Question 7
A financial company has deployed a business-critical application on an Amazon EC2 instance,
front-ended by an internet-facing Application Load Balancer. AWS WAF is used with the Application
Load Balancer to secure the application. The security team needs to prevent excessive requests for
specific resources that are computationally heavy. Requests to these resources should be limited to
a threshold, after which any additional requests should be blocked while allowing unlimited access
to lower-cost resources.
Which security policy should be implemented to protect the application?
A.
Create AWS WAF blanket rate-based rules and attach them to the Application Load Balancer
B.
Create AWS WAF URI-specific rate-based rules and attach them to the Application Load Balancer
C.
Create AWS WAF IP reputation rate-based rules and attach them to the Application Load Balancer
D.
Create AWS WAF Managed rule group statements and attach them to the Application Load Balancer
Correct Answer: B
A rate-based rule tracks the rate of the request from the source IP address and takes action once
the limits are crossed. Following are customized rate-based rules which can be used for application
protection,
Blanket rate-based rule: Prevents source IP address from making excessive requests to entire
applications.
URI-specific rate-based rule: Prevents IP address from making excessive requests to the URI (Uniform
Request Identifier) of the application. These are useful if specific functions of the applications,
such as computationally expensive resources need to be protected from excessive requests.
IP reputation rate-based rule: Prevents well-known malicious IP addresses from making excessive
requests to the application.
All the above three rules can be combined or can be used separately as per need.
In the above scenario, the company is looking to limit the number of requests to the heavy
computational resources of the application. This can be achieved by creating URI-specific rate-based
rules and attaching them to the Application Load Balancer. This rule would track the number of
requests made to the URI (Uniform Request Identifier) of the application such as database query or
search function and block the requests once threshold values are crossed.
- Option A is incorrect as blanket rate-based rules will be useful to block source IP addresses that
excessively make requests to the entire application. These rules will not be useful for blocking
excessive requests to the URI of the application.
- Option C is incorrect as IP Reputation rate-based rules will be more useful for limiting traffic
from well-known malicious IP sources.
- Option D is incorrect as Managed rules group would not track the rate of the request and take
action.
Question 8
An IT company has recently deployed highly available resilient web servers on Amazon EC2 instances.
Application Load Balancers are used as the front-end to these instances. The company has deployed a
lower-capacity web server at the on-premises data center. IT Head wants to have Amazon EC2 instances
in AWS Cloud as primary and web servers at the data center as secondary. You will be using Amazon
Route 53 to configure this failover.
How can Amazon Route 53 health checks be designed to get the required results?
A.
For primary resources in the AWS Cloud, create alias records and set Evaluate Target Health to Yes.
For secondary records, create a health check in Route 53 for web servers in the data center. Create
a single failover alias record for both primary and secondary resources
B.
For primary resources in the AWS Cloud, create alias records and health checks. For secondary
records, create a health check in Route 53 for web servers in the data center. Create a single
failover alias record for both primary and secondary resources
C.
For primary resources in the AWS Cloud, create alias records and set Evaluate Target Health to Yes.
For secondary records, create a health check in Route 53 for web servers in the data center. Create
one failover alias record for each primary and secondary resource.
D.
For primary resources in the AWS Cloud, create alias records and health checks. For secondary
records, create a health check in Route 53 for web servers in the data center. Create one failover
alias record for each primary and secondary resource.
Correct Answer: C
Amazon Route 53 health checks can be used to configure active-active and active-passive failover
configurations.
Active-passive failover configuration can be used when primary resources are available most of the
time, and secondary resources are used only in case of primary resources are not available.
For configuring active-passive failover with multiple primary and secondary resources, the following
setting can be done.
For Primary resources, create an alias record pointing to Application Load Balancer with ‘evaluate
health check’ as yes.
For Secondary resources, create health checks for the web servers in the data centers.
Create two failover alias records, one for primary and one for secondary resources.
- Option A is incorrect as two failover alias records need to be created and not a single failover
alias record.
- Option B is incorrect as for alias records created for the primary resources in the AWS cloud,
Evaluate Target Health should be set to Yes. Health checks are not required to be created
separately
for the primary resources. Also, a single failover alias record is not suitable.
- Option D is incorrect as for alias records created for the primary resources in the AWS cloud,
Evaluate Target Health should be set to Yes. Health checks are not required to be created
separately
for the primary resources.
Question 9
A media company uses Amazon EFS as shared storage for its distributed application. These
applications are deployed on Amazon EC2 instances launched in different Availability Zones in the
us-west-1 region. They are planning to launch these applications in Europe for which application
will be set up in the eu-west-2 region. The IT team is looking for a cost-effective solution to
transfer data in Amazon EFS between these two regions on a regular basis. The solution for this data
transfer should not involve transferring data over an insecure public network.
What solution can be adapted to meet this requirement?
A.
Copy files in Amazon EFS to Amazon S3 bucket in us-west-1. Move data between regions using Amazon
S3. In destination eu-west-2 region transfer files from S3 to Amazon EFS
B.
Use Open-source tools to transfer data between Amazon EFS securely
C.
Use AWS DataSync to transfer data between Amazon EFS
D.
In the us-west-1 region, copy files from Amazon EFS to Snowball. At the eu-west-2 region, transfer
files from Snowball to EFS
Correct Answer: C
AWS DataSync is an online data transfer service that can be used to copy large amounts of data
between the AWS regions or from on-premises to AWS.
AWS DataSync can be used to transfer data from Amazon EFS in one region to Amazon EFS in another
region. Using AWS DataSync, data does not transverse over a public network. With AWS DataSync, data
can be automatically copied between the AWS resources on one-time migrations or on a recurring basis
data transfer.
The following diagram shows various AWS resources for which data transfer can be done using AWS
DataSync.
- Option A is incorrect as this would lead to additional admin work and incur charges for data
storage
in the Amazon S3 bucket.
- Option B is incorrect as open-source tools will incur additional costs.
- Option D is incorrect as using snowball would be suitable for transferring a large amount of data.
It would be a more costly option than using AWS DataSync for recurring data transfer.
Question 10
A start-up company uses Amazon CloudFormation templates to launch Amazon EC2 instances in different
regions. AMI used for these instances differs for each instance type and region. Separate templates
need to be created to specify AMI ID as per instance type and as per the region in which instances
need to be launched. The IT team is looking for an effective solution to updating the CloudFormation
template with the correct AMI ID reducing additional management work.
Which solution can be suggested to get the AMI ID updated in the most effective manner?
A.
Use Custom resources and a Lambda function to create a function that will update AMI IDs in the
CloudFormation template
B.
Map AMI IDs to the specific instance type and regions. Manually update the AMI IDs in the
CloudFormation templates
C.
Use Custom resources along with Amazon SNS which will update AMI IDs in the CloudFormation template
D.
Use Custom resources along with Amazon SQS which will update AMI IDs in the CloudFormation template
Correct Answer: A
Custom resources can be used to write custom provisioning logic in an AWS CloudFormation template.
While using Custom resources, AWS CloudFormation sends a request to the service token specified in
the template and processes the stack operation once the response is received.
Custom resources are associated with either of the following,
Amazon SNS-backed custom resources: A SNS topic is associated with the custom resources. Based upon
SNS notifications, provisioning logic is invoked in the stack templates.
AWS Lambda-backed custom resources: A Lambda function is associated with the custom resources. A
lambda function is invoked when a custom resource is updated, deleted, or created.
In the above scenario, to update Amazon EC2 instance AMI in a stack, the AWS Lambda function with
custom resources can be used.
- Option B is incorrect as this will lead to additional manual work whenever there is a change in
AMI
on any Amazon EC2 instance in any region.
- Option C is incorrect as using Custom resources along with Amazon SNS (Simple Notification
Service)
is not ideal for this scenario. It can be used when there is a requirement to add new resources to
an existing stack or inject dynamic data into the stack.
- Option D is incorrect as using Custom resources along with Amazon SQS is an invalid option to
update
Amazon CloudFormation templates.
Question 11
A large company has multiple AWS accounts as part of AWS Organizations. Some of these accounts have
created VPC with NAT gateway for internet access. The Security Team needs to control internet access
to these accounts by attaching the following SCP (Service Control Policies) at the Organizations’
root level.
A.
The policy will deny existing Internet access to all users and roles in member and management
account
B.
The policy will deny creating a new Internet Gateway to all users and roles in member accounts.
There will be no impact on users in management account
C.
The policy will deny creating a new Internet Gateway for all users and roles in member and
management account
D.
The policy will deny existing Internet access to all users and roles in member accounts. There will
be no impact on users in management account
Correct Answer: B
Service Control Policies do not have any impact on users and roles created in the management
account. They affect users and roles only in the member accounts of the AWS Organizations.
Management account is the AWS account that is used to create an organization. From the management
account, other accounts can be created or removed from the Organization. Invitations to other AWS
accounts can be sent from the management account.
The above SCP is attached to the Organization's root level. This will deny users or roles from
creating a new Internet Gateway or attaching an Internet Gateway to the VPCs created in the member
accounts.
This policy will not affect the existing internet traffic from the member accounts.
- Option A is incorrect as the new SCP applied at the Organization level does not block internet
access to existing users. SCP does not affect users or roles in the management account.
- Option C is incorrect as SCP does not affect users or roles in the management account.
- Option D is incorrect as the new SCP applied at the Organization level does not block internet
access to existing users. It would only affect the creation of new Internet Gateways.
Question 12
A company has deployed a memory-intensive financial application on an Amazon EC2 instance. For an
annual maintenance activity on the primary EC2 instance, there should not be a delay in the
initialization of applications on the offline backup EC2 instances. The IT Head wants you to work on
a solution to minimize this delay to ensure that applications on the backup instance are quickly
initialized in a production environment.
What approach can be initiated to meet this requirement?
A.
Launch a backup Amazon EC2 instance. Configure all required applications and bring the instance to
desired production state. Create an AMI from this instance and store it in Amazon S3 for future
deployment
B.
Launch a backup Amazon EC2 instance with hibernation enabled. Configure all required applications
and bring the instance to desired production state. Hibernate the instance
C.
Launch a backup Amazon EC2 instance. Configure all required applications and bring the instance to
desired production state. Stop the instance and reboot once it’s required to be in production
D.
Launch a backup Amazon EC2 instance. Configure all required applications and bring the instance to
desired production state. Store RAM data to EBS volumes and stop the instance. Reboot the instance
with EBS volumes once it’s required to be in production
Correct Answer: B
Hibernation of the Amazon EC2 instance can be used in the case of memory-intensive applications or
if applications take a long time to bootstrap. Hibernation pre-warms the instance, and after
resuming it, it quickly brings all application processes to a running state. When an instance is
hibernated, the Amazon EC2 instance saves all the content of the instance memory RAM to Amazon EBS
volumes. Any root EBS volumes or attached EBS volumes are persisted during hibernation.
Once an EC2 instance is started from the hibernation state, the following activities are
performed,
The EBS root volume and attached EBS volumes are reattached.
The RAM contents are reloaded back to the instance memory from the EBS volumes.
Application processes running before hibernation are back to the original state.
The instance ID is not changed.
The above activities ensure that the applications running on the Amazon EC2 instance are quickly
back to the production level after the hibernation state of the instance. In the above scenario,
backup EC2 instances are initialized with a delay due to memory-intensive applications. For this,
all the required applications can be installed on a hibernation-enabled EC2 instance, and the
instance can be hibernated. Post hibernation mode, the EC2 instance quickly moves to production mode
with all the applications already initialized. The following diagram shows instance flow in a
hibernation state,
- Option A is incorrect as creating a new Amazon EC2 instance from an AMI store in the Amazon S3
bucket will delay bringing the application to the production level.
- Option C is incorrect as Rebooting the Amazon EC2 instance will take time to initialize all the
applications back to the production level.
- Option D is incorrect as storing RAM data to the Amazon EBS will not speed up the application
initialization process. Rebooting the Amazon EC2 instance will take time to bring a
memory-intensive
application to the production level.
Question 13
A start-up firm has established hybrid connectivity from an on-premises location to the AWS cloud
using AWS Site-to-Site VPN. A large number of applications are deployed in the AWS cloud to be
accessed from the on-premises location. Users are complaining of the slowness while accessing these
applications during peak hours. You have been assigned to work on a solution to improve connectivity
throughput from on-premises to AWS.
What solution can be designed to increase VPN throughput?
A.
Establish multiple VPN connections to the ECMP-enabled Transit gateway. Enable dynamic routing on
the Transit Gateway
B.
Establish multiple VPN connections to ECMP-enabled Virtual Private gateway. Enable route propagation
on the Virtual Private Gateway
C.
Establish multiple VPN connections to multiple Transit gateways. Enable dynamic routing on the
Transit Gateway
D.
Establish multiple VPN connections to multiple Virtual private gateways. Enable route propagation on
the Virtual Private Gateway
Correct Answer: A
An AWS Site-to-Site VPN has a maximum throughput of 1.25 Gbps. To scale throughput beyond 1.25 Gbps,
equal-cost multi-path (ECMP) support can be used over multiple VPNs.
AWS Transit gateway supports ECMP, but Virtual Private Gateway does not support ECMP. When multiple
VPN links are established from on-premises to ECMP-enabled Transit Gateway, throughput can scale
over the limit of 1.25 Gbps per tunnel. Dynamic routing using BGP must be enabled on the Transit
Gateway for routing traffic over multiple VPN tunnels.
The following diagram shows multiple VPN tunnels to AWS Transit Gateway.
- Option B is incorrect as Virtual Private Gateway does not support ECMP-enabled VPN
connections.
- Option C is incorrect as multiple VPN connections to multiple Transit gateway will lead to
additional admin load for managing these tunnels. Also, without ECMP support, each VPN tunnel will
have a throughput limited to 1.25 Gbps. Dynamic Routing without ECMP will not increase total
throughput.
- Option D is incorrect as multiple VPN connections to multiple Virtual Private Gateway will lead to
additional admin for managing these tunnels. Also, without ECMP support, each VPN tunnel will have
a
throughput limited to 1.25 Gbps.
Question 14
A start-up firm is using the Internet via NAT Gateway attached to VPC A. NAT gateway is in a single
availability zone, and all the subnets of the VPC A are accessing the internet via this NAT Gateway.
Instances in different availability zones are transferring large volumes of traffic to the Internet
across availability zones using this NAT Gateway. This is leading to high operational costs.
Management is looking for a cost-saving option along with reliable Internet connectivity.
What solution can be designed for cost-effective traffic flow between resources to the Internet?
A.
Create a separate Public NAT gateway in a public subnet of the availability zone having instances
with large volumes of internet traffic
B.
Create a separate Public NAT gateway in a private subnet of the availability zone having instances
with large volumes of internet traffic
C.
Create a separate Private NAT gateway in a private subnet of the availability zone having instances
with large volumes of internet traffic
D.
Create a separate Private NAT gateway in a public subnet of the availability zone having instances
with large volumes of internet traffic
Correct Answer: A
NAT Gateway can be used to provide connectivity to the internet or external networks for AWS
resources launched in a private subnet of the VPC. NAT Gateway can be of any of the following
types
Public NAT Gateway: This can be used to provide Internet access to resources in the private subnets
of the VPC. Public NAT needs to be placed in a public subnet of the VPC, and an Elastic IP address
needs to be associated with this gateway.
Private NAT Gateway: This can be used to provide connectivity with on-premises or other VPCs from a
private subnet of the VPC. No elastic IP address is required to be assigned to a private NAT
Gateway.
In the above scenario, there is a high operational cost due to the data transfer charges between the
availability zones, for instance, accessing the Internet via NAT Gateway in a separate Availability
Zone. This cost can be minimized by placing a separate Public NAT Gateway in the Availability zones
having instances with large volumes of Internet traffic. This Public NAT Gateway needs to be placed
in the public subnet of the VPC and attach an Elastic IP address.
- Option B is incorrect as Public NAT Gateway should be placed in the public subnet of the VPC and
not
in a private subnet.
- Option C is incorrect as for internet traffic Public NAT Gateway is required and needs to be
placed
in a public subnet.
- Option D is incorrect as for internet traffic Public NAT Gateway is required to be attached to the
VPC and not the Private NAT Gateway.
Question 15
A company has created VPC A for deploying web applications. Recently this company has acquired
another company that has created VPC B for deploying applications in an AWS cloud. It is found that
the subnets of both these VPCs are overlapping. The company requires web applications in VPC A to
communicate with servers in VPC B. This communication should be over AWS-managed networking
infrastructure.
Which of the following design can be implemented to establish communications between these VPCs?
A.
Create new subnets from the new CIDR range in both VPCs. Create a public NAT Gateway in this subnet
in both VPCs. Use AWS PrivateLink to connect these VPCs over new subnets. Update route table in both
overlapping subnets to send traffic via NAT Gateway created in the new subnet to establish
connectivity
B.
Create new subnets from the new CIDR range in both VPCs. Create a private NAT Gateway in this subnet
in VPC A and an Application Load balancer in VPC B . Use AWS Transit Gateway to connect these VPCs
over new subnets. Update route table in both overlapping subnets to send traffic via NAT Gateway in
VPC A and via Load balancer in VPC B to establish connectivity.
C.
Create new subnets from the new CIDR range in both VPCs. Create a private NAT Gateway in this subnet
in both VPCs. Use VPC Peering to connect these VPCs over new subnets. Update route table in both
overlapping subnets to send traffic via NAT Gateway created in the new subnet to establish
connectivity
D.
Create new subnets from the new CIDR range in both VPCs. Create a public NAT Gateway in this subnet
in both VPCs. Use AWS Managed VPN to connect these VPCs over new subnets. Update route table in both
overlapping subnets to send traffic via NAT Gateway created in the new subnet to establish
connectivity
Correct Answer: B
Private NAT Gateway can be used to route traffic between two VPCs having overlapping subnets. To
establish communication over those overlapping subnets following configuration needs to be
done,
Create new subnets from a new CIDR in each VPC.
Deploy a private NAT gateway in VPC A and an Application Load balancer in VPC B.
Use AWS Transit Gateway to route traffic between these VPCs.
Update the Route table of the overlapping subnets in VPC A to send all traffic destined to
overlapping subnets of VPC B via a private NAT gateway.
Reverse Traffic from VPC B will be communicating with overlapping subnets in VPC A via Application
Load Balancer. The Application Load balancer will use the IP address of the private NAT gateway as a
destination.
With Private NAT Gateway, all traffic from overlapping subnets is mapped to the IP address assigned
to NAT Gateway while communicating with other overlapping subnets. AWS Transit Gateway is a managed
service that uses AWS Managed Network Infrastructure for routing traffic between VPCs.
The following diagram shows a private NAT gateway for routing traffic between overlapping CIDR of
two VPCs.
- Option A is incorrect as the Public NAT gateway is used to connect to the Internet. For Inter-VPC
overlapping subnet communications, Private NAT Gateway needs to be used. With PrivateLinks, both
interface endpoints need to be created for bi-directional communication which will require
additional admin work.
- Option C is incorrect as VPC peering cannot be established even if any one of the VPC subnets will
be overlapping with subnets in another VPC.
- Option D is incorrect as the Public NAT gateway is used to connect to the Internet. For Inter-VPC
overlapping subnet communications, Private NAT Gateway needs to be used. AWS Managed VPN would be
over public Internet links and not over AWS managed network infrastructure.
Question 16
A large government Organization has created multiple accounts as part of the AWS Organizations. Each
of these accounts has a NAT Gateway attached for Internet access to applications. The Finance team
is looking for total combined charges incurred for all the NAT Gateways as well as charges of
individual accounts for using NAT Gateway.
What strategy can be adopted to get cost details for all NAT Gateway in AWS Organizations?
A.
Assign Cost Allocation tags to NAT Gateway in each of the member accounts from individual member
accounts. Use member accounts in AWS Organizations to access the Cost Allocation Tags manager in the
billing console
B.
Assign Cost Allocation tags to NAT Gateway in each of the member accounts from the Administrator
account. Use a management account in an AWS Organizations to access the Cost Allocation Tags manager
in the billing console
C.
Assign Cost Allocation tags to the NAT Gateway in each of the member accounts individually. Use the
management account in AWS Organizations to access the Cost Allocation Tags manager through the
billing console and ensure proper cost tracking across all accounts.
D.
Assign Cost Allocation tags to NAT Gateway in each of the member accounts from the management
account. Use a member account in an AWS Organizations to access the Cost Allocation Tags manager in
the billing console
Correct Answer: C
AWS uses cost allocation tags to track and categorize costs incurred by the resources. To get total
charges incurred by all the NAT gateway along with charges per account in AWS Organizations, cost
allocation tags can be assigned and activated for each NAT Gateway. These tags can be assigned from
each member's account.
In the billing console, the Cost Allocation Tags manager can be used to view the total monthly bill
and for the individual NAT gateway in each member account. Only Management accounts have the
permission to view the cost allocation tags manager in the billing console.
- Option A is incorrect as the Cost Allocation Tags manager is only accessible from the management
account of the AWS Organizations, not from an individual member account.
- Option B is incorrect as Cost Allocation Tags must be assigned to the individual member account,
but
not from the administrator account.
- Option D is incorrect as the Cost Allocation Tags manager is only accessible from the management
account of the AWS Organizations, not from an individual member account. Cost Allocation Tags must
be assigned to the individual member account, not from the management account.
Question 17
You have created a Lambda function for reading data from the Kinesis stream of transactions. In the
code, you were using a context logger to log to CloudWatch, and you can monitor them at a later
point of time. Lambda function started running along with Kinesis stream. However, you do not see
any log entries for the new Lambda function. What could be the reason?
A.
Lambda functions with Kinesis stream as event source do not write logs to CloudWatch.
B.
Lambda execution role policy does not have access to create CloudWatch logs.
C.
Lambda function execution logs will be written to CloudTrail, not to CloudWatch.
D.
Active tracing is not enabled on the Lambda function setup configuration.
Answer: B
- Option A is not a valid statement. Lambda function will write logs as long as the execution role
has
access to create and write CloudWatch logs irrespective of the source that triggered it.
- Option B is correct. For Lambda functions to write logs to CloudWatch, the execution role must
have
the necessary permissions. Specifically, the role needs permissions for logs:CreateLogGroup, logs:
CreateLogStream, and logs:PutLogEvents
- Option C is not correct. AWS CloudTrail is used for logging API calls made to services such as AWS
Lambda, AWS S3 etc.
AWS CloudWatch for Lambda is used for execution logging.
https://docs.aws.amazon.com/lambda/latest/dg/with-cloudtrail.html
- Option D is not correct. While enabling active tracing can provide more detailed insights into
Lambda execution, it is not required for basic logging to CloudWatch. The absence of active
tracing
would not prevent logs from being written to CloudWatch.
Question 18
A Research and Development department in a global pharma company is planning to store all its
formulation documents as an archive in Amazon S3 Glacier Vault. The security team of this company
wants to ensure that no deletion of these formulation documents is permitted to any user for an
indefinite period. Users should retain permissions to delete temporary document archives stored in
these vaults.
What approach should be initiated to meet this requirement? (Select TWO)
A.
Use vault access policy to match the retention tag and deny deletion of the formulation document
archive
B.
Use vault lock policy to match the retention tag and deny deletion of the formulation document
archive
C.
Set a legal hold on the formulation document archive in the vault
D.
Set a retention period to the formulation document archive in the vault
E.
Use vault lock policy to match the LegalHold tag and deny deletion of the formulation document
archive
Correct Answers: C and E
An Amazon S3 Glacier vault can be attached with one vault access policy and a vault lock policy. The
Vault Access policy can be used to manage access permission to the vault. With Vault Lock Policy, no
changes can be done to the policy once it's locked.
The Vault Lock Policy can be used for managing regulatory and compliance requirements so that no
users can make changes to the archives stored in the vault. S3 Object Lock can be set in one of the
two ways:Retention Period in which objects are locked for a specific time period and Legal Hold in
which objects can be locked with no expiration date.
- Option A is incorrect as the vault access policy can be used to implement access permission to the
Amazon S3 Glacier Vaults.
- Option B is incorrect as the documents need to be locked for an indefinite period. The Vault lock
policy must be created matching the LegalHold tag, not the retention Tag.
- Option D is incorrect as setting Retention period can be used for specific fixed periods during
which the archives will be locked. In the above case, archives need to be locked indefinitely.
Using
a retention period is not the right option.
Question 19
A company is using AWS Organizations for managing accounts created in multiple regions. Each of
these accounts has created Amazon S3 buckets for storing files. During a security audit, it was
found that some of these S3 buckets have public access without any proper requirements leading to
security risks. The Security Team has engaged you to propose a secure design to deny all accounts in
AWS Organizations from creating an S3 bucket with public access.
What policies can be designed to ensure additional protection?
A.
Enable Amazon S3 Block Public Access on AWS Organization’s Service Control Policies (SCPs) to deny
users making changes to these settings
B.
Enable Amazon S3 Block Public Access on individual objects in all the S3 buckets and configure SCPs
to deny users making changes to these settings
C.
Use Amazon S3 ACLs on individual objects in all the S3 buckets and configure SCPs to deny users
making changes to these settings
D.
Use the Amazon S3 bucket policy in all the S3 buckets and configure SCPs to deny users making
changes to these settings
Correct Answer: A
SCPs (Service control policies) assist in centrally controlling permissions for all accounts in AWS
Organizations. This helps to ensure that all the accounts in AWS Organizations are following the
same access guidelines.
Amazon S3 Block Public Access settings can be used to manage public access to Amazon S3 buckets. By
default, all the new buckets created in Amazon S3 do not support public access. But users can change
these settings to allow public access to the bucket.
Block Public Access settings can be used to deny permission to users from making changes to public
access to the bucket. SCP can be applied at the Organization Root-level to deny all accounts
permission to make S3 buckets public.
- Option B is incorrect as Block Public access settings are only supported for access points, S3
buckets, and AWS accounts. These settings are not supported on individual objects in the S3
bucket.
- Option C is incorrect as ACLs (Access Control List) can be used to control access to individual
objects in an S3 bucket. Using S3 block public access is a better option to deny all public access
to the objects in an S3 bucket.
- Option D is incorrect as bucket policies are resource-based policies that provide permission to
object and the bucket. Using S3 block public access is a better option to deny all public access
to
the objects in an S3 bucket.
Question 20
An IT Company has deployed Amazon EFS in VPC A created in eu-west-2. Data in this Amazon EFS needs
to be accessed from the Amazon EC2 instance in VPC B created in us-east-1 and from an on-premises
location. On-Premises locations have an existing AWS Direct Connect link with VPC B. You need to
provide a high-performance cost-effective solution for this data access with optimum latency.
Which solution can be designed for accessing data in Amazon EFS?
A.
Create an AWS Managed VPN from on-premises to VPC A. Over this connectivity, access Amazon EFS in
VPC A. For instance, in VPC B, connect to the on-premises network using the existing Direct Connect
Link. From there, use VPN connectivity to establish connectivity to Amazon EFS in VPC A
B.
Create an AWS PrivateLink between VPC A and VPC B. Access Amazon EFS in VPC A from an instance in
VPC B over this PrivateLink. From the on-premises network, use existing AWS Direct Connect to VPC B.
From there, use PrivateLink to connect to Amazon EFS in VPC A
C.
Create an inter-region VPC peering between VPC A and VPC B. Create an AWS Managed VPN from
on-premises to VPC A. Access Amazon EFS in VPC A from the instance in VPC B over VPC peering while
establishing connectivity from on-premises servers to Amazon EFS in VPC A over VPN connectivity
D.
Create an inter-region VPC peering between VPC A and VPC B. Access Amazon EFS in VPC A from the
instance in VPC B over VPC peering. From the on-premises network, use existing AWS Direct Connect to
VPC B. From there, use VPC peering to connect to Amazon EFS in VPC A
Correct Answer: D
This solution leverages inter-region VPC peering to connect VPC A and VPC B, allowing the EC2
instance in VPC B to access Amazon EFS in VPC A with low latency. Additionally, the existing AWS
Direct Connect link from the on-premises location to VPC B can be used to access Amazon EFS in VPC A
via the VPC peering connection.
- Option A is incorrect as accessing Amazon EFS over VPN connectivity may lead to latency as traffic
transits over the public internet.
- Option B is incorrect AWS PrivateLink is typically used for accessing services within the same
region and is not designed for inter-region connectivity. This option would not be suitable for
connecting VPCs in different regions.
- Option C is incorrect as this will incur additional cost and admin work for setting a Managed VPN
connection from an on-premises location to VPC A.
Question 21
Jim is a Solutions Architect working in an MNC that owns a global E-Commerce application. They have
stored the data across different regions around the world and always look for ways to provide low
latency data delivery to their global customers securely. All the data is encrypted using KMS, but
they have observed some latency issues in some regions recently. After checking out a few
configurations, Jim found the cause of the issue: the call made to KMS for using a single encryption
key is available in the Mumbai region only.
What should Jim use to resolve the latency issues in the given scenario?
A.
Store all the data in the Mumbai Region only instead of multiple Regions
B.
Create Multi-Region keys in the Regions where the data resides
C.
Disable encryption and serve the unencrypted data to avoid the encryption key issue
D.
KMS Keys are not Region-specific. Instead, they are available in all regions by default, no matter
where you create them. Latency might be due to other unknown issues
Correct Answer: B
- Option A is incorrect because it is clearly mentioned in the question that the website is a GLOBAL
application depicting that the customers are located in multiple parts of the world. Storing the
data in a single region will make the customers from other regions face more latency issues.
- Option B is CORRECT. The latency issues can be resolved by creating the multi-region keys in KMS.
Refer to the following snippets from this documentation.
- Option C is incorrect because it is clearly mentioned in the question that the company is focused
on
looking for ways that can reduce the latency for their customers and serve the data securely. This
means that we can’t disable encryption to resolve the latency issues.
- Option D is incorrect because the given statement is false. The truth is, AWS KMS has been
strictly
isolated to a single AWS Region for each implementation, with no sharing of keys, policies, or
audit
information across Regions.
Question 22
Whizlabs, an E-Learning platform hosted on AWS provides various online courses to a global audience.
They have video lessons and quiz questions for every lesson. They are more customer-centric and
always work to improve their services based on the feedback received from their customers. Recently
they have seen a surge in the responses where their customers are demanding a feature where they can
listen to the questions in the quiz instead of just reading it because they understand it better by
listening. It will help the visually impaired learners as well.
Krish, the solutions architect at Whizlabs, is looking for a solution to introduce this feature to
their platform. Which of the following options can fulfill the given requirement?
A.
Use Amazon Rekognition to identify the text from the quiz page and convert it from Text to Speech
B.
Use Amazon Textract to extract the text from the quiz questions and convert it from Text to Speech
C.
Use Amazon Comprehend to use its NLP-based functionality to implement this feature
D.
Use Amazon Polly to implement this feature in the platform
Correct Answer: D
- Option A is incorrect because Amazon Rekognition is a service with which you can identify objects,
people, text, scenes, and activities in images and videos, etc. and also provides highly accurate
facial analysis and facial search capabilities that you can use to detect, analyze, and compare
faces for various use cases. It can’t do the Text to Speech Conversion.
- Option B is incorrect because Amazon Textract is a fully managed machine learning service that
automatically extracts printed text, handwriting, and other data from scanned documents. It is for
the use cases that go beyond simple optical character recognition (OCR) to identify, understand,
and
extract data from forms and tables. It can’t do the Text to Speech Conversion.
- Option C is incorrect because Amazon Comprehend is a natural-language processing (NLP) service
that
uses machine learning to uncover valuable insights and connections in text. It is used mainly for
sentiment analysis from the given text, but not for text-to-speech conversions.
- Option D is CORRECT because Amazon Polly is a service that turns text into lifelike speech,
allowing
you to create applications that talk and build entirely new categories of speech-enabled products.
So, Krish can easily use Amazon Polly to build the required feature in the platform without any
hassle.
Question 23
Shoptech is a recently launched E-Commerce platform serving customers around the globe. For the
platform, they have used EC2 instances as application servers managed by an Auto Scaling Group. For
the database layer, they have used Amazon RDS with MySQL engine.
During their regular monitoring activity, the team observed performance issues in the form of slower
database queries over the last few days. They also observed that the DB instance is intermittently
throwing “too many connections” errors. They found that this might happen due to the large number of
database connections getting opened to ensure quick user response times. These active connections
are barely getting used. Which of the following options can solve the problem in the MOST Efficient
way?
A.
Use Amazon RDS Proxy with the MySQL DB instance
B.
Provision more capacity to the MySQL DB instance
C.
Use Multi-AZ deployments for MySQL DB instance
D.
Create Read Replicas with the MySQL DB instance
Correct Answer: A
- Option A is CORRECT because RDS Proxy is a feature available with Amazon RDS which makes your
database more resilient to failures and your applications more scalable. It lets you use your
databases more efficiently. You get the advantage of Connection Pooling in RDS Proxy which makes
it
possible to share and use the already open database connections.
So, it is a good choice for the scenarios where the database performance is degrading because of
too
many connections. It also controls the total number of DB connections opened. With each
connection,
database memory and compute resources are used, no matter what, the connection gets used or stays
idle.
https://aws.amazon.com/rds/proxy/
- Option B is incorrect because it is mentioned in the question that you have to select the MOST
efficient way. If you provision more capacity to your database, it will lead to more costs.
Instead
of increasing the capacity, it is better to use the already available capacity more EFFICIENTLY.
This can be achieved by using RDS Proxy.
- Option C is incorrect because enabling Multi-AZ Deployments for your DB Instance will just create
a
secondary copy of your database in another AZ. It won’t solve the problem of slower database
performance because of more DB Connections. Moreover, it will increase the overall cost since
there
will be 2 DB instances in 2 AZs. That’s why RDS Proxy is the most efficient solution for the given
requirement.
- Option D is incorrect. Although creating Read Replicas for your DB instance will decrease the load
on your primary instance, it still doesn’t satisfy the complete requirement. The multiple
connections will still be opened on the DB instance. Read Replicas are a good choice when you have
a
read-heavy application. So you can offload reads to the read replicas. But using the DB
connections
efficiently is a perfect choice for the current scenario.
Question 24
An IT company Techify has recently started using Amazon SQS to let their web servers communicate
with the application servers through the messages in the SQS queue. However, upon testing, the team
observed that the request from the Web server is not reaching the App server and they are looking
for an AWS Service that can efficiently help them debug such errors. They also want to identify
potential issues and more information about errors and latency for the messages passing through SQS.
Which of the following services/ features can be used in the given scenario?
A.
Amazon CloudTrail
B.
Amazon Inspector
C.
Amazon Cloudwatch
D.
Amazon X-Ray
Correct Answer: D
- Option A is incorrect because Cloudtrail will track and record just the API calls. It just records
the API Calls, including information about who, what, when, and where for each API Call. It cannot
trace the request from the web server to the app server end-to-end to identify the root cause and
resolve it.
- Option B is incorrect. Amazon Inspector is used to discover and scan vulnerabilities and
unintended
network exposure. It is basically used for automated security assessment requirements. This is not
needed in the current scenario as there is no security issue mentioned. In fact, the issue is in
the
communication between servers which can be traced using Amazon X-Ray.
- Option C is incorrect. Although Cloudwatch lets you collect some logs for troubleshooting your
application, X-Ray is still a better choice. X-Ray is more effective as it lets you have a visual
representation of your services with every integration point. This will help you get a quick
insight
into any failure or success.
- Option D is CORRECT because Amazon X-Ray is a service used to analyze and debug distributed
applications at the production level, especially microservices architectures. Amazon X-Ray will
integrate with Amazon SQS and help the company troubleshoot the issue behind web and app server
communication.
Question 25
Kayne is instructed by his manager to build a solution to detect whether the visitors entering their
office building are wearing a face mask or not. The building has two entrances with CCTVs installed
on both. The data needs to be captured from them and sent to AWS for detection and analysis.
He is exploring AWS Services to build this solution efficiently. After some research, he has found
that Amazon Kinesis with a combination of Amazon Rekognition can serve the purpose. But he is not
aware of what capability in Kinesis will help in this case.
Which of the following Kinesis capabilities is MOST appropriate for the given scenario?
A.
Amazon Data Firehose
B.
Kinesis Data Analytics
C.
Kinesis Video Streams
D.
Kinesis Data Streams
Correct Answer: C
- Option A is incorrect because Kinesis Data Firehose is fully managed and used to capture,
transform
and load the data from various sources into AWS data stores like Amazon S3, Amazon Redshift, etc.,
data lakes or analytical services. But it doesn’t capture the data from the video streaming
devices
like CCTVs as mentioned in the given scenario.
- Option B is incorrect because Kinesis Data Analytics is used to gather streaming data from sources
like Kinesis data streams, Amazon S3, IoT devices, etc. It analyzes the data by performing the
queries and sends the output to other AWS services or analytical tools. This output can be
utilized
for creating alerts or responding in real-time. It doesn’t capture the video streams as required
in
the current scenario.
- Option C is CORRECT because Kinesis Video Streams is explicitly built for the use cases like video
playback, face detection, security monitoring, etc. It can serve the purpose mentioned in the
given
scenario. The CCTVs will stream the video to Kinesis Video Streams in real-time. It will then
ingest
and index those streams used for Face detection. After that, you can use Amazon Rekognition Video
to
perform face detection for mask checking in the streaming video.
- Option D is incorrect because Kinesis Data Streams is useful for capturing GBs of real-time data
every second from various sources. This data can be further consumed by Kinesis data analytics,
Amazon EMR, etc. to query and perform analytics on it. It neither captures the data from Video
Streaming devices nor sends it to Amazon Rekognition which was the main requirement in the given
scenario.
Question 26
A financial firm has built an application on AWS with containerized components running on AWS ECS.
These components receive critical financial data in the form of files (PDFs, JPEGs, DOCX) that are
uploaded asynchronously to a Document Management Store (DMS). There have been instances in the
production environment where files were not available in the DMS due to failed upload operations.
During campaigns, the firm expects a 500% increase in traffic, meaning files need to be temporarily
stored and accessed if the upload operation fails.
As a Solutions Architect, how would you design a resilient system to handle this increased load
while ensuring cost-effectiveness?
A.
Use Amazon S3 for temporary storage and Amazon SQS to queue upload requests.
B.
Use Amazon RDS to store files temporarily and Amazon SNS for notifications
C.
Use Amazon DynamoDB for temporary storage and AWS Lambda for processing.
D.
Use Amazon EFS for temporary storage and Amazon MQ for messaging.
Correct Answer: A
- Option A is Correct, This is the most appropriate solution. Amazon S3 provides durable and
scalable
storage for temporarily holding files, while Amazon SQS ensures that upload requests are managed
efficiently, even during high-traffic periods. This combination helps in handling failed uploads
and
retrying them as needed.
- Option B is incorrect, This option is less suitable. Amazon RDS is designed for relational
database
storage and is not ideal for storing large files like PDFs, JPEGs, and DOCX. Additionally, Amazon
SNS is more suited for sending notifications rather than managing file uploads.
- Option C is incorrect, Amazon DynamoDB is a NoSQL database service and is not optimized for
storing
large binary files. While AWS Lambda can handle processing, DynamoDB is not the best choice for
temporary file storage. S3 and SQS are better suited for this use case.
- Option D is incorrect, Amazon EFS (Elastic File System) can be used for file storage, but it may
not
be as cost-effective or scalable as S3 for this scenario. Amazon MQ is a managed message broker
service, but SQS is simpler and more cost-effective for queuing upload requests.
Question 27
You have hosted an application on an EC2 Instance in a public subnet in a VPC. For this
application’s database layer, you are using an RDS DB instance placed in the private subnet of the
same VPC, but it is not publicly accessible. As the best practice, you have been storing the DB
credentials in AWS Secrets Manager instead of hardcoding them in the application code.
The Security team has reviewed the architecture and is concerned that the internet connectivity to
AWS Secrets Manager is a security risk. How can you resolve this security concern?
A.
Create an Interface VPC endpoint to establish a private connection between your VPC and Secrets
Manager
B.
Access the credentials from Secrets Manager through a Site-to-Site VPN Connection
C.
Create a Gateway VPC endpoint to establish a private connection between your VPC and Secrets Manager
D.
Access the credentials from Secrets Manager by using a NAT Gateway
Correct Answer: A
- Option A is CORRECT because, as per the documentation, “You can establish a private connection
between your VPC and Secrets Manager by creating an interface VPC endpoint.” That’s how your EC2
instance can fetch the DB Credentials from the Secrets Manager privately. Once it gets the
credentials, it can securely establish the connection with the RDS DB instance.
- Option B is incorrect because a Site-to-Site VPN connection would be more appropriate in case of
hybrid environments where you want to connect AWS and on-premises networks. Here, we just have two
AWS services that need to communicate without the internet.
- Option C is incorrect. Although using the VPC Endpoint indicates the correct solution, the type of
interface mentioned is incorrect. For AWS Secrets Manager, the Gateway endpoint is
unavailable.
- Option D is incorrect because NAT Gateway is more appropriate for communicating privately with
other
VPCs or on-premises environments. This is more expensive. Mostly it is used when your private
subnet
resources want to communicate one way (only outbound) with the Internet. Here in this question, we
just have the EC2 instance that needs to communicate securely without the internet with AWS
Secrets
Manager which resides outside VPC. That’s why using a VPC Endpoint would satisfy the
requirement.
Question 28
You have deployed an application on a fleet of EC2 Instances managed by an Auto Scaling Group. For
the even distribution of traffic, you have deployed a load balancer also. For better protection, you
use a TLS Certificate issued by AWS Certificate Manager with the load balancer for 390 days. The
domain ownership of this certificate has been validated by your email address.
Your manager instructed you to keep an eye on TLS Certificate expiration and renewal to avoid any
downtime in your system. You checked the ACM (AWS Certificate Manager) Console for the certificate
validity status, and it says “Pending validation.” Which option describes the possible cause and the
resolution for this?
A.
The TLS certificate is expiring soon and needs to be renewed. Renew it by following the link in the
email received by ACM regarding certificate expiration on any of the domain’s WHOIS mailbox
addresses
B.
The TLS Certificate has expired today. ACM was not able to renew it before expiration. Request a new
certificate
C.
The TLS certificate is expiring soon. ACM will automatically renew the certificate in some time, so
no action is required by you
D.
The TLS Certificate has expired today. Write an email to AWS Support to renew your certificate
Correct Answer: A
- Option A is CORRECT. As specified in the question, the certificate has been in use for 390 days,
which means the certificate is not expired yet. But it will expire in the next 5 days. Read the
following snippets for Certification Expiry info and Pending Validation status.
Options B and D are incorrect because the certificate hasn’t expired yet. They are valid for 395
days (13 months). Moreover, you do not need to write any email to AWS support to renew the
certificate. It happens automatically (in DNS Validation) or with a small manual action (in Email
Validation).
- Option C is incorrect. Although the root cause is true as the certificate is expiring soon, the
resolution specified is wrong. The question explicitly says that the domain ownership was
validated
using email. In the case of Email Validation, the domain owner needs to perform an action
manually.
ACM renews the certificate automatically only in case of DNS Validated domain ownership.
Question 29
You have designed a loosely coupled architecture for a restaurant’s order processing application.
There is a set of microservices built using lambda functions for different processes. You have used
Amazon SNS for all the notification sending requirements. When the user places an order, a
notification is sent to the restaurant, and the restaurant sends confirmation of acceptance or
cancellation, and the process continues.
You are exploring AWS services to find one that will let you orchestrate this architecture. You also
want to have a track of each and every task and event in your application but without any additional
overhead of building this manually. Which of the following services suits the given requirement in
the BEST way?
A.
AWS Batch
B.
AWS Step Functions
C.
Amazon SQS
D.
AWS Glue
Correct Answer: B
- Option A is incorrect. AWS Batch is a service that is focused mainly on high-performance computing
workloads. It lets you run and process thousands of batch computing jobs by provisioning the
required optimal quantity of computing resources.
In the question, there’s the requirement to orchestrate the workload which can be served by AWS
Step
Functions.
Step Functions lets you define the workflow steps for architecture by orchestrating input and output
from various AWS services. Consider this for an example: taking the output of the first lambda
function and passing it as the input for the second lambda function to continue the process.
- Option B is CORRECT. AWS Step Functions satisfies the requirement specified in the question. It
orchestrates the workflow steps and provides visibility into each step through visual
workflows.
- Option C is incorrect. Although Amazon SQS and Step Functions both help in some sort of
orchestration, Step Functions is more relevant here. Amazon SQS doesn’t have the capability to let
you track all the tasks and events of your application. If you want this functionality, you must
build it yourself. The question says you do not want the additional overhead of building this
manually. That’s why we can eliminate Amazon SQS.
- Option D is incorrect. AWS Glue is a service mainly used to orchestrate your ETL (
Extract-Transform-Load) workloads. You can create a workflow in AWS Glue, but the main purpose
will
be to extract, transform and load jobs. This is not needed in the current scenario. In fact, here
we
need a solution to orchestrate the steps performed by our architecture components.
Question 30
You have designed the architecture for an E-Commerce website for one of the clients. It is hosted on
a set of EC2 Instances managed by an Auto Scaling Group and sitting behind an Application Load
Balancer.
You have registered the domain name as myshoppingweb.com. The client has asked you to ensure the
users should be able to access the website with myshoppingweb.com (root domain) as well
as www.myshoppingweb.com (subdomain). What configuration do you need to set up an Amazon Route 53 to
satisfy the client’s requirement?
A.
Create a CNAME record for myshoppingweb.com pointing to the ALB and an Alias record
for www.myshoppingweb.com pointing to the ALB
B.
Create a CNAME record for myshoppingweb.com pointing to the ALB and a CNAME record
for www.myshoppingweb.com pointing to the ALB
C.
Create an Alias record for myshoppingweb.com pointing to the ALB and a CNAME record
for www.myshoppingweb.com pointing to the ALB
D.
Create an A record for myshoppingweb.com pointing to the ALB and AAAA record
for www.myshoppingweb.com pointing to the ALB
Correct Answer: C
- Option A is incorrect because you cannot create a CNAME record for the root domain i.e.
myshoppingweb.com.
- Option B is incorrect because you cannot create a CNAME record for the root domain i.e.
myshoppingweb.com. Half of the solution is valid; you can create the CNAME record for the
subdomain.
- Option C is CORRECT because, as per the documentation, you can create an alias record at the top
node of a DNS namespace, also known as the zone apex. Amazon Route 53 alias records provide a
Route
53–specific extension to DNS functionality. Alias records let you route traffic to selected AWS
resources, such as CloudFront distributions, Elastic Load Balancing, and Amazon S3 buckets.
For example, if you register the DNS name myshoppingweb.com, the zone apex is myshoppingweb.com.
You
can't create a CNAME record for myshoppingweb.com.
- Option D is incorrect because the A record takes the input as the value of the IPv4 address in the
decimal notation and the AAAA record takes the input as the value of the IPv6 address. This means
they can’t take the value of ALB’s DNS name as input.
Question 31
An organization has recently adopted AWS cloud for hosting its applications. They have multiple AWS
accounts to gain the highest level of isolation amongst its resources & security. They have
implemented a Data Lake for analytics in one of their accounts (Analytics Account) and use SQS
messaging queue for exporting data to the Analytics Account coming from various data sources in
other accounts. A consumer in the Analytics Account reads the data from SQS & transfers it to the
Data Lake. How would you, as a Solutions Architect, enable different accounts to access the SQS
queue in the most efficient and performant way?
A.
Use an IAM policy and provide SendMessage permission to the SQS queue to other accounts
B.
Use an SQS policy and provide SendMessage permission to the SQS queue to other accounts
C.
Use an IAM Role and provide SendMessage permission through SQS policy and assume the role in the
other accounts
D.
Both B & C will work
Correct Answer: B
- Option A is incorrect. IAM policies need to be used in conjunction with assumeRole to provide
cross-account access. You cannot create an IAM policy in the Analytics Account and enable access
to
SQS actions like SendMessage to another account. The IAM policy will be applicable to groups and
users within the account.
- Option B is CORRECT. Using SQS policies, you can grant permissions to different SQS actions to
other
AWS accounts. So, when the other accounts write data to the SQS queue on the Analytics Account,
the
SQS policy with an Action sqs:SendMessage mentioning the other accounts’ IDs will be required for
the operations to succeed. Please refer to the documentation links mentioned below for more
details.
- Option C is incorrect. You can define an IAM Role in the Analytics Account and provide access to
the
SQS queue for other accounts. For that, you need to define an IAM policy in the other accounts to
assume the role created in the Analytics Account. Although the solution does satisfy the scenario
requirements, it requires additional steps of creating STS permissions in each of the writer
accounts. Also, there will be an additional API call to STS for obtaining temporary credentials to
access SQS impacting performance & efficiency.
- Option D is incorrect since - Option C is invalid for the scenario.
Question 32
An organization has implemented an online Savings Account application that uses a microservices
architecture for orchestrating different processes. One of the orchestrating processes is “Account
Creation” which orchestrates various API calls for creating the Savings Account. For performance
reasons, the API orchestration is a mix of synchronous & asynchronous calls. It has been observed
that certain asynchronous calls leave the system in an inconsistent state when they fail. An example
of this is the Savings Account would have been created, but the Customer’s information may not have
been created. What would you, as an Architect, do to ensure the highest durability of the system?
A.
Implement the asynchronous calls as synchronous & encapsulate them in a distributed transaction to
ensure the highest durability
B.
Process the exception from the asynchronous call and implement a retry mechanism for ensuring that
the call succeeds
C.
Process the exception from the asynchronous call and send an SNS notification to interested parties
for resolution
D.
Implement an event-driven mechanism using SQS and Lambda instead of calling the API asynchronously
Correct Answer: D
On closely observing the scenario, we can see that Performance & Durability are the two key
Non-Functional aspects that need to be addressed while architecting the system. Although the
performance aspect is resolved by making certain calls asynchronous while orchestrating the API
calls, the exceptions that arise from the asynchronous calls are not handled to ensure the system's
durability. The highest level of durability can be achieved by implementing a queueing mechanism to
decouple systems when an immediate response is not required.
Using SQS we can ensure that messages are processed even when certain systems may be having a
downtime ensuring resiliency. Also, features like visibility timeout ensure that the messages are
available to be processed more than once if the system encounters errors while processing the
message. Lambda & SQS can be used in conjunction to implement an event-driven mechanism to ensure
the highest durability of the system.
- Option A is incorrect since making all calls synchronous will result in a blocking call for every
thread that may impact performance. Also, distributed transactions in microservices are not
recommended as they will have difficulty in implementation and have a huge performance
overhead.
- Option B is incorrect since different systems to which the API connects may be encountering
downtime
for an extended period of time & retry attempts for failure scenarios may not provide an optimal
solution.
- Option C is incorrect since SNS notifications will not ensure that the system becomes durable. It
will be a manual process where the operations team may have to reinitiate the process again or
roll
back the existing state.
- Option D is CORRECT. An SQS queue will provide the highest durability of received messages and
help
decouple different systems for good performance. Along with Lambda, it will provide a resilient
event-driven Architecture
Question 33
An organization is currently planning to move its Employee Self Service applications from its
on-premises data center to AWS Cloud. The organization presently has millions of users maintained in
its Corporate Directory on-premises. The organization needs to provide access to all the
applications that would be migrated from on-premises to the cloud after logging in to their
on-premises employee portal. The Organization is also planning to extend access to other Cloud-based
applications like SalesForce in the future. What is the best solution can you, as an Architect,
propose to have users on-premises access the applications in AWS?
A.
Define all users that are existing on-premises in IAM, provide access to the applications using IAM
policies, and ask the user to do a secondary login to AWS for accessing those applications after
login into their on-premises portal
B.
Use web identity federation using an Identity Provider like Amazon and Facebook that will
authenticate the user and request temporary credentials from AWS STS. Use these temporary
credentials and assume a role to access AWS applications
C.
Use SAML 2.0 Identity federation to authenticate users within their Corporate Directory and request
temporary credentials from AWS STS to assume a role with SAML for accessing AWS applications
D.
Use AWS IAM Identity Center to sign-on users defined in the Corporate Directory on-premises with
SAML 2.0 based identity federation for accessing the AWS applications
Correct Answer: D
There are different ways to access AWS resources in a Hybrid cloud model.
AWS IAM Identity Center is a cloud-based single sign-on service that makes it easy to centrally
manage single sign-on access to different AWS accounts and cloud applications.
AWS IAM Identity Center also provides built-in integrations with many cloud applications like
SalesForce, Jenkins, etc.
AWS IAM Identity Center provides the flexibility of having its user database in IAM, AWS-managed
Microsoft AD, on-premises AD services, and Integration with an Identity Provider who is SAML 2.0
compliant.
- Option A is incorrect since it will result in duplicating the users in IAM from the organization’s
corporate directory and also having users log in twice to access the applications. This option
will
not achieve the requirement.
- Option B is incorrect since web identity federation is used for applications that run on Mobile
devices/Tablets where millions of users may get authenticated using Identity Providers like
Amazon,
Google, and Facebook.
- Option C is incorrect since the scenario requires flexibility to access other applications like
Salesforce apart from their own applications. Federated identity access with SAML is definitely
possible, but AWS IAM Identity Center will be a more extensible solution for the mentioned vision
of
the organization.
- Option D is CORRECT for the provided explanations above. With AWS IAM Identity Center, the
existing
on-premises identity provider can be used. The applications that will be migrated to AWS can be
accessed using SAML 2.0 identity federation. Also, additional applications in the cloud like
Jenkins, SalesForce can be provided access easily using AWS IAM Identity Center.
Diagram:
Question 34
An organization is currently implementing a Cloud-Native microservices architecture using AWS EKS
for their Banking application. The pods, whose nodes are EC2 instances running in the EKS cluster,
store sensitive data. They are looking for a secure encrypted storage option that will exhibit high
performance and throughput for their intensive transactional workloads. Which of the following can
be the best fit Architecture for fulfilling the Organization’s requirements?
A.
Use a general-purpose SSD Backed EBS volume with “Multi Attach” for storing data. Enable “Encryption
at Rest”
B.
Use an EBS-Optimized instance with SSD Backed EBS volume and “Multi Attach” for storing data. Enable
“Encryption at Rest”
C.
Use a Provisioned-IOPS SSD EBS volume with “Multi Attach” for storing data. Enable “Encryption at
Rest”
D.
Use a throughput optimized HDD EBS volume for storing data with “Multi Attach”. Enable “Encryption
at Rest”
Correct Answer: C
Container orchestration frameworks like EKS can schedule PODs to run on different nodes.
For example, when 2 instances (replicas) of PODS run, the Kubernetes orchestrator can schedule these
instances on different nodes. Since these nodes use EC2 instances, we have a scenario where multiple
EC2 instances need to have shared access to common storage. EBS “Multi Attach” volumes provide this
feature within a single Availability Zone wherein multiple EC2 instances can now attach to an EBS
volume with the “Multi Attach” feature. Enabling the Encryption at rest feature of EBS will satisfy
their requirements for secure storage.
- Option A is incorrect since the use case demands high throughput & performance. Also, General
purpose SSD EBS types do not support the “Multi Attach” feature.
- Option B is incorrect. An Amazon EBS-optimized instance uses an optimized configuration stack and
provides additional, dedicated capacity for Amazon EBS I/O. When SSD backed EBS volume attached to
an EBS–optimized instance, General Purpose SSD (gp2 and gp3) volumes are designed to deliver at
least 90% of their provisioned IOPS performance 99% of the time in a given year". However, SSD
based
instances do not support the “Multi Attach” feature which is essential for the use case.
- Option C is CORRECT. With Provisioned IOPS, one gets the benefit of achieving high performance &
throughput and the ability to use the “Multi Attach” feature for different PODs to be able to
access
the storage.
- Option D is incorrect since HDD types are recommended for use cases like Big Data, and Data
Warehousing solutions rather than for OLTP systems. Also, HDD-type EBS instances do not support
the
“Multi Attach” feature.
Question 35
Your organization is planning to use AWS ECS for docker applications. However, they would like to
apply 3rd party monitoring tools on the ECS container instances to monitor the instances. They
approached you asking for a recommendation. What do you suggest?
A.
AWS ECS is a managed service. Customers cannot install 3rd party software. Use CloudWatch for
monitoring metrics.
B.
Customers will have control over AWS ECS container instances and can set up monitoring like a normal
EC2 instance.
C.
Consult AWS Support team to install 3rd party software on ECS. The support team will review the case
and install if 3rd party software is in their trusted software entries.
D.
AWS ECS is a managed service. Customers cannot install 3rd party software. Use application-level
monitoring.
Answer: B
Options A and D are incorrect because AWS ECS uses EC2 instances with ECS-optimized AMI. You will
have root access to the instances and you can manage them.
- Option C is incorrect as it is just a distractor, there is no need for a support team.
Question 36
A monolith application is currently being converted into a microservices architecture. The
microservices use a container orchestration engine (ECS) for managing all container-based
deployments. The AWS account which is hosting the application has high-Security requirements. It
plans to build an analytics platform to gather data from all of the AWS ECS Service API calls in
near real-time. It is necessary to track & analyze different state changes that occur during AWS ECS
Service deployment & runtime with different tools like Kinesis, ELK, and Lambda. How will you
architect this solution to meet the requirement?
A.
Configure AWS Config and stream AWS ECS API calls to an SNS topic. Use a Lambda function to perform
an analysis of the configuration changes by subscribing to the SNS Topic
B.
Use AWS CloudTrail Setup that will deliver AWS ECS API calls to S3. Subscribe a Lambda function to
S3 events which will insert records into an ELK stack for analysis
C.
Use Amazon EventBridge to capture AWS ECS API calls, route them to Amazon Kinesis Data Streams, and
forward the data to Amazon Managed Service for Apache Flink for real-time analysis.
D.
Use CloudWatch Logs for pulling the AWS ECS API calls and integrate them with an ELK stack for
analysis
Correct Answer: C
- Option A is incorrect. Quite possible to use AWS Config to deliver state changes of ECS service
deployments, but it will not be real-time. Also, we may ship the data to a data warehouse/data
lake
before performing analytics rather than using Lambda.
- Option B is incorrect. Although CloudTrail delivers AWS API logs, the process mentioned will not
be
in real-time. Also, ELK is more effective for creating visual dashboards rather than performing
analytics.
- Option C is CORRECT. Amazon EventBridge can capture AWS ECS API calls, route them to Amazon
Kinesis
Data Streams, and forward them to Amazon Managed Service for Apache Flink for real-time analysis,
ensuring near real-time tracking of changes.
- Option D is incorrect. CloudWatch logs are often used to capture application logs and centralize
them for analysis. The requirement here is to capture service API calls.
Question 37
The CEO of your organization would like to enforce stringent compliance over users of your AWS
Account who access resources & make changes to them at all times. Changes to all AWS resources need
to be recorded and maintained over a period of 2 years for enabling auditors to perform an analysis
of the data and also store the results of the analysis. The CEO wants a solution that can be
implemented quickly with the highest security & integrity of the stored data. How best would you, as
an Architect, solve this?
A.
Create a CloudTrail trail & send the logs to an S3 bucket to store them securely. Use Athena to
query the logs in S3 and store the results in another S3 bucket
B.
Use the Event History of CloudTrail, download the events to your local machine, and manually query
the required data for a quick and cost-effective solution
C.
Use AWS CloudTrail Lake, configure the duration of storage and the events that need to be captured.
Once configured, use the CloudTrail Lake interface for querying data
D.
Use CloudWatch event rules to capture API requests from AWS resources with SNS Topic notifications.
Subscribe a Lambda function to the SNS Topic which writes the data to S3. Use Athena to Query S3 for
analyzing the data
Correct Answer: C
A traditional way of achieving this is to use CloudTrail for capturing AWS resource changes and
storing the logs in S3. Data encryption, setting up KMS keys, key rotation policies, ensuring log
file integrity, and S3 lifecycle policies for objects are some key considerations for this
solution.
CloudTrail Lake is a fully managed solution for capturing, storing, accessing, and analyzing user &
API-related activity on AWS. It is designed to solve all problems that we have listed above with an
out-of-the-box event History and S3/Athena patterns for storage and query.
- Option A is incorrect. This is the traditional way of storing & accessing logs. Since the CEO
requires a quick solution, efforts are required to set up S3, and encryption; Athena will take a
while for the solution to be actionable.
- Option B is incorrect. Although this is a quick & cost-effective solution, it has certain
constraints like having only 90 days of stored data (Scenario requires data to be stored for 2
years). This is only applicable for management events and manual data search.
- Option C is CORRECT. Using CloudTrail Lake, the organization can easily capture & maintain AWS
resource changes for 2 years. Being a managed service, it has built-in mechanisms for ensuring the
security & integrity of log files.
- Option D is incorrect with similar reasons for setting up S3, Athena. Also, CloudWatch events will
be in near real-time which is not a requirement for the scenario.
Question 38
A company is using S3 as their primary storage of large amounts of financial data that arrives in
the form of documents, images, videos which are highly confidential. This data is produced as a
result of the company executing transactions using its highly modularized microservices architecture
for different financial service domains. They require a monitoring solution that will intelligently
detect malicious activities that can cause a threat to their storage media compromising confidential
data.
Apart from S3, the company would also want its Accounts and other AWS services to be protected from
threats. The solution should also be extremely cost-effective. Which of the following AWS services
can be used for addressing the above requirements?
A.
Use Amazon Guard Duty to continuously monitor S3 events for any suspicious actions
B.
Use Amazon Macie to continuously monitor S3 events
C.
Use CloudTrail to record actions taken by users on S3. Monitor the actions by setting up CloudWatch
logs and alarms
D.
Enable AWS Config rules to monitor compliance changes to S3 resources
Correct Answer: A
- Option A is CORRECT. Amazon GuardDuty is a fully managed and advanced threat detection service
providing broad protection to AWS Accounts and workloads. It helps to identify threats like
attacker
reconnaissance, instance compromise, account compromise, and bucket compromise.
Guard Duty is also intelligent to process only data events that can be used to generate threat
detections, significantly reducing the number of events processed and lowering your costs.
- Option B is incorrect. Although both Amazon Macie & GuardDuty are used for anomaly & threat
detection, Macie is essentially used for protecting sensitive data from unauthorized access in S3.
On the other side, GuardDuty goes beyond that & extends anomaly & threat detection to AWS
accounts &
workloads.
Options C and D are incorrect. CloudTrail/Config does not have the built-in intelligence like
Guard
Duty or Macie towards threat detection.
Question 39
During a compliance review within an organization, the following issues were observed.
All S3 buckets were publicly accessible.
Many of the EC2 instances that are running were overutilized.
The organization would like to understand, manage & remediate these issues in the near future for
different AWS services that they are using. Which of these services will help them do so? (Select
Two)
A.
AWS Guard Duty
B.
AWS Systems Manager
C.
AWS Shield
D.
AWS Security Hub
E.
AWS Inspector
Correct Answers: B and D
AWS Security Hub provides a single place that aggregates, organizes, and prioritizes security alerts
or findings from multiple AWS services. Security Hub continuously monitors your AWS environment
using automated security checks based on AWS security best practices defined by your
organization.
With AWS Systems Manager Ops Center, security findings from Security Hub can be aggregated as
operational issues.
Since the scenario deals with both Security & Operational issues, they can either use both these
services independently or use them in a combined manner to understand, manage & remediate security &
operational concerns.
- Option A is incorrect. Guard Duty is a threat detection service. It can act as a source where data
can be ingested into Security Hub for analysis & remediation.
- Option B is CORRECT. Systems Manager can be used to manage & remediate Operational issues.
- Option C is incorrect. AWS Shield is used to protect applications from Distributed Denial of
Service (DDoS) attacks.
- Option D is CORRECT. Security Hub can be used to manage & remediate Security issues.
- Option E is incorrect. AWS Inspector can act as a source to ingest data into Security Hub for
assessments & remediations related to network accessibility of EC2 instances.
Question 40
Which of the following are the parameters specified in Amazon ECS Service Definition? (Select Three)
A.
Cluster
B.
Capacity provider strategy
C.
Environment Variables
D.
Data Volumes
E.
Client token
Answer: A, B, E
A service definition defines which task definition to use with your service, how many instantiations
of that task to run, and which load balancers (if any) associate with your tasks
Following are some parameters defined in the Service Definition.
Refer to page 616 on the below link:
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/ecs-dg.pdf#service_definition_parameters
References:
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/service_definition_parameters.html
- Option A is Correct The name of the ECS cluster where the service will run.
- Option B is Correct Specifies how the service utilizes capacity providers for resource
allocation.
- Option E is Correct An optional parameter used for idempotency to ensure that repeated requests do
not create duplicate services.
- Option C is incorrect These are defined in the task definition, not in the service
definition.
- Option D is incorrect These are also configured in the task definition, not the service
definition.
Question 41
You are a solution architect in a gaming company and have been tasked to design Infrastructure as
Code (IaC) for one of their online gaming applications. You have decided to use AWS CloudFormation
for this. You create three stacks, e.g., Security Stack, Network Stack, and Application Stack. The
customer has asked you to automate the creation of the Security Group defined in Security Stack for
all the resources in a VPC defined in Network Stacks.
Which of the following CloudFormation features will help you to import values into other stacks and
create cross-stack references?
A.
CloudFormation Outputs
B.
CloudFormation Mappings
C.
CloudFormation Parameters
D.
CloudFormation Conditions
Correct Answer: A
- Option A is CORRECT because the Outputs section declares output values that you can import into
other stacks to create cross-stack references.
- Option B is incorrect because the Mappings section matches a key to a corresponding set of named
values. It cannot be helpful to create cross-stack references.
Example:
- Option C is incorrect because Parameters enables you to input custom values to your template each
time you create or update a stack.
Consider, for example, you want to set InstanceType to t2.micro, t2.medium, or t2.large based on
the
environment like Dev, Test, or Prod.
CloudFormation Parameters are not suitable for the task given in the question.
- Option D is incorrect because CloudFormation Conditions provide statements to create conditions
whenever you want to add, modify, or delete resources.
For example, associate the condition with a property so that AWS CloudFormation only sets the
property to a specific value if the condition is true. If the condition is false, AWS
CloudFormation
sets the property to a different value than you specify.
Question 42
A retail company hosts its e-commerce application in EC2 behind an Application Load Balancer. AWS
RDS is the Database platform.
A popular mobile brand has tied up with the retail company to launch all their flag-ship phones
online using the company’s e-commerce application. You are a solution architect in the company who
manages AWS infra and the e-commerce application.
As the next product launch is due in a week, you have the responsibility to ensure that the existing
AWS RDS Database can withstand write intensive dynamic and virtually infinite load without
increasing the cost significantly. Which solution would you recommend to achieve the requirement?
A.
Vertically scale RDS by increasing RDS instance size and set the RDS storage type as “Provisioned
IOPS”
B.
Migrate RDS data to the DynamoDB tables
C.
Implement the SQS service in front of the RDS to withstand write intensive load on the database
D.
Use Amazon MQ to take the user input and write data to the RDS database
Correct Answer: C
Decoupling message queuing from the database improves database availability. It also provides a more
cost-effective use of the database and works as a long-term solution for write intensive RDS load.
Also, the expected load is Write operations, not Read, so the team does not have to deal with
immediate response to the client. Hence using a message queue using SQS would add better performance
to RDS while under infinite load.
- Option A is incorrect. This solution may be a quick one, but definitely not cost-effective. Also,
with the ASG in place, vertical scaling will escalate the cost and result in downtime. Also, the
nearly/virtually infinite load may not be possible with vertical scaling. Neither operational nor
cost-effective.
- Option B is incorrect even though it is the best solution, this change will take a lot of effort
and
cost to convert and migrate RDS data to the NoSQL DynamoDB tables. This requires a change in the
application code. So very less chance to have this ready within a week.
- Option C is CORRECT because using the SQS queue in front of RDS will prevent direct write
operation
to it. The SQS also scales automatically based on the load; hence the database will be saved from
getting the load directly.
- Option D is incorrect because Amazon MQ is a managed message broker service that makes it easy to
set up and operate message brokers on AWS, not suitable for the given problem statement.
Question 43
To comply with industry regulations, a Healthcare Institute wants to keep their large volume of lab
records in some durable, secure, lowest-cost storage class for an extended period of time (say about
five years). The data will be rarely accessed but requires immediate retrieval (in milliseconds)
when required. As a Solutions Architect, the Institute wants your suggestion to select a suitable
storage class here. Which of the following would you recommend for the given requirement?
A.
Amazon S3 Standard
B.
Amazon S3 Standard-Infrequent Access
C.
Amazon S3 Glacier Instant Retrieval
D.
AWS S3 One Zone-Infrequent Access
Correct Answer: C
- Option A is incorrect because S3 Standard is not a preferred choice of storage for long-term or
archived data. It is costlier among all its S3 storage classes. So, it does not qualify on the
cost
and time.
- Option B is incorrect because Amazon S3 Standard-IA is also not a preferred choice of storage for
long-term or archived data.
- Option C is CORRECT because the Amazon S3 Glacier Instant Retrieval storage class is the
lowest-cost
storage for long-lived data that is rarely accessed that still needs immediate access like online
file-sharing applications, image hosting, etc. It can save up to 68% if the data is retrieved once
in a quarter, compared to S3 Infrequent Access (IA).
- Option D is incorrect because S3 One Zone-IA is a cheaper one, but not quite durable and also not
fit for data archival.
Question 44
Utopia Municipality Corporation runs its application used for the local citizen in EC2 while its
database is still in an on-premise data center. The Organization is adamant about not migrating its
Database to AWS due to regulatory compliances. However, they are willing to extend the database to
the cloud to serve all other AWS services. The organization is looking for a solution by which all
AWS services can communicate seamlessly to their on-premises Database without migrating or hosting
it in the cloud.
You are hired as a Solutions Architect to help the customer achieve this and also ensure a
region-specific, friction-less, low-latency fully managed environment for a truly consistent hybrid
experience.
Which of the following would you recommend?
A.
AWS Outposts
B.
Use AWS Snowball Edge to copy the data and upload to AWS
C.
AWS DataSync
D.
AWS Storage Gateway
Correct Answer: A
- Option A is CORRECT. AWS Outposts delivers AWS infrastructure and services to virtually any
on-premises or edge location that provides a truly consistent hybrid experience. It is a fully
managed solution.
With AWS Outposts, you can run some AWS services locally and connect to a broad range of services
available in the local AWS Region requiring low latency access to on-premises systems, local data
processing, data residency, and application migration with local system interdependencies.
- Option B is incorrect because AWS Snowball Edge is a data migration service that copies
on-premises
data to AWS S3, and the organization is against data migration to AWS. In addition, the
requirement
will not be served through the static data in S3 as this will miss the latest data update in the
on-prem database.
- Option C is incorrect because AWS DataSync is an online data transfer service that simplifies,
automates, and accelerates moving data rapidly over the network into Amazon S3, Amazon EFS, FSx
for
Windows File Server, FSx for Lustre, or FSx for OpenZFS. This will also go against customer
requirements of not having the data migrated to AWS.
- Option D is incorrect because AWS Storage Gateway is fast and easy to deploy, enabling you to
integrate it with your existing environments and access AWS Storage in a frictionless manner.
Storage Gateway is mainly used for moving backups to the cloud, using on-premises file shares
backed
by cloud storage, and providing low-latency access to data in AWS for on-premises applications.
So,
again, it is not suitable as per the customer requirement.
Question 45
A drug research company is receiving sensitive scientific data from multiple sources in different
formats. The organization wants to create a Data Lake in AWS to analyze the data thoroughly. Data
cleansing is a critical step before the data lands in Date Lake, and all the matching data need to
be removed. The solution should also enable secure access to sensitive data using granular controls
at the column, row, and cell levels.
You are hired as a Solutions Architect to help them achieve this in real quick time.
Which of the following do you think would resolve the problem?
A.
Amazon Redshift Spectrum
B.
Amazon Redshift
C.
AWS Glue Data Catalog
D.
AWS Lake Formation
Correct Answer: D
- Option A is incorrect because Amazon Redshift Spectrum is used to query data directly from files
in
S3. This cannot be used to create Data Lake.
- Option B is incorrect because Amazon Redshift is a Data warehouse service and does not satisfy all
the conditions above.
- Option C is incorrect because AWS Glue Data Catalog contains references to data used as sources
and
targets of your extract, transform, and load (ETL) jobs in AWS Glue. The information in the Glue
Data Catalog is used to create and monitor your ETL jobs. This cannot be used to create a Data
Lake.
- Option D is CORRECT because using AWS Lake Formation one can easily set up Data Lakes in days
satisfying all the above conditions. Lake Formation collects and catalogs data from databases and
object storage, moves the data into your new Amazon Simple Storage Service (S3) data lake, uses ML
algorithms to clean and classify the data, and secures access to the sensitive data using granular
controls at the column, row, and cell-levels.
Question 46
A media company is planning to host its relational database in AWS. They want a database from the
RDS family that can handle variable and unpredictable workloads without any manual intervention and
scales compute capacity up and down based on the application’s user traffic.
Which of the following RDS types will fulfill this requirement?
A.
Amazon Aurora
B.
Amazon RDS for MySQL
C.
Amazon Aurora Serverless
D.
Amazon RDS for PostgreSQL
Correct Answer: C
- Option A is incorrect because Amazon Aurora is an advanced RDS offering from AWS to have as a
relational DB, but does not have the capability of on-demand auto-scaling as and when load
increases
or decreases. In this case, Aurora Serverless should be the best choice.
- Option B is incorrect. Amazon RDS for MySQL is a managed database service that makes it easy to
set
up, operate, and scale MySQL deployments in the cloud. While it provides automated backups,
software
patching, and replication, it doesn’t automatically scale compute capacity based on user
traffic.
- Option C is CORRECT because Amazon Aurora Serverless is an on-demand, auto-scaling configuration
for
Amazon Aurora. It automatically starts up, shuts down, and scales capacity up or down based on
your
application's needs. You can run your database on AWS without managing database capacity.
- Option D is incorrect. PostgreSQL has become the preferred open-source relational database for
many
enterprise developers and start-ups, powering leading business and mobile applications. But it
misses the customer requirement of on-demand auto-scaling capability like the one in Aurora
Serverless.
Question 47
A major news broadcasting company needs a solution for a throughput-intensive, high-performance,
low-cost redundant file storage class. This storage will ensure the continuous availability of data
used by several EC2 instances within a region. The data, which is for local advertisements targeted
at a specific availability zone (AZ), can be easily re-created if lost. The redundant data will be
accessed infrequently unless there is a loss or damage to the primary storage. Which storage class
best meets these requirements?
A.
EFS Standard
B.
EFS One Zone
C.
EFS Standard–Infrequent Access (IA)
D.
EFS One Zone-Infrequent Access (IA)
Correct Answer: D
- Option A is incorrect. Even though EFS Standard supports high durability, availability and NFS
protocol, it is not low-cost storage when data is not regularly accessed.
- Option B is incorrect. Though EFS One Zone costs less than EFS Standard, it is not preferred
storage
for a redundant storage model with infrequent access. EFS One Zone IA is a better choice than
this.
- Option C is incorrect because data durability is not the primary requirement in the question as
data
can be re-created if it is lost. So no need to increase the cost for no reason.
- Option D is CORRECT. It is mentioned above that the data can be re-created if it is lost. So, one
Zone should be a good choice in terms of saving some extra dollars. EFS One Zone-IA is designed to
provide continuous availability of data that will not cause much harm if it is lost and can be
re-created. It also reduces storage costs for files that are rarely accessed.
Question 48
A popular media company delivers content on News, Sports and Entertainment to the audiences across
the globe. The company uses AWS Redshift to analyze petabytes of structured and semi-structured data
across their data warehouse, operational database, and Amazon S3 files to activate data-driven
decisions and powerful insights. As their petabyte-scale data continues to grow rapidly, the company
starts facing bottlenecks around network bandwidth and memory processing (CPU) that result in slow
query performance.
As a solution architect in the company, you have to find a solution that will improve the query
performance without increasing the operational overhead and cost. What would you recommend?
A.
Use Amazon S3 Transfer Acceleration to copy the data to a central S3 bucket and then use Redshift
Spectrum for the query purpose
B.
Use Amazon Redshift Spectrum to enhance query performance
C.
Use AQUA (Advanced Query Accelerator) for Amazon Redshift
D.
Enable and configure caching solutions to expedite query performance using Amazon ElastiCache
Memcached
Correct Answer: C
- Option A is incorrect because Amazon S3 Transfer Acceleration is a bucket-level feature that
enables
fast, easy, and secure transfers of files over long distances between your client and an S3
bucket.
Transfer Acceleration is designed to optimize transfer speeds from across the world into S3
buckets.
The objective is to improve the query performance in the existing solution that the customer is
already using, which is Redshift.
- Option B is incorrect because Redshift Spectrum is not a query performance enhancer for data
stored
in Redshift. It is used for querying data directly in S3 files.
- Option C is CORRECT because Advanced Query Accelerator or AQUA for Redshift meets all the above
requirements. Using AQUA, customers can boost the query performance by 10X. It resolves network
bandwidth and memory processing (CPU) bottleneck, low cost, and is easy to deploy.
- Option D is incorrect because in-memory caching can boost the query performance and query results
can be retrieved from low latency and high throughput in-memory data stores. It does not satisfy
the
cost and low operational overload factor here.
Question 49
A major health care institution is looking for a solution to store their files in the cloud to
achieve high availability, durability, elasticity, and lower storage cost. The storage must support
the Network File System version 4 (NFSv4.1 and NFSv4.0) protocol. These files in the cloud storage
will mainly be used by Auditor once in a while.
Which of the below best suits this requirement?
A.
EFS Standard
B.
EFS One Zone
C.
EFS Infrequent Access (IA)
D.
EFS One Zone-Infrequent Access (IA)
Correct Answer: C
- Option A is incorrect. Even though EFS Standard supports high durability, availability and NFS
protocol, it is not low-cost storage when data is not regularly accessed.
- Option B is incorrect because EFS One zone is less durable and available.
- Option C is CORRECT because EFS Infrequent Access (IA) suits low cost, high availability, high
durability, elasticity, and Network File System version 4 (NFSv4.1 and NFSv4.0) protocol
perfectly.
- Option D is incorrect because EFS One Zone-IA is less available and durable than EFS
Standard–Infrequent Access (IA).
Question 50
An organization runs nearly 500 EC2 instances in several accounts across regions.
These EC2 instances are built on custom Amazon Machine Images (AMIs). The organization is concerned
about the accidental deletions of AMIs used for production EC2 instances. They want a solution that
can help them recover from accidental deletions as soon as they know about it.
Which of the following can be used for the above scenario?
A.
Use Recycle Bin
B.
Use Cloudformation StackSets
C.
Use Elastic Beanstalk
D.
Take a snapshot of the EBS volume attached to all EC2 and later use it to restore the AMIs
Correct Answer: A
- Option A is CORRECT. Recycle Bin, a data recovery feature, is a new feature introduced by AWS that
enables one to restore accidentally deleted Amazon EBS snapshots and EBS-backed AMIs. If your
resources are deleted, they are retained in the Recycle Bin for a time period that you specify
before being permanently deleted.
- Option B is incorrect because AWS CloudFormation StackSets extends the capability of stacks by
enabling you to create, update, or delete stacks across multiple accounts and AWS Regions with a
single operation. It is never meant to be used to recover a lost asset/service.
- Option C is incorrect because AWS Elastic Beanstalk is an easy-to-use service for deploying and
scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go,
and
Docker on familiar servers such as Apache, Nginx, Passenger, and IIS. It is not any feature of EC2
which will be used to recover deleted AMIs.
A snapshot of the EBS volume may be a possible solution, but it involves a good amount of
operational steps of backup and restore. Hence, - Option D is incorrect.
Question 51
You are a solutions architect in a gaming company. The customer has asked you to design
Infrastructure as Code (IaC) for one of their applications. You have decided to use AWS
CloudFormation for this. The customer has asked you to build the infrastructure so that all the EC2
instances are created out of their predefined Amazon Machine Images (AMIs) set based on a region.
Which of the below CloudFormation features will help you satisfy the customer requirement?
A.
CloudFormation Outputs
B.
CloudFormation Mappings
C.
CloudFormation Parameters
D.
CloudFormation Conditions
Correct Answer: B
- Option A is incorrect because the Outputs section declares output values that you can import into
other stacks to create cross-stack references or return in response to describe stack calls. For
example, you can output the S3 bucket name for a stack to make the bucket easier to find.
- Option B is CORRECT. Using Mappings, you can set AMI values based on a region. In CloudFormation,
you can create a mapping that uses the region name as a key and contains the values.
For example, if you want to set values based on a region, you can create a mapping that uses the
region name as a key and contains the values you want to specify for each specific region. You use
the Fn::FindInMap intrinsic function to retrieve values in a map.
- Option C is incorrect because Parameters enable you to input custom values to your template each
time you create or update a stack.
Consider, for example, you want to set InstanceType to t2.micro, t2.medium, or t2.large based on
the
environment like Dev, Test, or Prod.
CloudFormation Parameters are not suitable for the task given in the question.
- Option D is incorrect because CloudFormation Conditions provides statements to create conditions
whenever you want to add, modify, or delete resources.
For example, associate the condition with a property so that AWS CloudFormation only sets the
property to a specific value if the condition is true. If the condition is false, AWS
CloudFormation
sets the property to a different value than what you specify.
Mapping is a better choice for the requirement given in the question.
Question 52
You are the Solutions Architect of an organization that runs 100 of modern EC2 instances in a
production environment. To avoid non-compliance, you must immediately update the packages on all the
production EC2 instances. There is a DevSecOps team who is in charge of security group policies used
in those EC2, has the SSH access disabled in the security group policy. When you reached them to get
the SSH enabled, they denied that.
Which of the below options will help you to roll out the package for all the EC2 instances despite
having the above restrictions from the DevSecOps team?
A.
Use AWS Config to roll out the package all at once and install it in EC2 instances
B.
Get the System Manager role added to your IAM roles and use Systems Manager Run Command to roll out
the package installation
C.
Get the System Manager role added to your IAM roles and use System Manager Session Manager to SSH
into the EC2s from browser mode to install the package
D.
Get the user credentials of one of the Security members to SSH into the EC2 instance and proceed
with package installation
Correct Answer: B
- Option A is incorrect because AWS Config is used to monitor configuration changes of your AWS
resources. For example, someone disables the CloudTrail log, deletes an account from an OU, etc.
AWS
Config also enables you to simplify compliance auditing, security analysis, change management, and
operational troubleshooting. Hence, AWS Config is not a solution to install packages in EC2
instances.
- Option B is CORRECT because once the user has the suitable IAM SSM role, AWS System manager Run
Command can be used to remotely run commands, like update packages, on all the EC2 instances. One
can use Run Command from the AWS Management Console, AWS Command Line Interface (AWS CLI), AWS
Tools
for Windows PowerShell, or the AWS SDKs with no extra cost.
- Option C is incorrect because this method requires you to manually connect to each of the EC2
instances individually, which would result in a lot of time and effort to patch all 100 EC2
instances. Hence, this option can be easily neglected.
- Option D is incorrect because AWS never encourages sharing of credentials and it can be treated as
a
security violation.
Question 53
A document management company has an application A that sends a file to application B in their AWS
account. These are classified files from the defense department. The organization wants the file to
be digitally signed so that the receiving application B can verify that it hasn’t been tampered with
in transit.
The organization also wants to ensure only application A can digitally sign files using the key
because they don’t want application B to receive a file thinking it’s from application A when it was
from a different sender that had access to the signing key. As a solution architect in the company,
you are offering a solution with AWS KMS. Which of these encryption types will satisfy the customer
requirement?
A.
Asymmetric KMS Keys
B.
AWS CloudHSM
C.
Symmetric KMS Keys
D.
Customer managed keys
Correct Answer: A
- Option A is CORRECT because the Asymmetric KMS Keys represent a mathematically related RSA or
elliptic curve (ECC) public and private key pair. The private key never leaves AWS KMS
unencrypted.
Asymmetric keys are used for digital signature applications such as trusted source code,
authentication/authorization tokens, document e-signing, e-commerce transactions, and secure
messaging.
- Option B is incorrect. AWS CloudHSM is a dedicated, hardened, and tamper-resistance computing
device
designed to manage securely, process, and store digital keys. These devices are directly attached
to
a computer or a network server. One can configure AWS KMS to use the AWS CloudHSM cluster as a
custom key store to enable top-notch security. AWS CloudHSM does not relate to the above scenario.
In this case, one can use CloudHSM to store the Asymmetric key by which the digital sign has been
performed, but cannot provide digitally signing capabilities.
- Option C is incorrect because Symmetric KMS Keys are the default encryption type in AWS KMS and do
not offer digital sign verification capability.
- Option D is incorrect because Customer managed keys are KMS keys in an AWS account that the
customer
creates, owns, and manages. The customer has full control over these KMS keys, including
establishing and maintaining their key policies, IAM policies, grants, etc. Customer-managed keys
do
not support digital signature verification.
Question 54
A Pharmaceutical company wants to apply encryption all through the lifecycle of their data generated
by the drug research team. Initially, the data will be stored in S3; then, the same will be
processed by some filtering logic written in the AWS Lambda function. Finally, it will be stored in
DynamoDB tables. All these AWS services integrate with AWS KMS. Hence, the customer is exploring
options to create an Encryption Key using KMS that should be a 256-bit encryption key that never
leaves AWS KMS unencrypted. Additionally, they want to use the same key for encryption and
decryption without any ownership of the KEY.
Which type of encryption key should be applied to the data in this scenario?
A.
Asymmetric KMS Keys
B.
AWS CloudHSM
C.
Symmetric KMS Keys
D.
Customer managed key
Correct Answer: C
- Option A is incorrect because the services used here like S3, Lambda, DynamoDB, etc integrate with
KMS, and only symmetric encryption KMS key can be used here to encrypt the data. These services do
not support encryption with asymmetric KMS keys. Also, the requirement of having the same 256-bit
encryption key to encrypt and decrypt the data indicates a Symmetric KMS Key. An asymmetric KMS
key
represents a mathematically related public key and private key. The private key never leaves AWS
KMS
unencrypted. You can create asymmetric KMS keys that represent RSA key pairs for public-key
encryption or signing and verification or elliptic curve key pairs for signing and
verification.
- Option B is incorrect because AWS CloudHSM is a cloud-based hardware security module that enables
you to easily generate and use your own encryption keys on the AWS Cloud. With CloudHSM, you can
manage your own encryption keys using FIPS 140-2 Level 3 validated HSMs. In this scenario, the
customer does not want to own the KEY.
- Option C is CORRECT because the services used here like S3, Lambda, DynamoDB, etc integrate with
KMS, and only symmetric encryption KMS key can be used here to encrypt the data. Also, the
requirement of having the same 256-bit encryption key to encrypt and decrypt the data indicates a
Symmetric KMS Key.
- Option D is incorrect because Customer managed keys are the KMS keys in an AWS account that is
created, owned, and managed by the customer. Based on the question, the Customer does not want to
take any ownership or manage the data security. Hence, this option is ruled out.
Question 55
A scientific research team is using EBS as storage for their highly sensitive documents to be
processed by EC2 instances for some scientific experiment. The team wants to manage their own keys
and also ensure the highest level of security for their documents.
Which of the following AWS features would you recommend as a Solutions Architect?
A.
Amazon EBS encryption with AWS Managed Keys
B.
Policies and permissions in AWS IAM
C.
AWS Config
D.
Amazon EBS encryption with Customer Managed Keys
Correct Answer: D
- Option A is incorrect because there's a chance that even AWS Managed keys can get compromised and
be
used to decrypt the data and read the documents. Certainly, this is not the highest level of
security that the research team is asking for.
- Option B is incorrect because the IAM policy can manage user access and prevent unauthorized users
from accessing the document. If the document is compromised, there is hardly anything that IAM
policy can do to prevent it from being read.
- Option C is incorrect because AWS Config is not an encryption or data security service in AWS. AWS
Config is a service that enables you to assess, audit, and evaluate the configurations of your AWS
resources.
- Option D is CORRECT because it is the customer who creates, owns, and manages the Customer managed
keys in the AWS account. One has full and granular level control over these KMS keys, including
establishing and maintaining their key policies, IAM policies, grants, etc which enables native
encryption functionality.
In this case, one can use a customer-managed key with imported key material where the customer
owns
the original copy of the key material and keeps it outside of AWS for additional durability and
disaster recovery during the complete lifecycle of the key material.
Question 56
A private bank is planning to use Amazon RDS as a database for its banking application. Data Files
and backups for this database will be managed by a third-party vendor. Security Head wants you to
ensure sensitive data is encrypted at rest in the database without any additional changes in the
application. Cryptographic keys used for this encryption should be securely stored in a single
tenant hardware module.
Which database design can suffice these security requirements?
A.
Deploy Oracle on Amazon RDS with Transparent Data Encryption enabled. Use AWS CloudHSM to store all
keys
B.
Deploy MariaDB on Amazon RDS with Transparent Data Encryption enabled. Use AWS CloudHSM to store all
keys
C.
Deploy Microsoft SQL server on Amazon RDS with Transparent Data Encryption enabled. Use AWS KMS to
store all keys
D.
Deploy PostgreSQL on Amazon RDS with Transparent Data Encryption enabled. Use AWS KMS to store all
keys
Correct Answer: A
Amazon RDS supports TDE (Transparent Data Encryption) with Oracle and SQL servers. With TDE, data is
automatically encrypted before it is written to storage and automatically decrypted when data is
read from the storage. TDE in Oracle can be integrated with AWS CloudHSM which can securely store,
generate, and manage cryptographic keys in a single-tenant Hardware security module.
- Option B is incorrect as MariaDB on Amazon RDS does not support TDE (Transparent Data
Encryption).
- Option C is incorrect as using AWS KMS will not provide a single tenant HSM (Hardware Security
module) within AWS Cloud.
- Option D is incorrect as PostgreSQL on Amazon RDS does not support Transparent Data Encryption.
AWS
KMS will not provide a single tenant HSM (Hardware Security module) within AWS Cloud.
Question 57
A critical web application is deployed on an Amazon EC2 instance. ELB (Elastic Load Balancer) is
deployed in front of this Amazon EC2 instance to load balance incoming traffic. The security team is
looking for the maximum level of protection for this application from DDoS attacks, and it
customized mitigations during attacks. The Operations Team should get near real-time visibility for
the complex attacks on this application.
What secure solution can be deployed for this purpose?
A.
Enable Amazon GuardDuty in an account where Amazon EC2 instances are launched. Use Amazon Detective
to get real-time visibility for complex attacks
B.
Enable AWS Shield Advanced protection on ELB. Use AWS WAF to create a proactive rule to mitigate
application attacks
C.
Use AWS Shield Standard to detect DDoS attacks on Amazon EC2 Instance. Use AWS WAF to create a
proactive rule to mitigate application attacks
D.
Use Amazon Inspector to detect DDoS attacks on Amazon EC2 Instance. Use Amazon Detective to get
real-time visibility for complex attacks
Correct Answer: B
AWS Shield Advanced provides a higher level of protection against DDoS attacks on AWS resources such
as Amazon EC2, ELB, Amazon CloudFront, AWS Global Accelerator, and Amazon Route 53.
It provides real-time visibility for the attacks and can be integrated with AWS WAF to create
proactive rules against these attacks. With AWS Shield Advanced, AWS Shield Response Team (SRT) is
engaged with the customer to monitor and detect attacks on the resources proactively.
AWS Shield Standard is automatically enabled for AWS resources while AWS Shield Advanced needs to be
enabled on resources like Elastic IP, Elastic Load Balancing (ELB), Amazon CloudFront, AWS Global
Accelerator, and Amazon Route 53.
- Option A is incorrect as Amazon GuardDuty is a threat detection service that analyses events from
various AWS sources such as AWS CloudTrail event logs, Amazon VPC flow Logs, and DNS query logs.
Amazon GuardDuty cannot be used to protect applications from DDoS attacks. Amazon Detective
analyses
logs from various AWS security services like Amazon GuardDuty, Amazon Macie, and AWS Security Hub
to
get to the root cause of the security issues.
- Option C is incorrect as AWS Shield Standard does not provide near real-time visibility for the
attacks. AWS Shield Response Team (SRT) is not engaged with AWS Shield Standard to proactively
create AWS WAF rules to mitigate DDoS attacks on applications. AWS WAF rules need to be updated by
the customers in the case of AWS Shield.
- Option D is incorrect as Amazon Inspector can be used for vulnerability management which evaluates
Amazon EC2 instances for any software vulnerability or network exposure. It is not suitable to
protect applications on an Amazon EC2 instance from DDoS attacks. Amazon Detective analyses logs
from various AWS security services like Amazon GuardDuty, Amazon Macie, and AWS Security Hub to
get
to the root cause of the security issues.
Question 58
A start-up company is using AWS CloudFormation templates to deploy software on Amazon EC2 instances.
Developers are looking for an option to read metadata from the CloudFormation template and start
software package installation on the Amazon EC2 instance.
Which of the following scripts can be executed directly from AWS CloudFormation templates for this
purpose?
A.
Use cfn-hup helper script to read template metadata and install the packages
B.
Use cfn-signal helper script to read template metadata and install the packages
C.
Use cfn-get-metadata helper script to read template metadata and install the packages
D.
Use cfn-init helper script to read template metadata and install the packages
Correct Answer: D
The cfn-init helper script is used to retrieve and interpret resource metadata from the AWS::
CloudFormation::Init key. After reading the metadata, this script performs the following
actions,
Fetch and parse metadata from CloudFormation.
Install packages.
Write files to disk.
Enable/disable and start/stop services.
- Option A is incorrect as the cfn-hup helper script checks for any updates to the metadata. If
there
are any changes, it executes custom hooks.
- Option B is incorrect as the cfn-signal helper script can be used to signal CloudFormation to
indicate if software or application is successfully updated on an Amazon EC2 instance.
- Option C is incorrect as the cfn-get-metadata helper script helps to retrieve metadata for a
resource to a specific key. This will not install services or start services that the cfn-init
helper script can perform.
Question 59
A web-application deployed on Amazon EC2 Instance launched in VPC A needs to connect with AWS KMS
for data encryption. This traffic should preferably flow over the AWS network. Access to the AWS KMS
keys should be controlled by granting permissions only to specific entities and ensuring the least
privileged security practice is followed. The proposed solution should be cost-effective and should
be set up effectively.
What design can be proposed?
A.
Deploy a firewall proxy server on an Amazon EC2 instance for internet access to AWS KMS. Create
policies on proxy servers to control access to AWS KMS only from the Instance IP address
B.
Attach a NAT Gateway to VPC A to access AWS KMS. Create a Network ACL allowing communication with
AWS KMS only from the Instance IP address
C.
Create a VPC endpoint from VPC A for AWS KMS. Create a key policy matching ‘aws: SourceVpc’
condition key which will match VPC A
D.
Create a VPC endpoint from VPC A for AWS KMS. Create a key policy matching ‘aws: SourceVpce’
condition key which will match VPC endpoint ID
Correct Answer: D
Using AWS VPC endpoints, AWS KMS can be accessed from the resources within the VPC with traffic
flowing over AWS Network. This ensures connectivity to avoid the internet for accessing AWS KMS
keys.
With VPC endpoints, access control can be restricted by AWS KMS key policies that can match either
VPC endpoint ID or VPC ID. Access to AWS KMS keys can be controlled by the AWS KMS Key policy and
AWS IAM policy.
For the above scenario, a VPC endpoint can be created to access AWS KMS from an application within a
VPC. To grant permission only for specific entities, AWS KMS key policy can be created to match VPC
endpoint ID which will allow access only from the specific VPC endpoint.
- Option A is incorrect as an additional firewall proxy will incur additional costs. Also, with a
firewall proxy, all traffic to AWS KMS will be over the internet.
- Option B is incorrect as traffic to AWS KMS will flow over the Internet with NAT Gateway. Based on
the question, traffic to AWS KMS should flow over the AWS network.
- Option C is incorrect as the Key policy with a condition as aws:sourceVPC will allow all the
access
to AWS KMS keys from all the VPC endpoints created in this VPC. If control is required from only a
specific endpoint, this policy is not suitable.
Question 60
A startup firm has a large number of application servers hosted on VMs (virtual machines) associated
with VMware vCenter at the on-premises data center. Each of these VMs has different operating
system. They are planning to host these servers in the AWS Cloud. For estimating Amazon EC2 sizing
in the AWS Cloud, the IT Team is looking for resource utilization from on-premises servers which
should include key parameters like CPU, disk, memory, and network throughput. This data should be
saved in an encrypted format and shared with the SME (Subject Matter Expert) working on this
migration.
Which method is best suited to get these server details?
A.
Use Agentless-discovery method with AWS Application Discovery Service
B.
Use Agentless-discovery method with AWS Application Migration Service
C.
Use Agent-based discovery method with AWS Application Migration Service
D.
Use Agent-based discovery method with AWS Application Discovery Service
Correct Answer: A
AWS Application Discovery Service collects data from existing servers on-premises which can be used
by the customers to understand server configurations, usage, and behavior. It gathers various server
parameters such as CPU, disk, memory, and network throughput (average number of bytes read and
written). This collected data is encrypted in transit as well as at rest. These parameters can be
discovered in any of the following two ways.
Agentless Discovery: This is suited for VMware hosts. With this method, an OVA (Open Virtual
Appliance) needs to be deployed on a VM host associated with VMware vCenter. No additional software
is required to discover the required parameters. This agent can collect the required information
irrespective of the operating systems installed on the VMs.
Agent-based Discovery: Agent-based discovery is suitable for collecting data for hosts other than
VMware hosts. With this, agents are deployed on machines having Windows, Linux, Ubuntu, CentOS, and
SUSE operating systems.
- Option B is incorrect as AWS Application Migration Service performs migration of the application
from on-premises to AWS Cloud. It’s not the service to identify server parameters such as CPU, and
memory of the on-premises servers. For migrating VMware hosts to the Amazon EC2 instance, the AWS
Server Migration Service Connector can be used.
- Option C is incorrect as AWS Application Migration Service performs migration of the application
from on-premises to AWS Cloud. It’s not the service to identify server parameters such as CPU, and
memory of the on-premises servers.
- Option D is incorrect as Agent-based discovery with AWS Application Discovery Service is best
suited
for VMs and physical servers having Windows and Linux operating systems. For VMs associated with
vCentre, Agentless discovery is the best option, not an agent-based discovery method.
Question 61
A company has SQL Servers at the on-premises location which they are planning to migrate to AWS
Cloud. This migration should be non-disruptive with minimal downtime. Prerequisite tests should be
performed, and results should be captured before servers in AWS are elevated as primary servers.
What cost-effective automated tool can be used to perform SQL server migration?
A.
AWS Migration Hub API.
B.
AWS Application Migration Service
C.
AWS DataSync
D.
AWS Application Discovery Service
Correct Answer: B
AWS Application Migration Service can be used to migrate on-premises servers to AWS. It supports
applications such as SAP, Oracle, and SQL server migrations to AWS Cloud. While using AWS
Application Migration Service, there is no need to have any application-specific experts perform
migration or have multiple migration solutions to be designed.
This allows us to save costs while migrating critical applications to the cloud. With AWS
Application Migration Service, data from source servers is first replicated to AWS. Post data is
replicated to AWS; tests are performed to ensure application performance from the AWS cloud, and
once tests are passed, cutover is performed. This ensures a small cutover window without any
disruption to application performance.
- Option A is incorrect as AWS Migration Hub API can be used to track the migration activity
performed
by each of these tools. This API cannot be used to migrate SQL Server from on-premises to
AWS.
- Option C is incorrect as AWS DataSync can be used to migrate data from on-premises to one of the
AWS
storage services. This service cannot be used to migrate SQL Server from on-premises to AWS.
- Option D is incorrect as AWS Application Discovery Service helps plan cloud migration by gathering
information about the on-premises data centers.
Question 62
A finance company is using Amazon S3 to store data for all its customers. During an annual audit, it
was observed that sensitive data is stored by some of the customers. Operations Head is looking for
an automated tool to scan all data in Amazon S3 buckets and create a report based on the findings
from all the buckets with sensitive data.
Which solution can be designed to get the required details?
A.
Enable Amazon GuardDuty on the Amazon S3 buckets
B.
Enable Amazon Detective on the Amazon S3 buckets
C.
Enable Amazon Macie on the Amazon S3 buckets
D.
Enable Amazon Inspector on the Amazon S3 buckets
Correct Answer: C
Amazon Macie uses machine learning and pattern matching to discover, monitor, and protect sensitive
data stored in Amazon S3 buckets.
Once Amazon Macie is enabled on the Amazon S3, it first generates an inventory of S3 buckets. It
automatically discovers and reports any sensitive data stored in an Amazon S3 bucket by creating and
running sensitive data discovery jobs. It further provides a detailed report for any findings with
respect to the sensitive data. These jobs can be initiated at periodic intervals or just once
on-demand basis.
- Option A is incorrect as Amazon GuardDuty protects against the use of compromised credentials or
unusual access to Amazon S3. It does not scan data in Amazon S3 buckets to find any sensitive data
stored in it.
- Option B is incorrect as Amazon Detective analyses and visualizes security data from AWS security
services such as Amazon GuardDuty, Amazon Macie, and AWS Security Hub to get the root cause of the
potential security issues. It does not scan data in Amazon S3 buckets to find any sensitive data
stored in it.
- Option D is incorrect as Amazon Inspector evaluates Amazon EC2 instance for any software
vulnerability or network exposure. It does not scan data in Amazon S3 buckets to find any
sensitive
data stored in it.
Question 63
You are working in a College as a Cloud Technical Advisor, and your college was maintaining all its
data locally where they felt security and redundancy issues. So, you suggested deploying the
application in AWS and use a NoSQL database for their database. While deploying the servers in AWS,
the team needs your suggestion for creating new Security Groups. Can you select which of the
following Option given by the team is true? (Select 2)
A.
Security Group supports “allow rules” and “deny rules”.
B.
The default rules in a security group disallows all incoming traffic.
C.
By default, the Security group allows all outbound
D.
NACL is the first layer of security.
Correct Answer - B and C
- Option A is incorrect because the Security Group supports allow rules only. To deny rules, Network
ACLs should be used.
- Option B is CORRECT because, by default, custom SG has no Inbound rules.
- Option C is CORRECT because, by default, all Outgoing Traffic is allowed in the custom Security
Group.
- Option D is incorrect because Network Access Control List is not the first layer of security, it
is
always the additional layer of security.
Question 64
An e-commerce company is planning to build an application for identifying site visitors based upon
prior site visits. The database should query large amounts of site visit data from Amazon S3 and
create a graph database. The company is looking for a fully managed high-performance database for
this requirement. Additionally, this database should be deployed in an isolated environment.
Which database can be selected to meet the requirements?
A.
Use Amazon Neptune
B.
Use Amazon DynamoDB
C.
Use Amazon Aurora Serverless
D.
Use Amazon RDS
Correct Answer: A
Amazon Neptune can be used to create graph databases that query large amounts of data. Amazon
Neptune is a fully managed and highly available database. In case of failure, Amazon Neptune
failovers to any of the 15 read Replicas created in three Availability zones. If no read replicas
are created, Amazon Neptune creates a new database instance in case of failure.
It fetches data in CSV and RDF format from Amazon S3 buckets.
- Option B is incorrect as Amazon DynamoDB is a key-value database for high-traffic web
applications,
gaming applications, and e-commerce applications. It is not a suitable option for a graph
database.
- Option C is incorrect as Amazon Aurora Serverless is an on-demand autoscaling database that
configures the Amazon Aurora database as per the capacity specified. It is not a suitable option
for
a graph database.
- Option D is incorrect as Amazon RDS is a relational database for traditional applications, ERP (
Enterprise Resource Planning) applications, and CRM (Customer Relationship Management)
applications.
Question 65
A wildlife conservation organization needs to analyze images from camera traps to identify and count
different animal species in a protected area. These images are stored in an Amazon S3 bucket. The
organization aims to monitor wildlife populations and track changes over time.
Which approach can be initiated to meet this requirement?
A.
Copy all the images from Amazon S3 buckets to Amazon Rekognition. Use the Object and Scene Detection
feature of Amazon Rekognition to identify and count different animal species in the images
B.
Point Amazon Rekognition to Amazon S3 buckets that contain images. Use the Object and Scene
Detection feature of Amazon Rekognition to identify and count different animal species in the images
C.
Copy all the images from Amazon S3 buckets to Amazon Rekognition. Use the facial analysis feature of
Amazon Rekognition to find the gender and emotions of the person in the images
D.
Point Amazon Rekognition to Amazon S3 buckets that contain images. Use the Facial Recognition
feature of Amazon Rekognition to fetch the gender and emotions of the person in the images
Correct Answer: B
Amazon Rekognition can be used along with applications that can search, verify, and organize
millions of images or videos. Face Analysis with Amazon Rekognition can be used to detect a face
from an image and retrieve relevant face attributes from that image. Face Attributes are as
follows:
Gender
Smile
Emotions
Eyeglasses
Sunglasses
Eyes open
Mouth open
Mustache
Beard
Pose
Quality
Face landmarks
- Option A is incorrect because it is not necessary to copy all images from Amazon S3 to Amazon
Rekognition to analyze images using Amazon Rekognition. The facial Recognition feature identifies
a
person's face from a collection of faces. It does not extract face attributes such as gender or
emotions of a person from the image.
- Option C is incorrect because it is not necessary to copy all images from Amazon S3 to Amazon
Rekognition to analyze them using Amazon Rekognition. Face Comparison will compare images to check
if the images are of the same person or a different person.
- Option D is incorrect as Object and Scene Detection is a feature that analyses an image or video
to
assign labels based upon its visual contents. It does not detect faces or extract face attributes
such as gender or emotions of a person from the image.

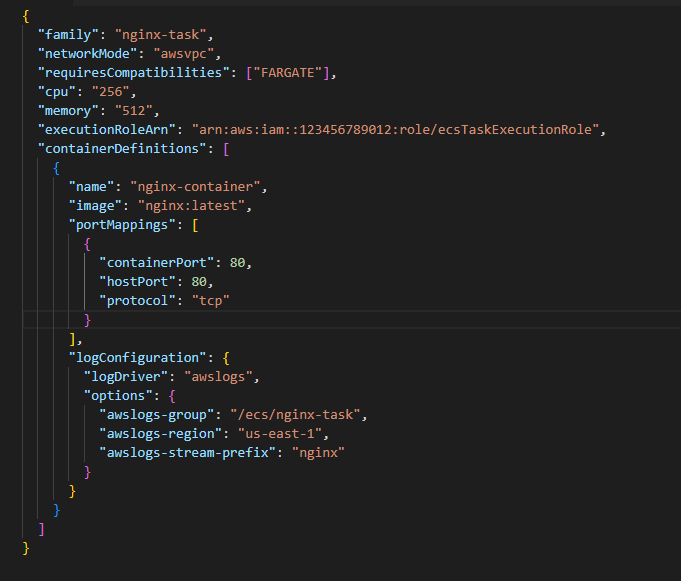 For more information on how to create task definitions, refer to the documentation here.
For more information on how to create task definitions, refer to the documentation here.
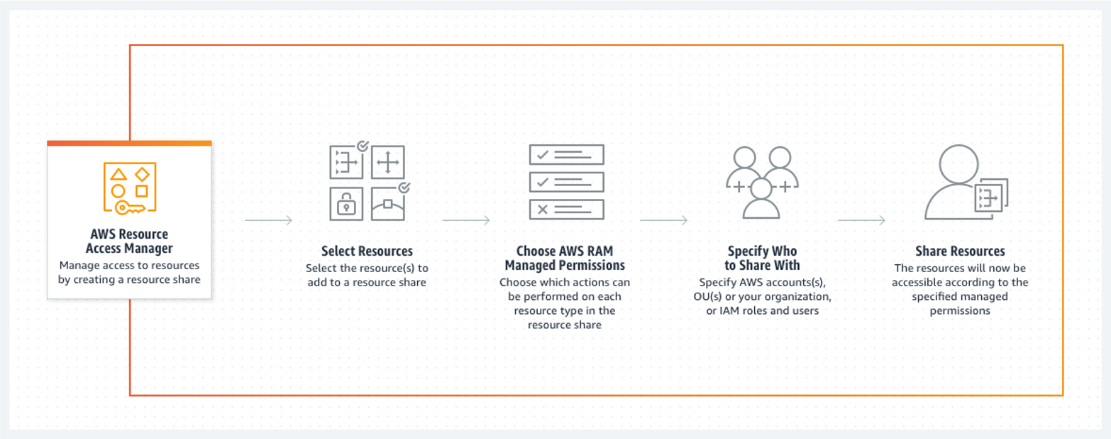 - Option A is incorrect as Resource-based policies are used to specify users who can access
resources
and what actions they can perform on the specified resources. These policies cannot be used to
share
resources with AWS Organizations.
- Option B is incorrect as Resource-based policies are used to specify users who can access
resources
and what actions they can perform on the specified resources. These policies cannot be used to
share
resources with AWS Organizations. These policies are attached to the resources irrespective of the
member or management accounts.
- Option D is incorrect as the Resource Access Manager can be used to share resources with the
member
accounts, and there is no need to share with the management account.
- Option A is incorrect as Resource-based policies are used to specify users who can access
resources
and what actions they can perform on the specified resources. These policies cannot be used to
share
resources with AWS Organizations.
- Option B is incorrect as Resource-based policies are used to specify users who can access
resources
and what actions they can perform on the specified resources. These policies cannot be used to
share
resources with AWS Organizations. These policies are attached to the resources irrespective of the
member or management accounts.
- Option D is incorrect as the Resource Access Manager can be used to share resources with the
member
accounts, and there is no need to share with the management account.
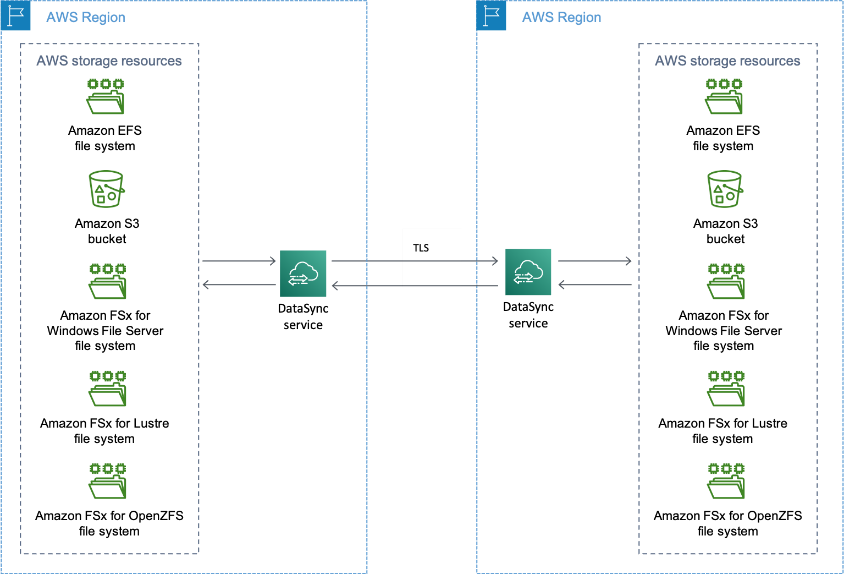 - Option A is incorrect as this would lead to additional admin work and incur charges for data
storage
in the Amazon S3 bucket.
- Option B is incorrect as open-source tools will incur additional costs.
- Option D is incorrect as using snowball would be suitable for transferring a large amount of data.
It would be a more costly option than using AWS DataSync for recurring data transfer.
- Option A is incorrect as this would lead to additional admin work and incur charges for data
storage
in the Amazon S3 bucket.
- Option B is incorrect as open-source tools will incur additional costs.
- Option D is incorrect as using snowball would be suitable for transferring a large amount of data.
It would be a more costly option than using AWS DataSync for recurring data transfer.
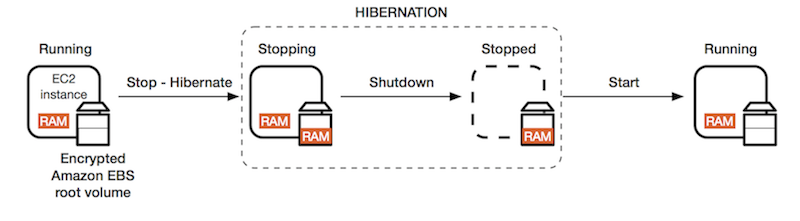 - Option A is incorrect as creating a new Amazon EC2 instance from an AMI store in the Amazon S3
bucket will delay bringing the application to the production level.
- Option C is incorrect as Rebooting the Amazon EC2 instance will take time to initialize all the
applications back to the production level.
- Option D is incorrect as storing RAM data to the Amazon EBS will not speed up the application
initialization process. Rebooting the Amazon EC2 instance will take time to bring a
memory-intensive
application to the production level.
- Option A is incorrect as creating a new Amazon EC2 instance from an AMI store in the Amazon S3
bucket will delay bringing the application to the production level.
- Option C is incorrect as Rebooting the Amazon EC2 instance will take time to initialize all the
applications back to the production level.
- Option D is incorrect as storing RAM data to the Amazon EBS will not speed up the application
initialization process. Rebooting the Amazon EC2 instance will take time to bring a
memory-intensive
application to the production level.
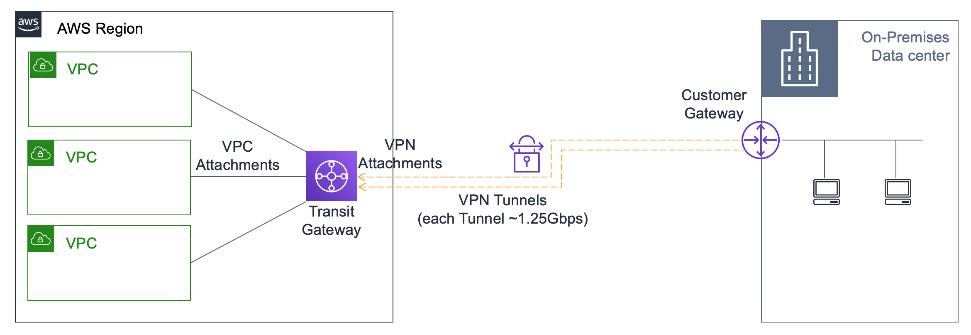 - Option B is incorrect as Virtual Private Gateway does not support ECMP-enabled VPN
connections.
- Option C is incorrect as multiple VPN connections to multiple Transit gateway will lead to
additional admin load for managing these tunnels. Also, without ECMP support, each VPN tunnel will
have a throughput limited to 1.25 Gbps. Dynamic Routing without ECMP will not increase total
throughput.
- Option D is incorrect as multiple VPN connections to multiple Virtual Private Gateway will lead to
additional admin for managing these tunnels. Also, without ECMP support, each VPN tunnel will have
a
throughput limited to 1.25 Gbps.
- Option B is incorrect as Virtual Private Gateway does not support ECMP-enabled VPN
connections.
- Option C is incorrect as multiple VPN connections to multiple Transit gateway will lead to
additional admin load for managing these tunnels. Also, without ECMP support, each VPN tunnel will
have a throughput limited to 1.25 Gbps. Dynamic Routing without ECMP will not increase total
throughput.
- Option D is incorrect as multiple VPN connections to multiple Virtual Private Gateway will lead to
additional admin for managing these tunnels. Also, without ECMP support, each VPN tunnel will have
a
throughput limited to 1.25 Gbps.
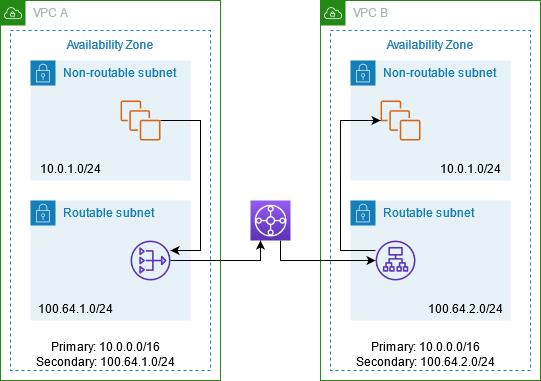 - Option A is incorrect as the Public NAT gateway is used to connect to the Internet. For Inter-VPC
overlapping subnet communications, Private NAT Gateway needs to be used. With PrivateLinks, both
interface endpoints need to be created for bi-directional communication which will require
additional admin work.
- Option C is incorrect as VPC peering cannot be established even if any one of the VPC subnets will
be overlapping with subnets in another VPC.
- Option D is incorrect as the Public NAT gateway is used to connect to the Internet. For Inter-VPC
overlapping subnet communications, Private NAT Gateway needs to be used. AWS Managed VPN would be
over public Internet links and not over AWS managed network infrastructure.
- Option A is incorrect as the Public NAT gateway is used to connect to the Internet. For Inter-VPC
overlapping subnet communications, Private NAT Gateway needs to be used. With PrivateLinks, both
interface endpoints need to be created for bi-directional communication which will require
additional admin work.
- Option C is incorrect as VPC peering cannot be established even if any one of the VPC subnets will
be overlapping with subnets in another VPC.
- Option D is incorrect as the Public NAT gateway is used to connect to the Internet. For Inter-VPC
overlapping subnet communications, Private NAT Gateway needs to be used. AWS Managed VPN would be
over public Internet links and not over AWS managed network infrastructure.
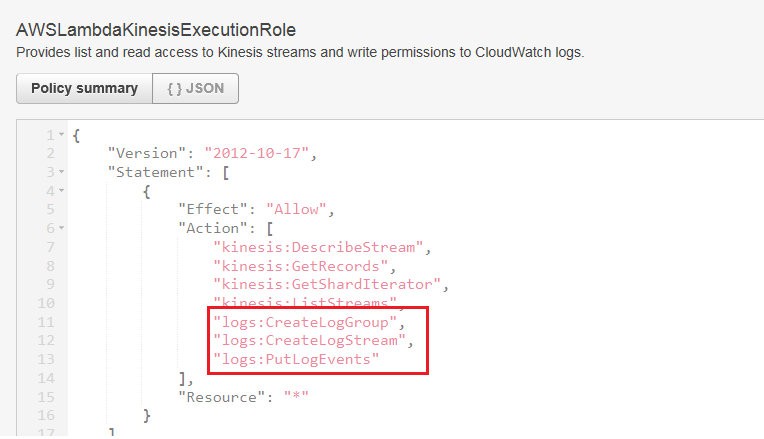 - Option C is not correct. AWS CloudTrail is used for logging API calls made to services such as AWS
Lambda, AWS S3 etc.
AWS CloudWatch for Lambda is used for execution logging.
- Option C is not correct. AWS CloudTrail is used for logging API calls made to services such as AWS
Lambda, AWS S3 etc.
AWS CloudWatch for Lambda is used for execution logging.
 - Option C is incorrect because it is clearly mentioned in the question that the company is focused
on
looking for ways that can reduce the latency for their customers and serve the data securely. This
means that we can’t disable encryption to resolve the latency issues.
- Option D is incorrect because the given statement is false. The truth is, AWS KMS has been
strictly
isolated to a single AWS Region for each implementation, with no sharing of keys, policies, or
audit
information across Regions.
- Option C is incorrect because it is clearly mentioned in the question that the company is focused
on
looking for ways that can reduce the latency for their customers and serve the data securely. This
means that we can’t disable encryption to resolve the latency issues.
- Option D is incorrect because the given statement is false. The truth is, AWS KMS has been
strictly
isolated to a single AWS Region for each implementation, with no sharing of keys, policies, or
audit
information across Regions.

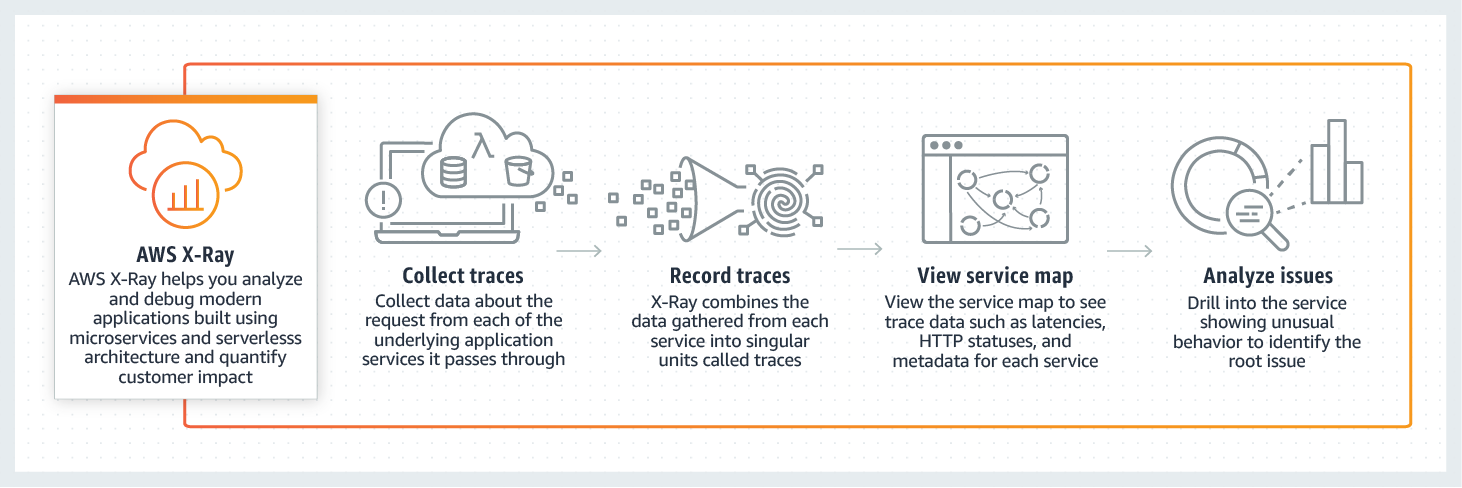
 - Option B is incorrect because a Site-to-Site VPN connection would be more appropriate in case of
hybrid environments where you want to connect AWS and on-premises networks. Here, we just have two
AWS services that need to communicate without the internet.
- Option C is incorrect. Although using the VPC Endpoint indicates the correct solution, the type of
interface mentioned is incorrect. For AWS Secrets Manager, the Gateway endpoint is
unavailable.
- Option D is incorrect because NAT Gateway is more appropriate for communicating privately with
other
VPCs or on-premises environments. This is more expensive. Mostly it is used when your private
subnet
resources want to communicate one way (only outbound) with the Internet. Here in this question, we
just have the EC2 instance that needs to communicate securely without the internet with AWS
Secrets
Manager which resides outside VPC. That’s why using a VPC Endpoint would satisfy the
requirement.
- Option B is incorrect because a Site-to-Site VPN connection would be more appropriate in case of
hybrid environments where you want to connect AWS and on-premises networks. Here, we just have two
AWS services that need to communicate without the internet.
- Option C is incorrect. Although using the VPC Endpoint indicates the correct solution, the type of
interface mentioned is incorrect. For AWS Secrets Manager, the Gateway endpoint is
unavailable.
- Option D is incorrect because NAT Gateway is more appropriate for communicating privately with
other
VPCs or on-premises environments. This is more expensive. Mostly it is used when your private
subnet
resources want to communicate one way (only outbound) with the Internet. Here in this question, we
just have the EC2 instance that needs to communicate securely without the internet with AWS
Secrets
Manager which resides outside VPC. That’s why using a VPC Endpoint would satisfy the
requirement.

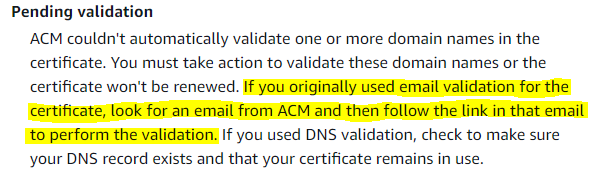 Options B and D are incorrect because the certificate hasn’t expired yet. They are valid for 395
days (13 months). Moreover, you do not need to write any email to AWS support to renew the
certificate. It happens automatically (in DNS Validation) or with a small manual action (in Email
Validation).
- Option C is incorrect. Although the root cause is true as the certificate is expiring soon, the
resolution specified is wrong. The question explicitly says that the domain ownership was
validated
using email. In the case of Email Validation, the domain owner needs to perform an action
manually.
ACM renews the certificate automatically only in case of DNS Validated domain ownership.
Options B and D are incorrect because the certificate hasn’t expired yet. They are valid for 395
days (13 months). Moreover, you do not need to write any email to AWS support to renew the
certificate. It happens automatically (in DNS Validation) or with a small manual action (in Email
Validation).
- Option C is incorrect. Although the root cause is true as the certificate is expiring soon, the
resolution specified is wrong. The question explicitly says that the domain ownership was
validated
using email. In the case of Email Validation, the domain owner needs to perform an action
manually.
ACM renews the certificate automatically only in case of DNS Validated domain ownership.
 - Option C is incorrect. Although Amazon SQS and Step Functions both help in some sort of
orchestration, Step Functions is more relevant here. Amazon SQS doesn’t have the capability to let
you track all the tasks and events of your application. If you want this functionality, you must
build it yourself. The question says you do not want the additional overhead of building this
manually. That’s why we can eliminate Amazon SQS.
- Option C is incorrect. Although Amazon SQS and Step Functions both help in some sort of
orchestration, Step Functions is more relevant here. Amazon SQS doesn’t have the capability to let
you track all the tasks and events of your application. If you want this functionality, you must
build it yourself. The question says you do not want the additional overhead of building this
manually. That’s why we can eliminate Amazon SQS.
 - Option D is incorrect. AWS Glue is a service mainly used to orchestrate your ETL (
Extract-Transform-Load) workloads. You can create a workflow in AWS Glue, but the main purpose
will
be to extract, transform and load jobs. This is not needed in the current scenario. In fact, here
we
need a solution to orchestrate the steps performed by our architecture components.
- Option D is incorrect. AWS Glue is a service mainly used to orchestrate your ETL (
Extract-Transform-Load) workloads. You can create a workflow in AWS Glue, but the main purpose
will
be to extract, transform and load jobs. This is not needed in the current scenario. In fact, here
we
need a solution to orchestrate the steps performed by our architecture components.
 Options A and D are incorrect because AWS ECS uses EC2 instances with ECS-optimized AMI. You will
have root access to the instances and you can manage them.
- Option C is incorrect as it is just a distractor, there is no need for a support team.
Options A and D are incorrect because AWS ECS uses EC2 instances with ECS-optimized AMI. You will
have root access to the instances and you can manage them.
- Option C is incorrect as it is just a distractor, there is no need for a support team.
 Refer to page 616 on the below link:
Refer to page 616 on the below link:
 References:
References:
 - Option D is incorrect because Customer managed keys are KMS keys in an AWS account that the
customer
creates, owns, and manages. The customer has full control over these KMS keys, including
establishing and maintaining their key policies, IAM policies, grants, etc. Customer-managed keys
do
not support digital signature verification.
- Option D is incorrect because Customer managed keys are KMS keys in an AWS account that the
customer
creates, owns, and manages. The customer has full control over these KMS keys, including
establishing and maintaining their key policies, IAM policies, grants, etc. Customer-managed keys
do
not support digital signature verification.
 - Option D is incorrect because Customer managed keys are the KMS keys in an AWS account that is
created, owned, and managed by the customer. Based on the question, the Customer does not want to
take any ownership or manage the data security. Hence, this option is ruled out.
- Option D is incorrect because Customer managed keys are the KMS keys in an AWS account that is
created, owned, and managed by the customer. Based on the question, the Customer does not want to
take any ownership or manage the data security. Hence, this option is ruled out.
 - Option A is incorrect as AWS Migration Hub API can be used to track the migration activity
performed
by each of these tools. This API cannot be used to migrate SQL Server from on-premises to
AWS.
- Option C is incorrect as AWS DataSync can be used to migrate data from on-premises to one of the
AWS
storage services. This service cannot be used to migrate SQL Server from on-premises to AWS.
- Option D is incorrect as AWS Application Discovery Service helps plan cloud migration by gathering
information about the on-premises data centers.
- Option A is incorrect as AWS Migration Hub API can be used to track the migration activity
performed
by each of these tools. This API cannot be used to migrate SQL Server from on-premises to
AWS.
- Option C is incorrect as AWS DataSync can be used to migrate data from on-premises to one of the
AWS
storage services. This service cannot be used to migrate SQL Server from on-premises to AWS.
- Option D is incorrect as AWS Application Discovery Service helps plan cloud migration by gathering
information about the on-premises data centers.